# 核心概念
# 部署架构
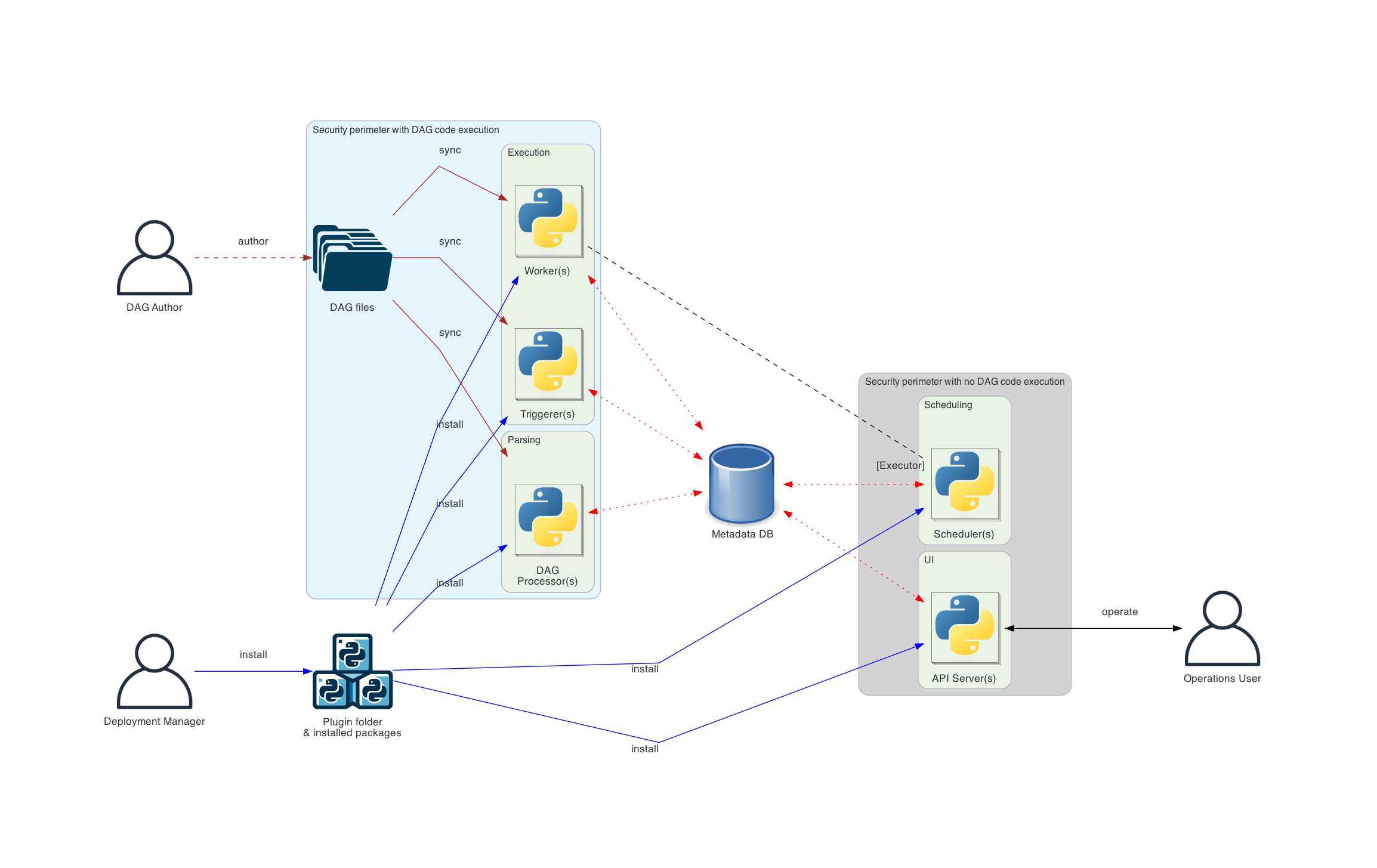
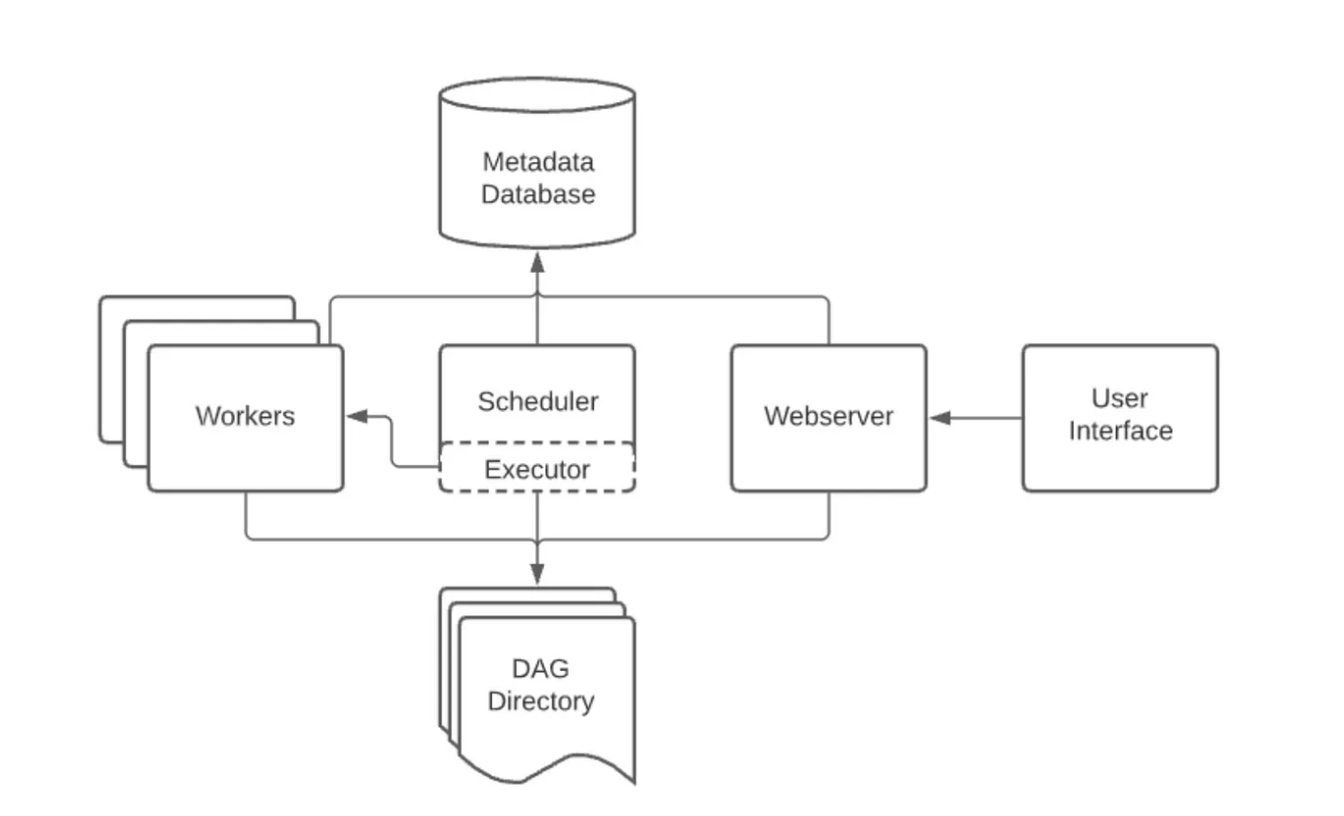
下面是 Airflow 的分布式部署架构,其中 Airflow 的组件分布在多台机器上,并引入了各种用户角色 - Deployment Manager、DAG Author、Operations User。
在分布式部署的情况下,Airflow考虑了组件的安全性。 其中,Webserver无法直接访问 DAG 文件。 UI 的“代码”选项卡中的代码是从Metadata DB中读取的。网络服务器无法执行 DAG Author提交的任何代码。它只能执行由部署管理器作为安装包或插件安装的代码。Operations User只能访问 UI,并且只能触发 DAG 和任务,但无法创作 DAG。
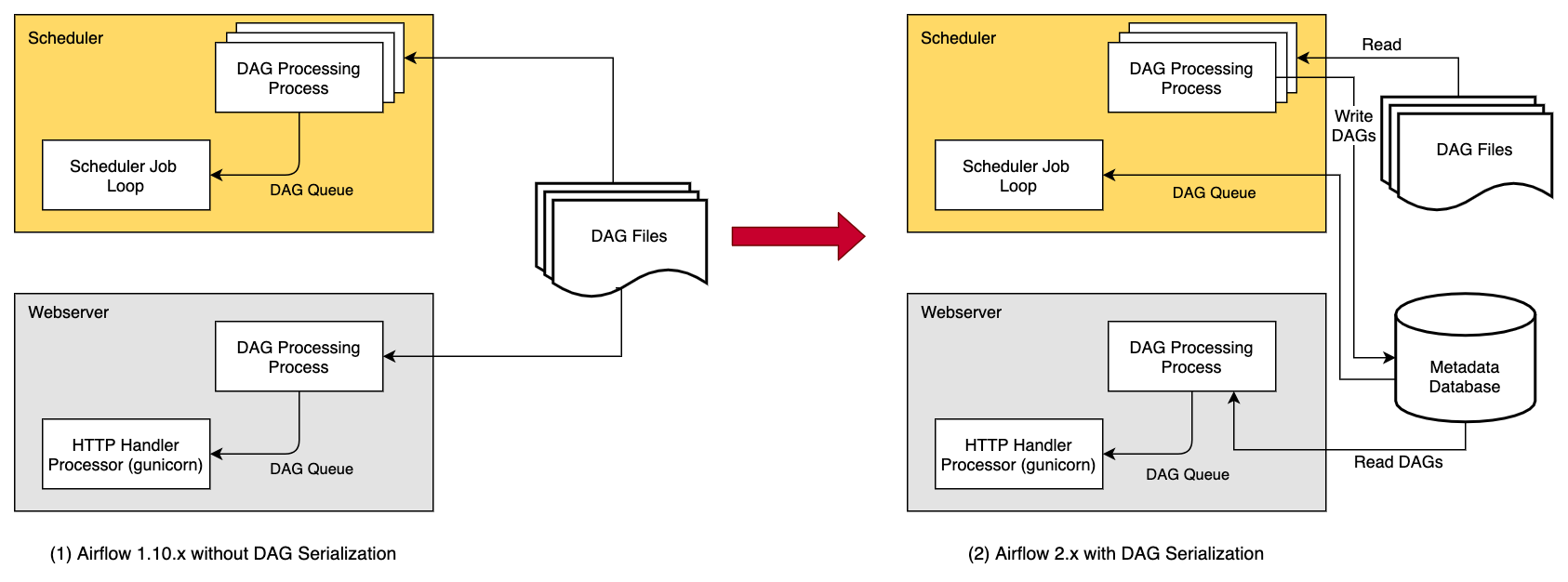
DAG 文件需要在使用它们的所有组件(scheduler、trigger和workers)之间进行同步。 DAG Processor组件是独立的,该组件允许将Scheduler与访问 DAG 文件分开。如果部署重点是解析的任务之间的隔离,那么这是合适的。虽然 Airflow 尚不支持完整的多租户功能,但它可用于确保 DAG Author提供的代码永远不会在Scheduler的上下文中执行。
# DAG
Airflow中的工作流由一组有向无环图DAG(Directed Acyclic Graph)表示,其中节点表示任务(Task),边表示任务之间的依赖关系。DAG定义了任务的执行顺序和依赖关系,以确保工作流程按照预期的逻辑执行。如上图所示,这些DAG定义存储在DAG目录中,Airflow会定期去扫描。
如下是一个简单的DAG定义,DAG定义本身就是一个python文件。
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
# 定义DAG参数
dag_args = {
'owner': 'airflow',
'start_date': datetime(2021, 1, 1),
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
# 创建DAG实例
dag = DAG(
dag_id='my_example_dag',
default_args=dag_args,
description='A simple example DAG',
schedule_interval=timedelta(days=1),
)
# 定义任务
task_1 = DummyOperator(
task_id='task_1',
dag=dag,
)
task_2 = DummyOperator(
task_id='task_2',
dag=dag,
)
# 定义任务依赖关系(指定执行顺序:先task_1,再task_2)
task_1 >> task_2
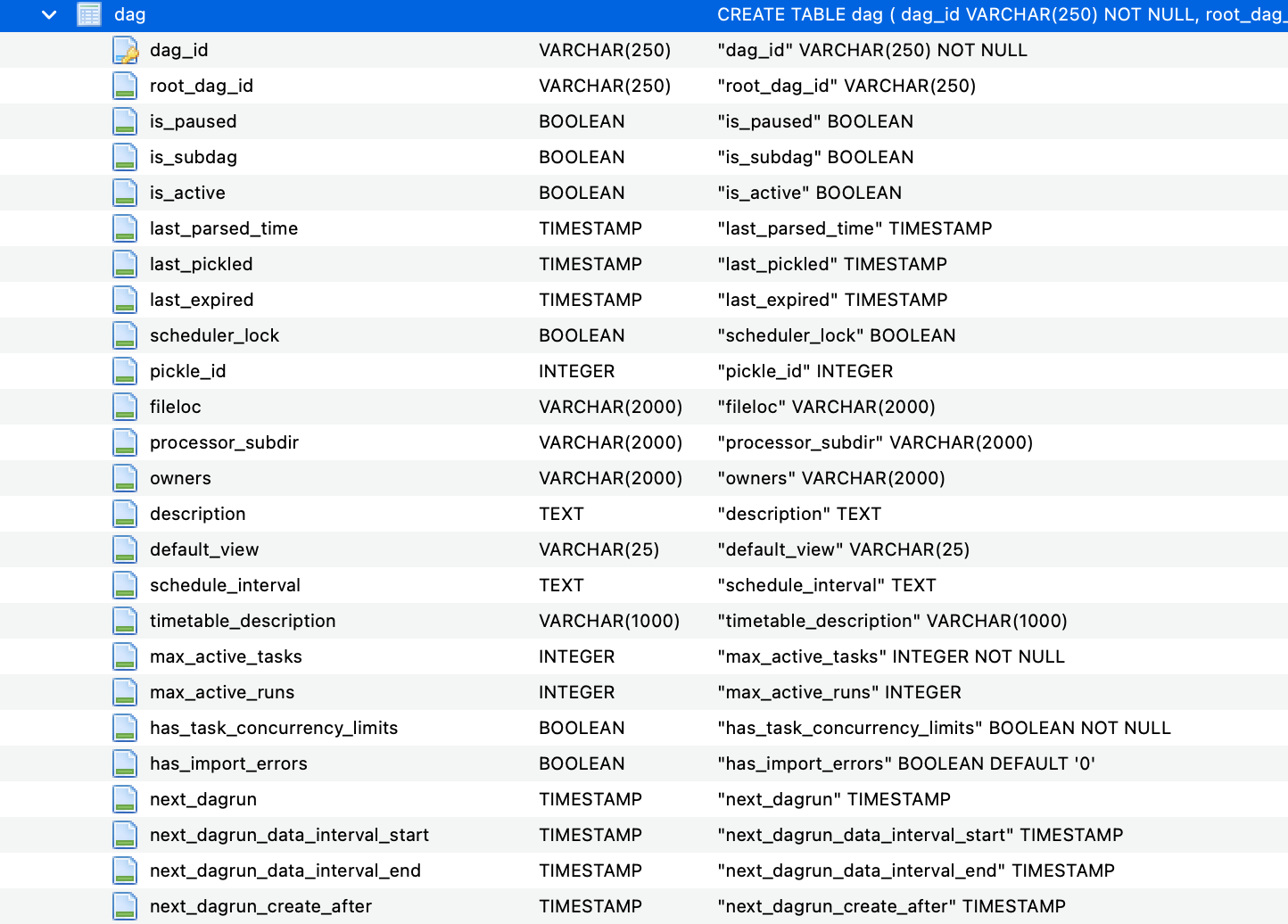
如下是airflow中dag的表定义:
# DagRun
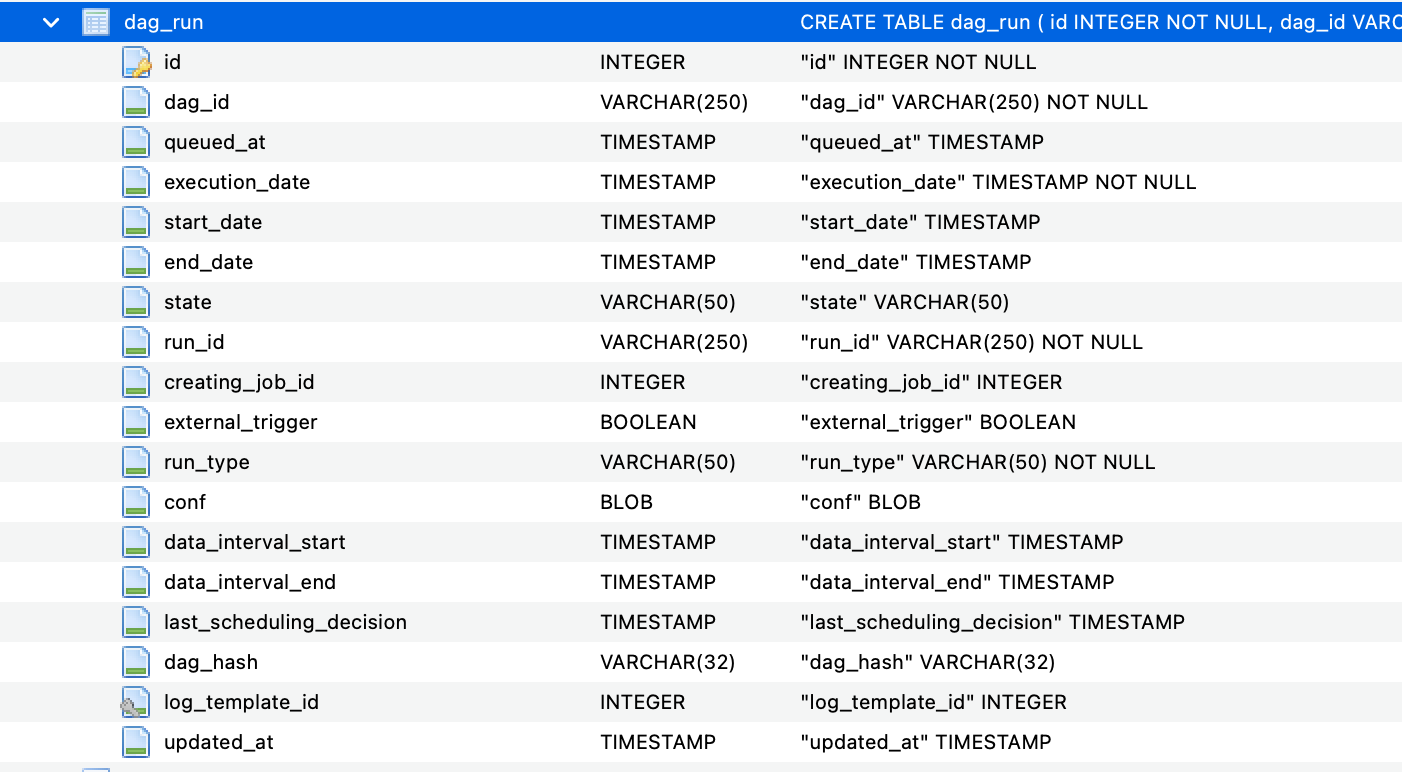
Dag的一次运行,即工作流实例。如下所示是Dag Run的表定义,可以看到其中包含了Dag主键ID。
# Task
Task任务是Airflow的Dag定义中的基本执行单元,相当于工作流中的一个节点。任务被排列成 DAG,然后在它们之间设置上游和下游依赖关系,以表达它们应该运行的顺序。
Task任务分为三种基本类型:
Operators:预定义任务模板,可以将它们快速串联起来以构建 DAG 的大部分。
Sensors:是操作员的一个特殊子类,完全用于等待外部事件发生。
TaskFlow:修饰的@task,它是一个打包为Task的自定义Python函数。
在内部,这些实际上都是 Airflow BaseOperator 的子类,Task和Operator的概念在某种程度上可以互换,但将它们视为单独的概念很有用 - 本质上,Operators和Sensors是模板,当您在 DAG 文件中调用其中一个时,你正在做一个任务。
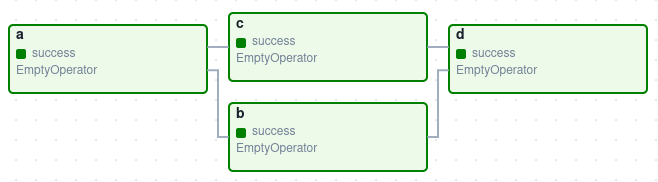
在Dag中不同Task之间一般有先后的顺序关系。例如下面的Dag中包含了两个Task。
with DAG('my_example_dag', start_date=datetime(2021, 1, 1)) as dag:
task_1 = DummyOperator('task_1')
task_2 = DummyOperator('task_2')
task_1 >> task_2
除了用位操作符表示顺序关系,也可以通过set_upstream和set_downstream方法:
task_1.set_downstream(task_2)
# TaskInstance
TaskInstance是DagRun下面的一个任务实例,表示某个Task任务的一次运行。对于每个DagRun实例,Operator都将转换成对应的TaskInstance。
如下图是TaskInstance的表定义:
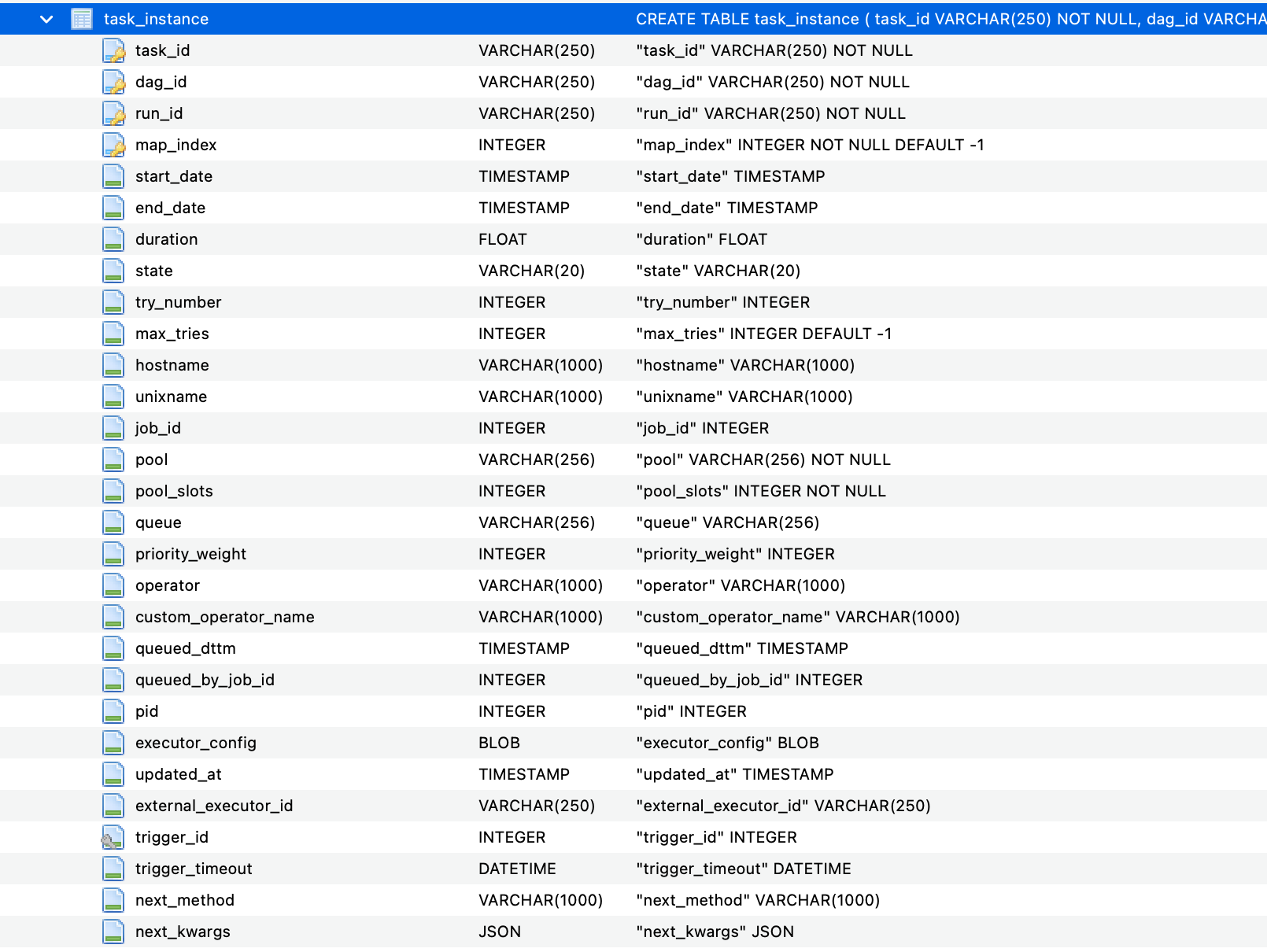
TaskInstance有如下一些状态:
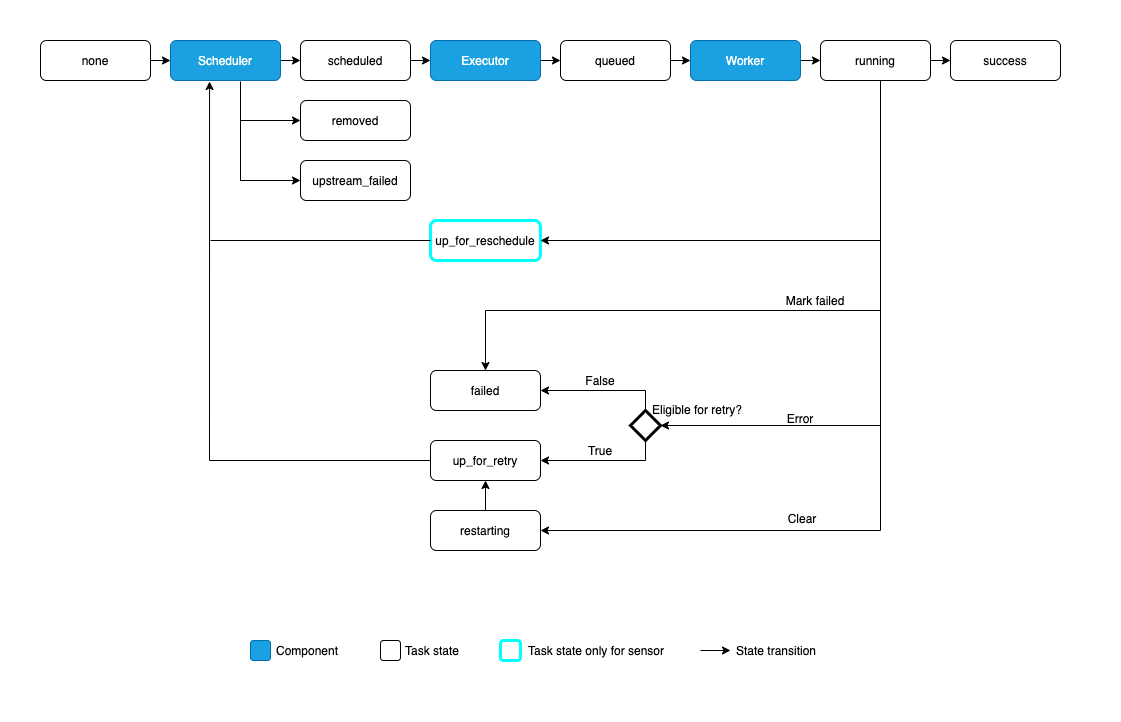
none: 任务尚未排队执行(其依赖项尚未满足)
scheduled: 调度程序已确定任务的依赖项已满足,应该运行
queued: 任务已分配给执行器,正在等待worker
running: 任务正在worker上运行(或在本地/同步执行器上运行)
success: 任务已成功运行而没有错误
restarting: 任务在运行时被外部请求重新启动
failed: 任务在执行过程中出现错误,无法运行
skipped: 任务被跳过。
upstream_failed: 上游任务失败,触发规则表示需要它
up_for_retry: 任务失败,但还有重试尝试,并将被重新安排。
up_for_reschedule: 任务是处于重新安排模式的Sensor
deferred: 任务已推迟到触发器
removed: 由于运行开始,任务已从DAG中消失
其状态流转如下图所示:
# Operators
Airflow提供了一组预定义的操作符(Operator),用于创建和执行任务。操作符是Python类,可以用于实例化任务并定义任务的执行逻辑。其中内置了一下一些常用的Operator:
BashOperator- 执行bash命令PythonOperator- 调用python函数EmailOperator- 发送邮件
如下在DAG中使用预定义的Operator声明Task任务:
with DAG("my-dag") as dag:
ping = SimpleHttpOperator(endpoint="http://example.com/update/")
email = EmailOperator(to="admin@example.com", subject="Update complete")
ping >> email
# Sensors
传感器是一种特殊类型的Operator,旨在完成一件事 - 等待某些事情发生。它可以是基于时间的,或者等待文件或外部事件,但它们所做的只是等到事情发生,然后成功,以便下游任务可以运行。
其中内置了一些常用的Sensor,例如:BashSensor、PythonSensor、DateTimeSensor等。
# Scheduler
Airflow中的调度器(Scheduler)负责根据DAG的定义和调度时间,触发任务的执行。调度器会周期性地检查DAG,并在满足调度条件时创建任务实例(Task Instance)并将其提交给执行器(Executor)。从下图的架构可以知道调度器是Airflow工作流引擎的核心组件。
# Executor
执行器(Executor)负责执行任务实例(Task Instance)。Airflow支持多种执行器,如LocalExecutor(本地执行器)、CeleryExecutor(基于Celery的分布式执行器)、KubernetesExecutor(基于Kubernetes的执行器)等。执行器可以根据任务的需求分配资源,并处理任务的并发和故障恢复。
可以通过下面的命令查看当前使用的Executor类型:
airflow config get-value core executor
SequentialExecutor
# Workers
实际执行任务的进程,由Executor确定。
# XComs
XCom(跨任务通信)是一种机制,允许任务之间交换数据。XCom是存储在Airflow元数据数据库中的键值对,每个XCom都与一个特定的任务实例和执行日期相关联。任务可以通过XCom将数据推送(push)到数据库中,以便其他任务可以在稍后拉取(pull)这些数据。
以下是一个简单的示例,说明了如何在Airflow任务之间使用XCom传递数据:
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
def push_function(**kwargs):
value_to_push = "Hello, XCom!"
kwargs['ti'].xcom_push(key='my_key', value=value_to_push)
def pull_function(**kwargs):
value_to_pull = kwargs['ti'].xcom_pull(key='my_key', task_ids='push_task')
print(f"Pulled value: {value_to_pull}")
with DAG(dag_id='xcom_example_dag', start_date=datetime(2021, 1, 1), schedule_interval=None) as dag:
push_task = PythonOperator(
task_id='push_task',
python_callable=push_function,
provide_context=True
)
pull_task = PythonOperator(
task_id='pull_task',
python_callable=pull_function,
provide_context=True
)
push_task >> pull_task
在这个示例中,我们创建了一个简单的DAG,包含两个PythonOperator任务:push_task和pull_task。push_task任务调用push_function,将一个字符串值("Hello, XCom!")推送到XCom中,键名为my_key。pull_task任务调用pull_function,从XCom中拉取键名为my_key的值,并将其打印出来。
注意,在这个示例中,我们将provide_context=True设置为任务的参数,以便将任务实例(ti)和其他上下文信息传递给push_function和pull_function。
XCom 与Variables相对,主要区别在于 XCom 是针对每个任务实例的,专为 DAG 运行中的通信而设计,而 Variables 是全局的,专为整体配置和价值共享而设计。
# Variables
Variable是一种在DAG中存储和管理全局配置信息的机制。Variable允许你在Airflow元数据数据库中存储键值对,这些键值对可以在整个DAG中的任务之间共享。使用Variable可以帮助你将配置信息与任务代码分离,从而使DAG更易于维护和扩展。
以下是一个简单的示例,说明了如何在Airflow任务中使用Variable:
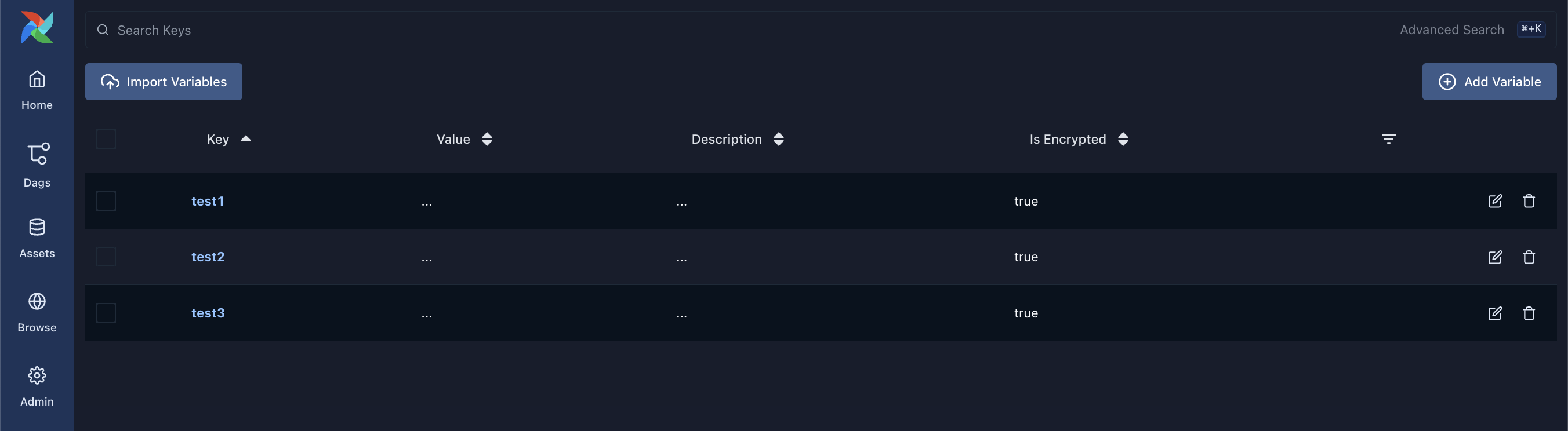
首先,在Airflow Web UI的Admin菜单中,进入Variables页面。点击“创建”按钮,创建一个新的变量,例如键名为example_key,值为example_value。
然后,在DAG中使用这个变量:
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.models import Variable
from datetime import datetime
def print_variable(**kwargs):
example_value = Variable.get("example_key")
print(f"Variable 'example_key': {example_value}")
with DAG(dag_id='variable_example_dag', start_date=datetime(2021, 1, 1), schedule_interval=None) as dag:
print_variable_task = PythonOperator(
task_id='print_variable_task',
python_callable=print_variable,
provide_context=True
)
在这个示例中,我们创建了一个简单的DAG,包含一个PythonOperator任务:print_variable_task。这个任务调用print_variable函数,从Variable中获取键名为example_key的值,并将其打印出来。
注意,我们使用Variable.get()方法从Airflow的变量中获取值。这个方法接受一个键名作为参数,并返回与该键名关联的值。
# Metadata Database
Airflow使用元数据数据库(Metadata Database)来存储DAG的定义、任务实例的状态、调度历史等信息。元数据数据库可以是关系型数据库(如PostgreSQL、MySQL等)或其他兼容的存储系统。通过元数据数据库,Airflow可以实现对任务实例的持久化存储和状态管理。
注意:DAG的持久化存储是从2.x版本开始。
# Web Server
Airflow提供了一个Web服务器,用于展示工作流程的状态、任务实例的执行情况、任务日志等信息。用户可以通过Web界面监控和管理工作流程,以及手动触发任务、重试失败的任务等。
# 核心类和方法
Apache Airflow是一个用于编排、调度和监控复杂数据管道的工具。其核心概念是基于Directed Acyclic Graph (DAG)算法实现的。以下是一些与Airflow DAG相关的核心函数和类:
Dag:定义DAG的主要类。它包含了DAG的所有基本属性,如dag_id、start_date、schedule_interval等。BaseOperator:所有Airflow任务都是从这个基类派生的。这个类包含了任务的基本属性和方法,如task_id、retries、execute()等。这个类是抽象的,不应该被实例化。实例化从此类派生的类会导致创建一个任务对象,该对象最终成为 DAG 对象中的一个节点。同时,使用 set_upstream 或 set_downstream 方法设置任务依赖关系。例如下面几种常见的Operator:
PythonOperator:用于执行Python函数的操作符。BranchOperator:用于在DAG中实现条件分支的操作符。它根据提供的Python可调用对象的返回值来选择要执行的分支。SubDagOperator:用于将一个子DAG嵌套到另一个DAG中的操作符。
TaskInstance:表示任务实例。它包含了任务实例的状态、执行时间、重试次数等信息。DagBag:用于存储和管理所有DAG的容器。它提供了一些方法来查找和操作DAG。DagRun:表示DAG运行的类。它包含了DAG运行的状态、执行时间、外部触发等信息。SchedulerJob:负责调度和执行DAG的类。它包含了一些核心方法,如_process_dags()、_execute_task_instances()等。
# 核心调度流程
Airflow的从DAG文件的定义,到DAG调度,以及任务的执行,其整体调度流程如下所示:
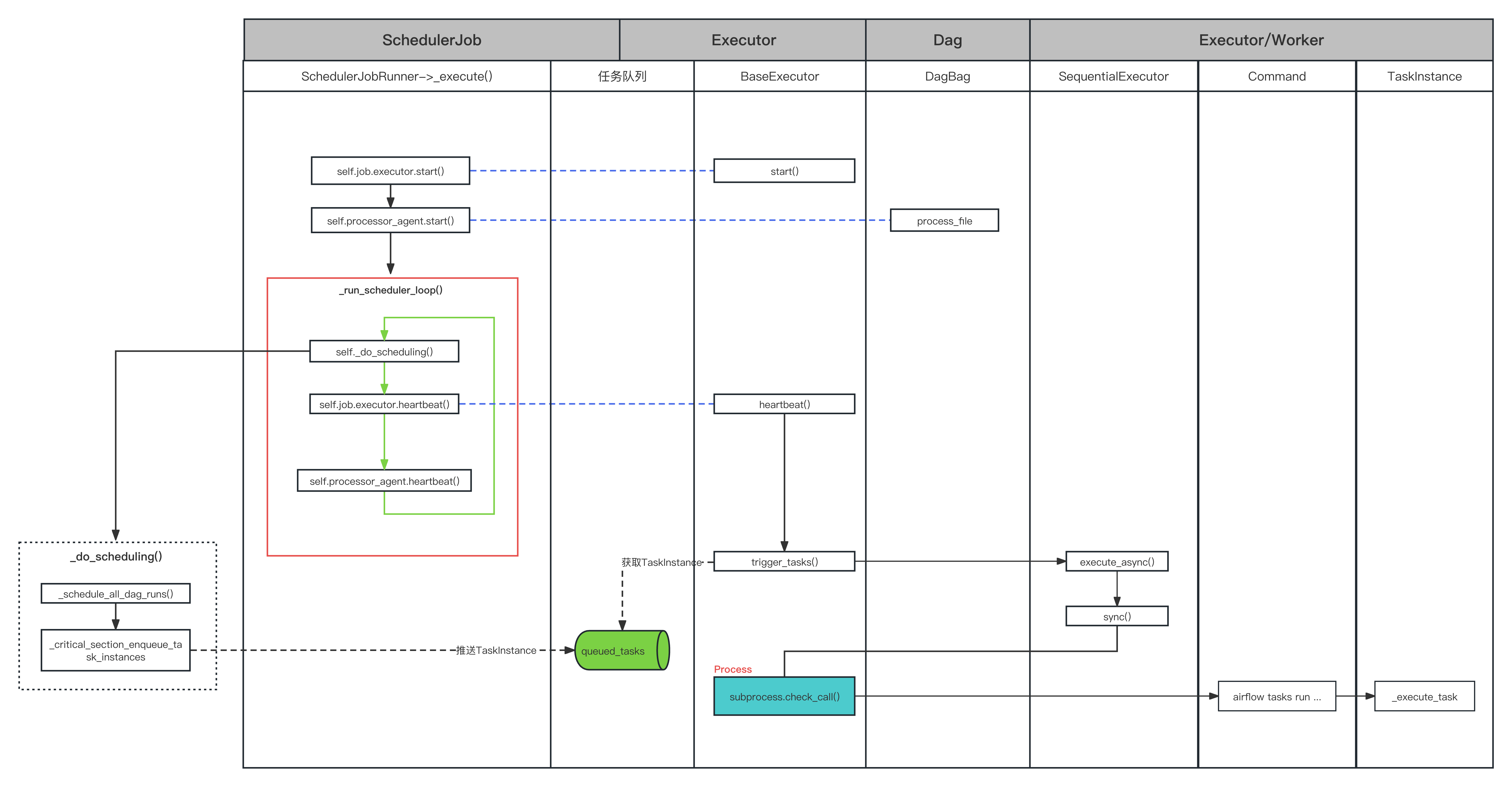
注意:下面所有源码基于的airflow版本是:2.x。
# 1、启动Scheduler调度器
main
在安装好python环境后,我们通过如下pip命令安装airflow
pip install apache-airflow
# 初始化数据库
airflow db init
安装成功后可以看到airflow版本:
airflow version
2.7.2
我们可以查看airflow支持的命令行参数,其中的scheduler命令就是我们需要关注的airflow调度器。
airflow -help
Usage: airflow [-h] GROUP_OR_COMMAND ...
Positional Arguments:
GROUP_OR_COMMAND
Groups
config View configuration
connections Manage connections
dags Manage DAGs
db Database operations
jobs Manage jobs
pools Manage pools
providers Display providers
roles Manage roles
tasks Manage tasks
users Manage users
variables Manage variables
Commands:
cheat-sheet Display cheat sheet
dag-processor Start a standalone Dag Processor instance
info Show information about current Airflow and environment
kerberos Start a kerberos ticket renewer
plugins Dump information about loaded plugins
rotate-fernet-key
Rotate encrypted connection credentials and variables
scheduler Start a scheduler instance
standalone Run an all-in-one copy of Airflow
sync-perm Update permissions for existing roles and optionally DAGs
triggerer Start a triggerer instance
version Show the version
webserver Start a Airflow webserver instance
Options:
-h, --help show this help message and exit
airflow command error: argument -h/--help: ignored explicit argument 'elp', see help above.
备注:如果想要快速方便去调试观察Airflow的运行流程,可以使用上面的airflow standalone命令一键部署所有服务。
运行webserver服务,成功运行后显示如下日志,默认是8080端口。
airflow webserver
[2023-11-02T12:51:52.192+0800] {configuration.py:2067} INFO - Creating new FAB webserver config file in: /Users/shuwoom/Desktop/airflow/webserver_config.py
____________ _____________
____ |__( )_________ __/__ /________ __
____ /| |_ /__ ___/_ /_ __ /_ __ \_ | /| / /
___ ___ | / _ / _ __/ _ / / /_/ /_ |/ |/ /
_/_/ |_/_/ /_/ /_/ /_/ \____/____/|__/
Running the Gunicorn Server with:
Workers: 4 sync
Host: 0.0.0.0:8080
Timeout: 120
Logfiles: - -
Access Logformat:
=================================================================
创建一个管理员账号:
airflow users create --username airflow --role Admin --email test@qq.com --firstname admin --lastname admin --password airflow
访问上述地址,就进入到airflow的web管理页面。
通过如下命令,我们可以运行scheduler调度器,运行成功后打印如下日志。
airflow scheduler
[2023-11-02T13:00:46.811+0800] {migration.py:213} INFO - Context impl SQLiteImpl.
[2023-11-02T13:00:46.812+0800] {migration.py:216} INFO - Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running stamp_revision -> 405de8318b3a
WARNI [airflow.models.crypto] empty cryptography key - values will not be stored encrypted.
DB initialize done
____________ _____________
____ |__( )_________ __/__ /________ __
____ /| |_ /__ ___/_ /_ __ /_ __ \_ | /| / /
___ ___ | / _ / _ __/ _ / / /_/ /_ |/ |/ /
_/_/ |_/_/ /_/ /_/ /_/ \____/____/|__/
[2023-11-02 13:00:47 +0800] [55179] [INFO] Starting gunicorn 21.2.0
[2023-11-02 13:00:47 +0800] [55179] [INFO] Listening at: http://[::]:8793 (55179)
[2023-11-02 13:00:47 +0800] [55179] [INFO] Using worker: sync
[2023-11-02 13:00:47 +0800] [55181] [INFO] Booting worker with pid: 55181
而airflow命令行参数的入口正是下面的main函数,通过传递scheduler命令启动airflow的调度器服务。
# main入口
main 函数的主要目的是解析命令行参数,并根据解析后的参数执行相应的 Airflow 命令。在执行命令之前,它还确保了默认配置文件已经写入磁盘。
以下是该函数的功能说明:
文件路径:airflow/_main_.py
def main():
# 1.从 Airflow 配置文件中获取配置对象 conf。
conf = configuration.conf
# 2.如果配置文件中的 core.security 设置为 "kerberos",则从配置文件中读取 Kerberos 相关的设置(如 ccache 和 keytab),并将它们设置为环境变量。
if conf.get("core", "security") == "kerberos":
os.environ["KRB5CCNAME"] = conf.get("kerberos", "ccache")
os.environ["KRB5_KTNAME"] = conf.get("kerberos", "keytab")
# 3.调用 cli_parser.get_parser() 函数创建一个命令行参数解析器。
parser = cli_parser.get_parser()
# 4.使用 argcomplete.autocomplete(parser) 为解析器启用自动补全功能。
argcomplete.autocomplete(parser)
# 5.解析命令行参数,并将结果存储在 args 变量中。
args = parser.parse_args()
# 6.如果子命令不是 "lazy_loaded" 或 "version",则执行以下操作:
if args.subcommand not in ["lazy_loaded", "version"]:
# 7.调用 write_default_airflow_configuration_if_needed 函数,确保在运行任何可能需要默认配置的命令之前,将默认配置文件写入磁盘(如果需要的话)。
from airflow.configuration import write_default_airflow_configuration_if_needed
conf = write_default_airflow_configuration_if_needed()
# 8.如果子命令是 "webserver"、"internal-api" 或 "worker",则调用 write_webserver_configuration_if_needed 函数,确保在运行这些命令之前,将 Web 服务器的默认配置文件写入磁盘(如果需要的话)。
if args.subcommand in ["webserver", "internal-api", "worker"]:
write_webserver_configuration_if_needed(conf)
args.func(args)
if __name__ == "__main__":
main()
这里会加载Airflow配置文件,Airflow 配置文件(默认为 airflow.cfg)包含了许多配置参数,这些参数被分为不同的节(sections)。以下是一些主要的节和它们的部分参数:
[core]:核心配置参数。
dags_folder:DAG 文件的存放路径。load_examples:是否加载示例 DAG。executor:使用的执行器类型,如SequentialExecutor、LocalExecutor或CeleryExecutor,默认是SequentialExecutor。sql_alchemy_conn:用于连接元数据库的 SQL Alchemy 连接字符串。parallelism:允许的最大并行任务数。
接下来展开分析get_parser函数。
# get_parser函数
get_parser 函数的主要目的是创建一个命令行参数解析器,用于解析 Airflow 命令行工具中的命令和参数。
以下是该函数的功能说明:
文件路径:airflow/airflow/cli/cli_parser.py
# 这里的core_commands包含了scheduler命令,见下面介绍
airflow_commands = core_commands.copy()
...
ALL_COMMANDS_DICT: dict[str, CLICommand] = {sp.name: sp for sp in airflow_commands}
def get_parser(dag_parser: bool = False) -> argparse.ArgumentParser:
"""Create and returns command line argument parser."""
# 1.创建一个名为 airflow 的 argparse.ArgumentParser 实例,使用自定义的帮助解析器 DefaultHelpParser 和格式化类 AirflowHelpFormatter。
parser = DefaultHelpParser(prog="airflow", formatter_class=AirflowHelpFormatter)
# 2.为解析器添加子解析器(subparsers),用于处理子命令(如 airflow scheduler 中的 scheduler)。设置子解析器的目标属性为 "subcommand",元变量为 "GROUP_OR_COMMAND"。这样,在解析命令行参数时,子命令将被存储在 args.subcommand 属性中。
subparsers = parser.add_subparsers(dest="subcommand", metavar="GROUP_OR_COMMAND")
# 3.设置 subparsers.required 为 True,表示必须提供一个子命令。
subparsers.required = True
# 4.根据 dag_parser 参数的值,选择要添加的命令字典。如果 dag_parser 为 True,则使用 DAG_CLI_DICT,否则使用 ALL_COMMANDS_DICT。
command_dict = DAG_CLI_DICT if dag_parser else ALL_COMMANDS_DICT
for _, sub in sorted(command_dict.items()):
# 5.遍历命令字典,将每个命令添加到子解析器中。这是通过调用 _add_command 函数完成的,它将命令的名称、帮助文本、参数等信息添加到子解析器中。
_add_command(subparsers, sub)
# 6.返回创建好的解析器实例。
return parser
接下来展开分析scheduler命令。
# scheduler命令
下面这段代码定义了一个名为 core_commands 的列表,其中包含了 Airflow 命令行工具的核心命令。这些命令是通过 CLICommand 类的实例表示的。在这个例子中,我们重点关注 scheduler 命令。
scheduler 命令的定义如下:
name: 命令的名称,这里为 "scheduler"。help: 命令的帮助文本,用于描述命令的功能。这里为 "Start a scheduler instance"。func: 命令的实际执行函数。这里使用lazy_load_command函数导入scheduler_command.scheduler函数。lazy_load_command用于在实际需要时才导入命令的执行函数,以减少启动时间。args: 命令支持的命令行参数。这里包括了一系列预定义的参数,如ARG_SUBDIR(DAG 子目录)、ARG_NUM_RUNS(调度器运行次数)等。epilog: 命令的附加帮助信息,用于在命令帮助文本的末尾显示。这里包含了关于scheduler命令支持的信号(如SIGUSR2)的说明。
这个列表中的其他命令也采用类似的结构进行定义。最终,这些命令将被添加到命令行参数解析器中,以便用户在运行 Airflow 命令行工具时可以使用它们。
文件路径:airflow/airflow/cli/cli_config.py
core_commands: list[CLICommand] = [
...
ActionCommand(
name="scheduler",
help="Start a scheduler instance",
func=lazy_load_command("airflow.cli.commands.scheduler_command.scheduler"),
args=(
ARG_SUBDIR,
ARG_NUM_RUNS,
ARG_DO_PICKLE,
ARG_PID,
ARG_DAEMON,
ARG_STDOUT,
ARG_STDERR,
ARG_LOG_FILE,
ARG_SKIP_SERVE_LOGS,
ARG_VERBOSE,
),
epilog=(
"Signals:\n"
"\n"
" - SIGUSR2: Dump a snapshot of task state being tracked by the executor.\n"
"\n"
" Example:\n"
' pkill -f -USR2 "airflow scheduler"'
),
)
...
]
我们可以通过如下的命令开启守护进程启动scheduler服务
airflow scheduler -D
接下来看看这个被调用的scheduler方法。
# scheduler函数
scheduler 函数的主要目的是通过调用 run_command_with_daemon_option 函数来启动 Airflow 调度器。
以下是该函数的功能说明:
文件路径:airflow/airflow/cli/commands/scheduler_command.py
def scheduler(args: Namespace):
"""Start Airflow Scheduler."""
print(settings.HEADER)
# 启动调度器作业
run_command_with_daemon_option(
args=args, # 命令行参数
process_name="scheduler", # 进程名称,设置为 "scheduler"
callback=lambda: _run_scheduler_job(args), # 启动调度器作业的回调函数,这里使用 _run_scheduler_job(args)
should_setup_logging=True, # 是否设置日志记录,设置为 True。
接下来展开分析_run_scheduler_job函数。
# _run_scheduler_job函数
创建SchedulerJob对象,并调用该对象的_execute方法。Airflow就是通过调用_execute方法来启动scheduler调度服务。
_run_scheduler_job 函数的主要目的是创建并运行一个调度器作业,启动日志服务和健康检查服务。
以下是该函数的功能说明:
文件路径:airflow/airflow/cli/commands/scheduler_command.py
def _run_scheduler_job(args) -> None:
# 1.创建一个 SchedulerJobRunner 实例,设置相关参数,如DAG目录(subdir)、最大运行次数(num_runs)和是否进行pickle序列化(do_pickle)。
job_runner = SchedulerJobRunner(
job=Job(), subdir=process_subdir(args.subdir), num_runs=args.num_runs, do_pickle=args.do_pickle
)
# 2.验证执行器与数据库的兼容性。
ExecutorLoader.validate_database_executor_compatibility(job_runner.job.executor)
# 3.强制使用直接访问数据库的方式。
InternalApiConfig.force_database_direct_access()
# 4.从配置文件中获取调度器的健康检查设置(enable_health_check)。
enable_health_check = conf.getboolean("scheduler", "ENABLE_HEALTH_CHECK")
# 5.使用上下文管理器 _serve_logs 和 _serve_health_check 启动日志服务和健康检查服务。
with _serve_logs(args.skip_serve_logs), _serve_health_check(enable_health_check):
try:
# 6.尝试运行调度器作业,将 job_runner._execute 作为执行方法传递给 run_job 函数。
run_job(job=job_runner.job, execute_callable=job_runner._execute)
except Exception:
# 7.如果在运行调度器作业过程中发生异常,记录异常信息。
log.exception("Exception when running scheduler job")
这里我们看到该函数通过传递_execute函数来运行调度器进行作业,下面我们继续展开这个函数进行分析。
# SchedulerJobRunner._execute
它是 Airflow 调度器的核心执行逻辑,包括启动执行器、处理器代理,以及执行调度器循环。
以下是具体的步骤:
从
DagFileProcessorAgent类导入 Dag 文件处理器代理。导入默认执行器类,这里默认使用的是SequentialExecutor。
判断是否需要对 DAGs 进行序列化(pickling),以便某些执行器更容易地进行远程执行。
当使用 SQLite 时,不使用异步模式,以避免调度器工作进程和 DAG 解析器同时访问数据库。
设置 DAG 文件处理器超时时间。
如果没有使用独立的 DAG 处理器并且没有处理器代理,创建一个
DagFileProcessorAgent实例。尝试执行以下操作:
a. 设置执行器的 job ID。
b. 根据是否使用处理器代理,设置执行器的回调接收器(callback sink)。
c. 启动执行器。
d. 注册信号处理器。
e. 如果使用处理器代理,启动处理器代理。
f. 记录调度器循环的开始时间。
g. 执行调度器循环(
_run_scheduler_loop方法)。h. 如果使用处理器代理,停止处理器代理。
i. 如果所有文件都已处理,停用自调度器循环开始以来未被触及的 DAG,因为它们可能已被删除。
j. 移除数据库会话。
如果在执行过程中发生异常,记录异常日志并抛出异常。
在 finally 语句中,尝试结束执行器和处理器代理,并记录日志表示已退出执行循环。
这个方法的返回值为 None。
文件路径:airflow/airflow/jobs/scheduler_job_runner.py
def _execute(self) -> int | None:
from airflow.dag_processing.manager import DagFileProcessorAgent
self.log.info("Starting the scheduler")
executor_class, _ = ExecutorLoader.import_default_executor_cls()
pickle_dags = self.do_pickle and executor_class.supports_pickling
self.log.info("Processing each file at most %s times", self.num_times_parse_dags)
async_mode = not self.using_sqlite
processor_timeout_seconds: int = conf.getint("core", "dag_file_processor_timeout")
processor_timeout = timedelta(seconds=processor_timeout_seconds)
if not self._standalone_dag_processor and not self.processor_agent:
self.processor_agent = DagFileProcessorAgent(
dag_directory=Path(self.subdir),
max_runs=self.num_times_parse_dags,
processor_timeout=processor_timeout,
dag_ids=[],
pickle_dags=pickle_dags,
async_mode=async_mode,
)
try:
self.job.executor.job_id = self.job.id
if self.processor_agent:
self.log.debug("Using PipeCallbackSink as callback sink.")
self.job.executor.callback_sink = PipeCallbackSink(
get_sink_pipe=self.processor_agent.get_callbacks_pipe
)
else:
from airflow.callbacks.database_callback_sink import DatabaseCallbackSink
self.log.debug("Using DatabaseCallbackSink as callback sink.")
self.job.executor.callback_sink = DatabaseCallbackSink()
self.job.executor.start()
self.register_signals()
if self.processor_agent:
self.processor_agent.start()
execute_start_time = timezone.utcnow()
self._run_scheduler_loop()
if self.processor_agent:
self.processor_agent.terminate()
if self.processor_agent.all_files_processed:
self.log.info(
"Deactivating DAGs that haven't been touched since %s", execute_start_time.isoformat()
)
DAG.deactivate_stale_dags(execute_start_time)
settings.Session.remove() # type: ignore
except Exception:
self.log.exception("Exception when executing SchedulerJob._run_scheduler_loop")
raise
finally:
try:
self.job.executor.end()
except Exception:
self.log.exception("Exception when executing Executor.end")
if self.processor_agent:
try:
self.processor_agent.end()
except Exception:
self.log.exception("Exception when executing DagFileProcessorAgent.end")
self.log.info("Exited execute loop")
return None
在这个方法中有3个关键的操作:
self.job.executor.start(): 它调用执行器的start方法,执行器是负责执行任务的组件。在调度器启动时,执行器需要初始化相关资源,如线程、进程或其他分布式资源。具体的实现取决于所使用的执行器类型(如SequentialExecutor,LocalExecutor,CeleryExecutor等)。self.processor_agent.start(): 这个方法调用DagFileProcessorAgent的start方法。DagFileProcessorAgent是负责解析和处理 DAG 文件的组件。它在后台运行,周期性地扫描 DAG 文件目录,解析找到的 DAG 文件并将其更新到数据库中。调用start方法会启动 DAG 文件处理器代理,使其开始工作。self._run_scheduler_loop(): 这个方法是调度器的核心循环,负责处理和调度任务。在这个循环中,调度器会根据任务的依赖关系和状态来决定哪些任务可以执行。然后,它会将这些任务添加到executor的队列中。此外,调度器还会检查已完成的任务并更新它们的状态。这个循环会一直运行,直到调度器被停止。
# 2、DAG定义和任务依赖定义
首先,在文件中定义DAG和任务,然后定义任务之间的依赖关系。前面我们介绍了Dag的定义,下面来介绍依赖关系的定义。
在Airflow中,chain函数、位移操作符>>或<<以及set_upstream和set_downstream方法都可以用于设置任务之间的依赖关系。它们在使用方式和适用场景上有一些区别:
chain函数:这个函数可以接受任意数量的任务作为参数,并在这些任务之间建立一条依赖链。这个函数的一个优点是可以接受任务列表作为参数,这使得可以在多个任务之间建立复杂的依赖关系。例如,chain(t1, [t2, t3], t4)将会创建以下的依赖关系:t1 -> t2 -> t4和t1 -> t3 -> t4。- 位移操作符
>>或<<:这些操作符可以用于设置两个任务之间的依赖关系。例如,t1 >> t2或t2 << t1都表示t1任务执行完后执行t2任务。这种方式的一个优点是语法简洁,易于阅读和理解。但是,它只能用于设置两个任务之间的依赖关系,如果需要设置多个任务之间的依赖关系,就需要多次使用这些操作符,例如:t1 >> t2 >> t3 >> t4。 set_upstream和set_downstream方法:这些方法可以用于设置两个任务之间的上游和下游依赖关系。例如,t1.set_downstream(t2)表示在t1任务执行完后执行t2任务,而t2.set_upstream(t1)表示在t2任务执行前执行t1任务。这种方式的一个优点是可以明确地设置任务之间的依赖关系,但它相对比较繁琐,尤其是在设置多个任务之间的依赖关系时。
例如下面的例子:
op1 -> op2依赖关系的三种写法:
op1 >> op2
op1.set_downstream(op2)
chain(op1, op2)
op2 <- op1依赖关系的三种写法:
op2 << op1
op2.set_upstream(op1)
chain(op1, op2)
总的来说,chain函数、位移操作符>>或<<以及set_upstream和set_downstream方法在设置任务依赖关系时都有各自的优点和适用场景,可以根据实际需要选择使用。
- 官方文档:https://github.com/apache/airflow/blob/1a9b71a1298da76fc254f670e1032fa12131901a/docs/apache-airflow/core-concepts/dags.rst#L128
# chain的四种使用方法
路径:airflow/models/taskmixin.py
class DependencyMixin:
"""Mixing implementing common dependency setting methods like >> and <<."""
@abstractmethod
def set_upstream(
self, other: DependencyMixin | Sequence[DependencyMixin], edge_modifier: EdgeModifier | None = None
):
"""Set a task or a task list to be directly upstream from the current task."""
raise NotImplementedError()
@abstractmethod
def set_downstream(
self, other: DependencyMixin | Sequence[DependencyMixin], edge_modifier: EdgeModifier | None = None
):
"""Set a task or a task list to be directly downstream from the current task."""
raise NotImplementedError()
chain方法通过调用上述两个方法来实现依赖关系的设置,目前chain方法支持下面四种用法:
使用Operators/Sensors:
例如要表达下面的依赖关系:
/ -> t2 -> t4 \
t1 -> t6
\ -> t3 -> t5 /
chain(t1, [t2, t3], [t4, t5], t6)
# 等价于
t1.set_downstream(t2)
t1.set_downstream(t3)
t2.set_downstream(t4)
t3.set_downstream(t5)
t4.set_downstream(t6)
t5.set_downstream(t6)
使用任务修饰函数又名 XComArgs
例如要表达下面的依赖关系:
/ -> t2 -> t4 \
t1 -> t6
\ -> t3 -> t5 /
chain(x1(), [x2(), x3()], [x4(), x5()], x6())
# 等价于:
x1 = x1()
x2 = x2()
x3 = x3()
x4 = x4()
x5 = x5()
x6 = x6()
x1.set_downstream(x2)
x1.set_downstream(x3)
x2.set_downstream(x4)
x3.set_downstream(x5)
x4.set_downstream(x6)
x5.set_downstream(x6)
使用TaskGroups
例如要表达下面的依赖关系:
t1 -> task_group1 -> task_group2 -> t2
chain(t1, task_group1, task_group2, t2)
# 等价于
t1.set_downstream(task_group1)
task_group1.set_downstream(task_group2)
task_group2.set_downstream(t2)
也可以在Operators/Sensors、EdgeModifiers、XComArg 和 TaskGroups 之间进行混合
例如要表达下面的依赖关系:
/ "branch one" -> x1 \
t1 -> task_group1 -> x3
\ "branch two" -> x2 /
chain(t1, [Label("branch one"), Label("branch two")], [x1(), x2()], task_group1, x3())
# 等价于
x1 = x1()
x2 = x2()
x3 = x3()
label1 = Label("branch one")
label2 = Label("branch two")
t1.set_downstream(label1)
label1.set_downstream(x1)
t2.set_downstream(label2)
label2.set_downstream(x2)
x1.set_downstream(task_group1)
x2.set_downstream(task_group1)
task_group1.set_downstream(x3)
# chain源码剖析
该方法用于在给定的多个任务之间建立依赖关系链。它接受一个或多个任务、边缘修饰符、XComArgs 或 TaskGroups 作为参数,并在这些任务之间设置依赖关系。下面是函数的步骤:
- 使用
zip函数将任务列表与其自身的偏移版本配对,这样我们就可以在循环中同时处理上游任务和下游任务。 - 检查上游任务是否是
DependencyMixin类型。如果是,则为上游任务设置下游任务。然后继续下一个任务。 - 检查下游任务是否是
DependencyMixin类型。如果是,则为下游任务设置上游任务。然后继续下一个任务。 - 如果上游任务和下游任务都是
Sequence类型(如列表),则将它们分别赋值给up_task_list和down_task_list。然后检查这两个列表的长度是否相等。如果上游任务和下游任务列表的长度相等,则使用zip函数将它们配对,并在循环中为每对任务设置上游和下游依赖关系。
文件路径:airflow/models/baseoperator.py
def chain(*tasks: DependencyMixin | Sequence[DependencyMixin]) -> None:
r"""
Given a number of tasks, builds a dependency chain.
:param tasks: Individual and/or list of tasks, EdgeModifiers, XComArgs, or TaskGroups to set dependencies
"""
for up_task, down_task in zip(tasks, tasks[1:]):
if isinstance(up_task, DependencyMixin):
up_task.set_downstream(down_task)
continue
if isinstance(down_task, DependencyMixin):
down_task.set_upstream(up_task)
continue
if not isinstance(up_task, Sequence) or not isinstance(down_task, Sequence):
raise TypeError(f"Chain not supported between instances of {type(up_task)} and {type(down_task)}")
up_task_list = up_task
down_task_list = down_task
if len(up_task_list) != len(down_task_list):
raise AirflowException(
f"Chain not supported for different length Iterable. "
f"Got {len(up_task_list)} and {len(down_task_list)}."
)
for up_t, down_t in zip(up_task_list, down_task_list):
up_t.set_downstream(down_t)
下面我们通过airflow源码的官方example来了解其使用方法:
路径:airflow/tests/system/providers/amazon/aws/example_mongo_to_s3.py
from __future__ import annotations
from airflow.models.baseoperator import chain
from airflow.models.dag import DAG
from airflow.providers.amazon.aws.operators.s3 import S3CreateBucketOperator, S3DeleteBucketOperator
from airflow.providers.amazon.aws.transfers.mongo_to_s3 import MongoToS3Operator
from airflow.utils.dates import datetime
from airflow.utils.trigger_rule import TriggerRule
from tests.system.providers.amazon.aws.utils import SystemTestContextBuilder
DAG_ID = "example_mongo_to_s3"
# Externally fetched variables:
MONGO_DATABASE_KEY = "MONGO_DATABASE"
MONGO_COLLECTION_KEY = "MONGO_COLLECTION"
sys_test_context_task = (
SystemTestContextBuilder().add_variable(MONGO_DATABASE_KEY).add_variable(MONGO_COLLECTION_KEY).build()
)
with DAG(
DAG_ID,
schedule="@once",
start_date=datetime(2021, 1, 1),
catchup=False,
tags=["example"],
) as dag:
test_context = sys_test_context_task()
env_id = test_context["ENV_ID"]
mongo_database = test_context[MONGO_DATABASE_KEY]
mongo_collection = test_context[MONGO_COLLECTION_KEY]
s3_bucket = f"{env_id}-mongo-to-s3-bucket"
s3_key = f"{env_id}-mongo-to-s3-key"
create_s3_bucket = S3CreateBucketOperator(task_id="create_s3_bucket", bucket_name=s3_bucket)
# [START howto_transfer_mongo_to_s3]
mongo_to_s3_job = MongoToS3Operator(
task_id="mongo_to_s3_job",
mongo_collection=mongo_collection,
# Mongo query by matching values
# Here returns all documents which have "OK" as value for the key "status"
mongo_query={"status": "OK"},
s3_bucket=s3_bucket,
s3_key=s3_key,
mongo_db=mongo_database,
replace=True,
)
# [END howto_transfer_mongo_to_s3]
delete_s3_bucket = S3DeleteBucketOperator(
task_id="delete_s3_bucket",
bucket_name=s3_bucket,
force_delete=True,
trigger_rule=TriggerRule.ALL_DONE,
)
chain(
# TEST SETUP
test_context,
create_s3_bucket,
# TEST BODY
mongo_to_s3_job,
# TEST TEARDOWN
delete_s3_bucket,
)
from tests.system.utils.watcher import watcher
# This test needs watcher in order to properly mark success/failure
# when "tearDown" task with trigger rule is part of the DAG
list(dag.tasks) >> watcher()
from tests.system.utils import get_test_run # noqa: E402
# Needed to run the example DAG with pytest (see: tests/system/README.md#run_via_pytest)
test_run = get_test_run(dag)
# 3、DAG解析
当Airflow启动时,Scheduler会解析DAG文件并将其添加到DAGBag中。这一过程涉及到DAGBag.process_file方法。
前面启动通过_execute启动调度器的同时,也通过self.processor_agent.start()方法创建DagFileProcessorAgent对象并调用start方法,start方法最终通过调用DagBag.process_file方法实现DAG解析。
下图是函数的调用链:

其中DagBag 类是 Airflow 中的一个核心类,用于从指定的文件系统路径中加载、存储和管理有向无环图(DAG)对象。
# DagBag.process_file
我们接着看 DagBag 类的 process_file 方法。它的作用是处理并加载指定的 DAG 定义文件。以下是该方法的分段解释:
- 首先,检查输入参数
filepath是否为None或者对应的文件是否存在。如果文件不存在,则返回一个空列表。 - 尝试获取文件在磁盘上的最后修改时间。如果
only_if_updated参数为True,并且文件已经在self.file_last_changed字典中记录了最后修改时间,并且磁盘上的最后修改时间与记录的时间相同,则不需要重新加载此文件,直接返回一个空列表。这是为了避免不必要的重复加载。 - 在加载 DAG 定义文件之前,清除
DagContext.autoregistered_dags,以确保不会意外地捕获不需要的 DAG 对象。 - 根据文件类型(Python 文件或 ZIP 文件)调用不同的方法来加载模块。如果文件是以
.py结尾的 Python 文件,或者不是一个 ZIP 文件,则调用_load_modules_from_file方法加载模块。如果文件是一个 ZIP 文件,则调用_load_modules_from_zip方法加载模块。 - 调用
_process_modules方法处理加载的模块,并获取找到的 DAG 对象列表found_dags。这个方法会遍历模块中的所有对象,查找类型为DAG的对象,并将它们添加到DagBag实例中。 - 更新
self.file_last_changed字典,将文件的最后修改时间记录在其中。 - 返回找到的 DAG 对象列表
found_dags。
文件路径:airflow/models/dagbag.py
def process_file(self, filepath, only_if_updated=True, safe_mode=True):
"""Given a path to a python module or zip file, import the module and look for dag objects within."""
from airflow.models.dag import DagContext
if filepath is None or not os.path.isfile(filepath):
return []
try:
file_last_changed_on_disk = datetime.fromtimestamp(os.path.getmtime(filepath))
if (
only_if_updated
and filepath in self.file_last_changed
and file_last_changed_on_disk == self.file_last_changed[filepath]
):
return []
except Exception as e:
self.log.exception(e)
return []
DagContext.autoregistered_dags.clear()
if filepath.endswith(".py") or not zipfile.is_zipfile(filepath):
mods = self._load_modules_from_file(filepath, safe_mode)
else:
mods = self._load_modules_from_zip(filepath, safe_mode)
found_dags = self._process_modules(filepath, mods, file_last_changed_on_disk)
self.file_last_changed[filepath] = file_last_changed_on_disk
return found_dags
我们看到,process_file其中调用了_load_modules_from_file方法来从本地文件加载DAG进来的,下面我们分析其加载过程。
# DagBag._load_modules_from_file
这个函数 _load_modules_from_file 主要用于从给定的 Python 文件路径中加载模块。它首先检查文件是否可能包含 DAG 对象,然后使用 importlib 库来加载文件,并处理可能发生的异常。同时,它还支持设置 DAG 导入超时,以防止加载过程耗时过长。
也就是说这部分函数代码是将DAG的定义进行解析的重要环节,解析完以后才可以给调度器进行调度。
以下是该方法的代码步骤:
- 导入
DagContext类。 - 使用
might_contain_dag函数检查文件是否可能包含 DAG 对象。如果不包含 DAG 对象,那么就不需要解析这个文件,直接返回一个空列表。如果这是首次跳过文件,记录一条跳过的日志信息。 - 使用
get_unique_dag_module_name函数为文件生成一个唯一的模块名。 - 如果生成的模块名已经在
sys.modules中,则删除它,以便重新加载。 - 设置
DagContext.current_autoregister_module_name为生成的模块名。 - 定义一个名为
parse的内部函数,用于实际加载和解析文件。这个函数使用importlib库来加载文件。 - 获取 DAG 定义文件的导入超时设置。如果
dagbag_import_timeout不是整数或浮点数,抛出TypeError异常。 - 如果
dagbag_import_timeout小于等于 0,表示没有设置导入超时,直接调用parse函数加载和解析文件。 - 如果设置了导入超时,使用
timeout上下文管理器来限制parse函数的执行时间。如果超时,将抛出一个包含建议如何优化 DAG 导入时间的异常信息。
文件路径:airflow/models/dagbag.py
def _load_modules_from_file(self, filepath, safe_mode):
from airflow.models.dag import DagContext
if not might_contain_dag(filepath, safe_mode):
if not self.has_logged:
self.has_logged = True
self.log.info("File %s assumed to contain no DAGs. Skipping.", filepath)
return []
self.log.debug("Importing %s", filepath)
mod_name = get_unique_dag_module_name(filepath)
if mod_name in sys.modules:
del sys.modules[mod_name]
DagContext.current_autoregister_module_name = mod_name
def parse(mod_name, filepath):
try:
loader = importlib.machinery.SourceFileLoader(mod_name, filepath)
spec = importlib.util.spec_from_loader(mod_name, loader)
new_module = importlib.util.module_from_spec(spec)
sys.modules[spec.name] = new_module
loader.exec_module(new_module)
return [new_module]
except Exception as e:
DagContext.autoregistered_dags.clear()
self.log.exception("Failed to import: %s", filepath)
if self.dagbag_import_error_tracebacks:
self.import_errors[filepath] = traceback.format_exc(
limit=-self.dagbag_import_error_traceback_depth
)
else:
self.import_errors[filepath] = str(e)
return []
dagbag_import_timeout = settings.get_dagbag_import_timeout(filepath)
if not isinstance(dagbag_import_timeout, (int, float)):
raise TypeError(
f"Value ({dagbag_import_timeout}) from get_dagbag_import_timeout must be int or float"
)
if dagbag_import_timeout <= 0: # no parsing timeout
return parse(mod_name, filepath)
timeout_msg = (
f"DagBag import timeout for {filepath} after {dagbag_import_timeout}s.\n"
"Please take a look at these docs to improve your DAG import time:\n"
f"* {get_docs_url('best-practices.html#top-level-python-code')}\n"
f"* {get_docs_url('best-practices.html#reducing-dag-complexity')}"
)
with timeout(dagbag_import_timeout, error_message=timeout_msg):
return parse(mod_name, filepath)
_load_modules_from_zip原理跟该方法类似,这里就不重复展开介绍。
# DagBag.parse
前面parse 函数尝试从给定的文件路径导入 DAG 模块。如果导入成功,它将返回一个包含新导入模块的列表。这个新模块可能包含以下数据:
- DAG 定义:DAG 模块中定义的 DAG 对象,用于表示工作流的依赖关系。DAG 对象通常使用
airflow.models.DAG类实例化,并设置相关参数,如dag_id、schedule_interval等。 - 任务定义:在 DAG 模块中,任务是使用
airflow.operators中的各种运算符(如PythonOperator、BashOperator等)创建的。任务定义了要在工作流中执行的具体操作,并通过set_upstream和set_downstream方法指定它们之间的依赖关系。 - 变量和函数:DAG 模块中可能还包含一些辅助变量和函数,用于在任务执行过程中实现特定的逻辑或处理数据。
- 钩子(Hooks)和连接(Connections):DAG 模块可能还包含钩子和连接的定义,用于与外部系统(如数据库、API 等)进行交互。
- 导入的其他模块和库:DAG 模块可能还需要导入其他 Python 模块或库,以便在任务执行过程中使用。
请注意,parse 函数只负责导入 DAG 模块,并不会执行其中的任务。任务的执行由 Airflow 调度器根据 DAG 的调度设置进行。
也就是说,在导入Dag文件的同时,里面涉及到的Operator都会被创建对象,即调用BaseOperator的__init__初始化方法创建对象。
...
# 创建DAG实例
dag = DAG(
dag_id='my_example_dag',
default_args=dag_args,
description='A simple example DAG',
schedule_interval=timedelta(days=1),
)
# 定义任务
task_1 = DummyOperator(
task_id='task_1',
dag=dag,
)
...
当接下来执行到设置上下游依赖关系是,即:
...
task1 >> task2
# 或
chain(task1, task2)
# 或
task1.set_downstream(task2)
task2.set_upstream(task1)
...
就会调用前面我们介绍的set_downstream和set_upstream方法设置DagRun中任务的依赖关系。
下面是我们介绍重要的参数,这些参数都是在写DAG Python文件时大部分定义的。
任务标识和依赖关系:
- task_id:任务的唯一标识符。
- dag:任务所属的 DAG 对象。
- task_group:任务所属的任务组。
- depends_on_past:任务是否取决于其过去的实例。
- wait_for_downstream:是否等待下游任务完成。
- trigger_rule:触发任务执行的规则。
重试设置:
- retries:任务失败时的重试次数。
- retry_delay:任务重试之间的时间间隔。
- retry_exponential_backoff:是否在重试时使用指数退避策略。
- max_retry_delay:重试之间的最大时间间隔。
回调和钩子:
- on_execute_callback:任务执行时的回调函数。
- on_failure_callback:任务失败时的回调函数。
- on_success_callback:任务成功时的回调函数。
- on_retry_callback:任务重试时的回调函数。
- on_skipped_callback:任务跳过时的回调函数。
- pre_execute:任务执行前的钩子函数。
- post_execute:任务执行后的钩子函数。
其他任务设置:
- params:传递给任务的参数。
- default_args:任务的默认参数。
- priority_weight:任务的优先级权重。
- weight_rule:任务权重规则。
- queue:任务所在的队列。
- pool:任务所在的资源池。
- pool_slots:任务在资源池中占用的插槽数。
- sla:任务的服务级别协议(Service Level Agreement)。
- resources:任务所需的资源。
- run_as_user:运行任务的用户。
- task_concurrency:任务的并发限制。
- map_index_template:任务的映射索引模板。
- max_active_tis_per_dag:每个 DAG 中允许的最大活动任务实例数。
- max_active_tis_per_dagrun:每个 DAG 运行中允许的最大活动任务实例数。
- executor_config:任务的执行器配置。
- do_xcom_push:是否将任务的返回值推送到 XCom。
- multiple_outputs:是否允许任务具有多个输出。
- inlets:任务的上游数据源。
- outlets:任务的下游数据目标。
文件路径:airflow/airflow/models/baseoperator.py
def __init__(
self,
task_id: str,
owner: str = DEFAULT_OWNER,
email: str | Iterable[str] | None = None,
email_on_retry: bool = conf.getboolean("email", "default_email_on_retry", fallback=True),
email_on_failure: bool = conf.getboolean("email", "default_email_on_failure", fallback=True),
retries: int | None = DEFAULT_RETRIES,
retry_delay: timedelta | float = DEFAULT_RETRY_DELAY,
retry_exponential_backoff: bool = False,
max_retry_delay: timedelta | float | None = None,
start_date: datetime | None = None,
end_date: datetime | None = None,
depends_on_past: bool = False,
ignore_first_depends_on_past: bool = DEFAULT_IGNORE_FIRST_DEPENDS_ON_PAST,
wait_for_past_depends_before_skipping: bool = DEFAULT_WAIT_FOR_PAST_DEPENDS_BEFORE_SKIPPING,
wait_for_downstream: bool = False,
dag: DAG | None = None,
params: collections.abc.MutableMapping | None = None,
default_args: dict | None = None,
priority_weight: int = DEFAULT_PRIORITY_WEIGHT,
weight_rule: str | PriorityWeightStrategy = DEFAULT_WEIGHT_RULE,
queue: str = DEFAULT_QUEUE,
pool: str | None = None,
pool_slots: int = DEFAULT_POOL_SLOTS,
sla: timedelta | None = None,
execution_timeout: timedelta | None = DEFAULT_TASK_EXECUTION_TIMEOUT,
on_execute_callback: None | TaskStateChangeCallback | list[TaskStateChangeCallback] = None,
on_failure_callback: None | TaskStateChangeCallback | list[TaskStateChangeCallback] = None,
on_success_callback: None | TaskStateChangeCallback | list[TaskStateChangeCallback] = None,
on_retry_callback: None | TaskStateChangeCallback | list[TaskStateChangeCallback] = None,
on_skipped_callback: None | TaskStateChangeCallback | list[TaskStateChangeCallback] = None,
pre_execute: TaskPreExecuteHook | None = None,
post_execute: TaskPostExecuteHook | None = None,
trigger_rule: str = DEFAULT_TRIGGER_RULE,
resources: dict[str, Any] | None = None,
run_as_user: str | None = None,
task_concurrency: int | None = None,
map_index_template: str | None = None,
max_active_tis_per_dag: int | None = None,
max_active_tis_per_dagrun: int | None = None,
executor_config: dict | None = None,
do_xcom_push: bool = True,
multiple_outputs: bool = False,
inlets: Any | None = None,
outlets: Any | None = None,
task_group: TaskGroup | None = None,
doc: str | None = None,
doc_md: str | None = None,
doc_json: str | None = None,
doc_yaml: str | None = None,
doc_rst: str | None = None,
logger_name: str | None = None,
allow_nested_operators: bool = True,
**kwargs,
):
...
# DagBag._process_modules
从本地加载完DAG文件导入模块后,接下来调用 _process_modules 方法处理加载的模块,并获取找到的 DAG 对象列表 found_dags。这个方法会遍历模块中的所有对象,查找类型为 DAG 的对象,并将它们添加到 DagBag 实例中。
以下是该方法的功能解释:
- 从
airflow.models.dag模块导入DAG和DagContext类,避免循环导入。 - 使用列表推导式遍历模块中的所有对象,找到类型为
DAG的对象,并将它们存储在top_level_dags集合中。同时,将DagContext.autoregistered_dags中的 DAG 也添加到top_level_dags集合中。 - 重置
DagContext.current_autoregister_module_name为None,并清空DagContext.autoregistered_dags。 - 创建一个空列表
found_dags,用于存储找到的 DAG 对象。 - 遍历
top_level_dags集合中的 DAG 对象。为每个 DAG 对象设置fileloc属性,该属性指向其所在的模块文件。 - 尝试验证 DAG 对象,并使用
bag_dag方法将其添加到DagBag实例中。如果在这个过程中遇到AirflowClusterPolicySkipDag异常,则跳过这个 DAG。如果遇到其他异常,记录异常信息,并将错误信息添加到self.import_errors字典中,同时更新self.file_last_changed字典。 - 如果没有发生异常,将 DAG 对象添加到
found_dags列表中,并将 DAG 的子 DAG 也添加到found_dags列表中。 - 返回找到的 DAG 对象列表
found_dags。
文件路径:airflow/models/dagbag.py
def _process_modules(self, filepath, mods, file_last_changed_on_disk):
from airflow.models.dag import DAG, DagContext
top_level_dags = {(o, m) for m in mods for o in m.__dict__.values() if isinstance(o, DAG)}
top_level_dags.update(DagContext.autoregistered_dags)
DagContext.current_autoregister_module_name = None
DagContext.autoregistered_dags.clear()
found_dags = []
for dag, mod in top_level_dags:
dag.fileloc = mod.__file__
try:
dag.validate()
self.bag_dag(dag=dag, root_dag=dag)
except AirflowClusterPolicySkipDag:
pass
except Exception as e:
self.log.exception("Failed to bag_dag: %s", dag.fileloc)
self.import_errors[dag.fileloc] = f"{type(e).__name__}: {e}"
self.file_last_changed[dag.fileloc] = file_last_changed_on_disk
else:
found_dags.append(dag)
found_dags += dag.subdags
return found_dags
# 5、DAG调度
# SchedulerJobRunner._run_scheduler_loop

该函数它实现了调度器的主要循环逻辑。调度器的主要任务是解析 DAG 文件、找到可执行的任务、将任务加入队列以及与执行器进行心跳。以下是该方法的步骤:
检查
processor_agent是否已经启动。如果没有启动,则抛出ValueError异常。初始化一个
EventScheduler对象,用于管理定时事件。添加一系列定时事件,包括检查孤儿任务、检查触发器超时、发送池指标、检查僵尸任务、更新暂停 DAG 的状态、处理长时间处于队列中的任务等。
使用
itertools.count创建一个无限循环。在每次循环中执行以下操作:a. 如果使用的是 SQLite 数据库,并且
processor_agent已启动,则运行单次解析循环,并等待解析器完成,以避免同时访问数据库。b. 创建一个新的数据库会话,并调用
_do_scheduling方法执行调度任务。这个方法会找到可执行的任务实例,并将它们加入执行器的队列。c. 调用执行器的
heartbeat方法,执行队列中的任务并同步运行中任务的状态。d. 如果
processor_agent已启动,调用它的heartbeat方法。e. 定期执行调度器的心跳,以更新其状态。
f. 运行所有挂起的定时事件。
如果调度器处于空闲状态(即没有新的任务实例加入队列,也没有任务完成),则让调度器线程休眠一段时间,以减少 CPU 使用率。
如果达到了指定的调度循环次数或解析次数,退出循环。
def _run_scheduler_loop(self) -> None:
if not self.processor_agent and not self._standalone_dag_processor:
raise ValueError("Processor agent is not started.")
is_unit_test: bool = conf.getboolean("core", "unit_test_mode")
timers = EventScheduler()
self.adopt_or_reset_orphaned_tasks()
timers.call_regular_interval(
conf.getfloat("scheduler", "orphaned_tasks_check_interval", fallback=300.0),
self.adopt_or_reset_orphaned_tasks,
)
timers.call_regular_interval(
conf.getfloat("scheduler", "trigger_timeout_check_interval", fallback=15.0),
self.check_trigger_timeouts,
)
timers.call_regular_interval(
conf.getfloat("scheduler", "pool_metrics_interval", fallback=5.0),
self._emit_pool_metrics,
)
timers.call_regular_interval(
conf.getfloat("scheduler", "zombie_detection_interval", fallback=10.0),
self._find_zombies,
)
timers.call_regular_interval(60.0, self._update_dag_run_state_for_paused_dags)
timers.call_regular_interval(
conf.getfloat("scheduler", "task_queued_timeout_check_interval"),
self._fail_tasks_stuck_in_queued,
)
timers.call_regular_interval(
conf.getfloat("scheduler", "parsing_cleanup_interval"),
self._orphan_unreferenced_datasets,
)
if self._standalone_dag_processor:
timers.call_regular_interval(
conf.getfloat("scheduler", "parsing_cleanup_interval"),
self._cleanup_stale_dags,
)
for loop_count in itertools.count(start=1):
with Stats.timer("scheduler.scheduler_loop_duration") as timer:
if self.using_sqlite and self.processor_agent:
self.processor_agent.run_single_parsing_loop()
self.log.debug("Waiting for processors to finish since we're using sqlite")
self.processor_agent.wait_until_finished()
with create_session() as session:
num_queued_tis = self._do_scheduling(session)
self.job.executor.heartbeat()
session.expunge_all()
num_finished_events = self._process_executor_events(session=session)
if self.processor_agent:
self.processor_agent.heartbeat()
perform_heartbeat(
job=self.job, heartbeat_callback=self.heartbeat_callback, only_if_necessary=True
)
next_event = timers.run(blocking=False)
self.log.debug("Next timed event is in %f", next_event)
self.log.debug("Ran scheduling loop in %.2f seconds", timer.duration)
if not is_unit_test and not num_queued_tis and not num_finished_events:
time.sleep(min(self._scheduler_idle_sleep_time, next_event or 0))
if loop_count >= self.num_runs > 0:
self.log.info(
"Exiting scheduler loop as requested number of runs (%d - got to %d) has been reached",
self.num_runs,
loop_count,
)
break
if self.processor_agent and self.processor_agent.done:
self.log.info(
"Exiting scheduler loop as requested DAG parse count (%d) has been reached after %d"
" scheduler loops",
self.num_times_parse_dags,
loop_count,
)
break
# 6、DAGRun实例创建
# SchedulerJobRunner._create_dag_runs
在调度循环中,Scheduler会根据DAG的调度间隔和触发规则创建DAG运行实例。这一过程涉及到``SchedulerJobRunner._create_dagruns_for_dags和SchedulerJobRunner._create_dag_runs`方法。
这两个方法的主要作用是为需要运行的 DAG 创建 DagRun 实例。
_create_dagruns_for_dags方法首先调用DagModel.dags_needing_dagruns方法找到需要创建 DagRun 的 DAG,然后将这些 DAG 分为两类:dataset 触发的 DAG 和非 dataset 触发的 DAG。然后,分别调用_create_dag_runs和_create_dag_runs_dataset_triggered方法为这两类 DAG 创建 DagRun。最后,提交数据库会话,释放对DagModel表的写锁。_create_dag_runs方法为给定的 DAG 模型创建 DagRun 实例,并更新 DAG 模型的next_dagrun和next_dagrun_create_after字段以控制下一个 DagRun 的创建时间。首先,从数据库中获取已存在的 DagRun 实例,以避免创建重复的 DagRun。然后,获取每个 DAG 当前的活动运行数。接着,遍历每个 DAG 模型,获取对应的 DAG 实例,并为其创建一个新的 DagRun 实例。如果 DagRun 已存在或创建成功,更新 DAG 模型的next_dagrun和next_dagrun_create_after字段。如果在创建过程中发生异常,记录异常信息并继续处理下一个 DAG。
@retry_db_transaction
def _create_dagruns_for_dags(self, guard: CommitProhibitorGuard, session: Session) -> None:
"""Find Dag Models needing DagRuns and Create Dag Runs with retries in case of OperationalError."""
query, dataset_triggered_dag_info = DagModel.dags_needing_dagruns(session)
all_dags_needing_dag_runs = set(query.all())
dataset_triggered_dags = [
dag for dag in all_dags_needing_dag_runs if dag.dag_id in dataset_triggered_dag_info
]
non_dataset_dags = all_dags_needing_dag_runs.difference(dataset_triggered_dags)
self._create_dag_runs(non_dataset_dags, session)
if dataset_triggered_dags:
self._create_dag_runs_dataset_triggered(
dataset_triggered_dags, dataset_triggered_dag_info, session
)
guard.commit()
def _create_dag_runs(self, dag_models: Collection[DagModel], session: Session) -> None:
"""Create a DAG run and update the dag_model to control if/when the next DAGRun should be created."""
existing_dagruns = (
session.execute(
select(DagRun.dag_id, DagRun.execution_date).where(
tuple_in_condition(
(DagRun.dag_id, DagRun.execution_date),
((dm.dag_id, dm.next_dagrun) for dm in dag_models),
),
)
)
.unique()
.all()
)
active_runs_of_dags = Counter(
DagRun.active_runs_of_dags(dag_ids=(dm.dag_id for dm in dag_models), session=session),
)
for dag_model in dag_models:
dag = self.dagbag.get_dag(dag_model.dag_id, session=session)
if not dag:
self.log.error("DAG '%s' not found in serialized_dag table", dag_model.dag_id)
continue
dag_hash = self.dagbag.dags_hash.get(dag.dag_id)
data_interval = dag.get_next_data_interval(dag_model)
if (dag.dag_id, dag_model.next_dagrun) not in existing_dagruns:
try:
dag.create_dagrun(
run_type=DagRunType.SCHEDULED,
execution_date=dag_model.next_dagrun,
state=DagRunState.QUEUED,
data_interval=data_interval,
external_trigger=False,
session=session,
dag_hash=dag_hash,
creating_job_id=self.job.id,
)
active_runs_of_dags[dag.dag_id] += 1
except Exception:
self.log.exception("Failed creating DagRun for %s", dag.dag_id)
continue
if self._should_update_dag_next_dagruns(
dag,
dag_model,
last_dag_run=None,
total_active_runs=active_runs_of_dags[dag.dag_id],
session=session,
):
dag_model.calculate_dagrun_date_fields(dag, data_interval)
最终是通过调用DAG类的create_dagrun方法来创建DagRun实例和添加到数据库。
# DAG.create_dagrun
路径:airflow/models/dag.py
create_dagrun 函数是 Airflow 中 DAG 类的一个方法,用于为 DAG 创建一个新的 DagRun 实例。以下是该方法的关键代码,可以看到create_dagrun方法会创建一个DagRun实例并添加到数据库中,然后返回该实例。
@provide_session
def create_dagrun(
self,
state: DagRunState,
execution_date: datetime | None = None,
run_id: str | None = None,
start_date: datetime | None = None,
external_trigger: bool | None = False,
conf: dict | None = None,
run_type: DagRunType | None = None,
session: Session = NEW_SESSION,
dag_hash: str | None = None,
creating_job_id: int | None = None,
data_interval: tuple[datetime, datetime] | None = None,
):
# 其他代码....
run = DagRun(
dag_id=self.dag_id,
run_id=run_id,
execution_date=logical_date,
start_date=start_date,
external_trigger=external_trigger,
conf=conf,
state=state,
run_type=run_type,
dag_hash=dag_hash,
creating_job_id=creating_job_id,
data_interval=data_interval,
)
session.add(run)
session.flush()
run.dag = self
run.verify_integrity(session=session)
return run
# 7、DagRun任务实例调度
对于每个DAG运行实例,Scheduler会根据任务之间的依赖关系安排任务。这一过程涉及到SchedulerJob._schedule_dag_run方法。
它会根据DAG中任务之间的依赖关系确定哪些任务应该被执行,并为这些任务创建相应的任务实例。
# SchedulerJobRunner._do_scheduling
这个方法的主要目的是在 Airflow 调度器中执行调度任务,包括创建和启动 DagRuns、安排任务实例、将回调发送给处理器等。
以下是方法的详细解释:
- 使用
prohibit_commit上下文管理器确保在此代码块中不会意外地提交 session。 - 如果
settings.USE_JOB_SCHEDULE为 True,则调用_create_dagruns_for_dags方法为所有 DAGs 创建 DagRuns。 - 调用
_start_queued_dagruns方法启动排队的 DagRuns。 - 使用
_get_next_dagruns_to_examine方法获取要检查的 DagRuns(状态为 RUNNING)。 - 使用
_schedule_all_dag_runs方法为所有 DagRuns 安排任务实例。 - 创建一个名为
cached_get_dag的函数,该函数使用 LRU 缓存从 DagBag 中获取 DAG。 - 遍历所有的 DagRuns 和回调函数,从缓存中获取 DAG 并将回调发送给处理器。
- 使用
prohibit_commit上下文管理器确保在此代码块中不会意外地提交 session。 - 清除 session 中的所有对象。
- 检查执行器是否有可用的插槽数。如果没有,跳过关键部分,将
num_queued_tis设为 0。 - 如果有可用的插槽数,尝试进入关键部分,并使用计时器记录执行时间。调用
_critical_section_enqueue_task_instances方法将任务实例添加到队列中。如果发生操作错误(如锁不可用),则捕获异常并根据错误类型进行处理。如果是锁不可用的错误,记录调试日志并将num_queued_tis设为 0。否则,抛出异常。 - 提交 session 更改。
- 返回排队的任务实例数量(
num_queued_tis)。
def _do_scheduling(self, session: Session) -> int:
with prohibit_commit(session) as guard:
if settings.USE_JOB_SCHEDULE:
self._create_dagruns_for_dags(guard, session)
self._start_queued_dagruns(session)
guard.commit()
dag_runs = self._get_next_dagruns_to_examine(DagRunState.RUNNING, session)
callback_tuples = self._schedule_all_dag_runs(guard, dag_runs, session)
cached_get_dag: Callable[[str], DAG | None] = lru_cache()(
partial(self.dagbag.get_dag, session=session)
)
for dag_run, callback_to_run in callback_tuples:
dag = cached_get_dag(dag_run.dag_id)
if dag:
self._send_dag_callbacks_to_processor(dag, callback_to_run)
else:
self.log.error("DAG '%s' not found in serialized_dag table", dag_run.dag_id)
with prohibit_commit(session) as guard:
session.expunge_all()
if self.job.executor.slots_available <= 0:
self.log.debug("Executor full, skipping critical section")
num_queued_tis = 0
else:
try:
timer = Stats.timer("scheduler.critical_section_duration")
timer.start()
num_queued_tis = self._critical_section_enqueue_task_instances(session=session)
timer.stop(send=True)
except OperationalError as e:
timer.stop(send=False)
if is_lock_not_available_error(error=e):
self.log.debug("Critical section lock held by another Scheduler")
Stats.incr("scheduler.critical_section_busy")
session.rollback()
return 0
raise
guard.commit()
return num_queued_tis
# SchedulerJobRunner._schedule_all_dag_runs
这段代码定义了一个名为 _schedule_all_dag_runs 的方法,它对一组 DAG 运行实例(DagRun)进行调度决策。这个方法接收三个参数:一个是 guard,代表一个禁止提交的保护器(CommitProhibitorGuard);一个是 dag_runs,代表一个可迭代的 DAG 运行实例集合;另一个是 session,代表数据库会话。
下图是,在该函数中,任务实例状态发生的变迁。
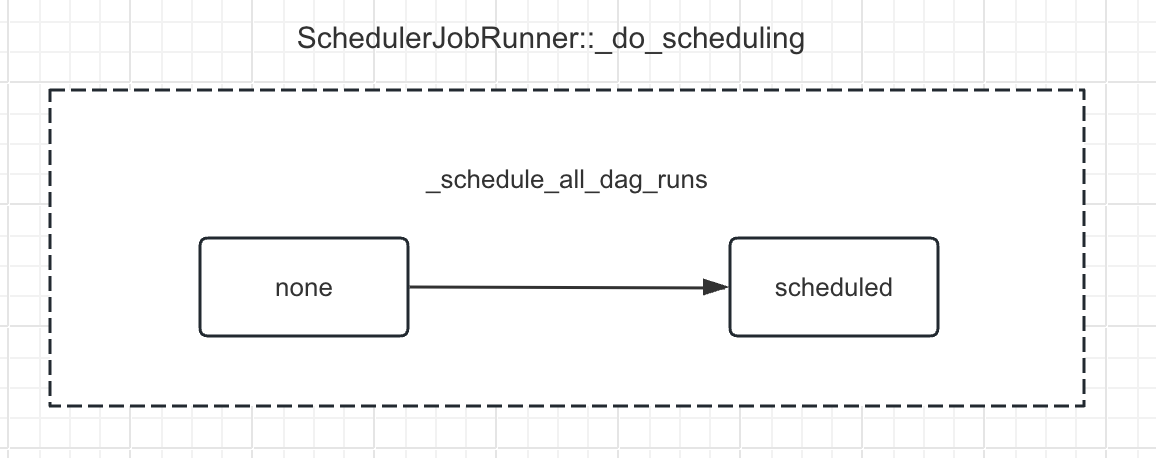
以下是具体的步骤:
- 使用列表推导式遍历
dag_runs,对每个 DAG 运行实例调用_schedule_dag_run方法进行调度决策。将每个 DAG 运行实例及其对应的回调函数(如果有的话)组成一个元组,添加到列表callback_tuples中。 - 提交
guard保护的事务。 - 返回
callback_tuples列表。
这个方法的返回值是一个列表,其中的每个元素都是一个包含两个元素的元组。第一个元素是一个 DAG 运行实例,第二个元素是一个 DagCallbackRequest 对象(表示需要执行的回调函数)或者是 None(表示没有需要执行的回调函数)。
注意,这个方法使用了一个名为 retry_db_transaction 的装饰器。这个装饰器的作用是在数据库事务失败时自动重试该方法。这样可以确保在遇到数据库事务问题时,调度器仍然可以正常工作。
文件路径:airflow/jobs/scheduler_job_runner.py
@retry_db_transaction
def _schedule_all_dag_runs(
self,
guard: CommitProhibitorGuard,
dag_runs: Iterable[DagRun],
session: Session,
) -> list[tuple[DagRun, DagCallbackRequest | None]]:
"""Make scheduling decisions for all `dag_runs`."""
callback_tuples = [(run, self._schedule_dag_run(run, session=session)) for run in dag_runs]
guard.commit()
return callback_tuples
# SchedulerJobRunner._schedule_dag_run
这段代码定义了一个名为 _schedule_dag_run 的方法,这个方法对单个的 DAG 运行实例(DagRun)进行调度决策。这个方法接收两个参数:一个是 dag_run,代表需要调度的 DAG 运行实例;另一个是 session,代表数据库会话。
以下是具体的步骤:
从 DAG 包(DagBag)和数据库中获取对应的 DAG 和 DAG 模型(DagModel)。如果找不到,就记录错误日志并返回。
检查 DAG 运行实例是否超时。如果 DAG 运行实例已经开始,并且设置了超时时间,且开始时间早于当前时间减去超时时间,那么就将 DAG 运行实例的状态设置为失败(FAILED)。然后,将所有未完成的任务实例(TaskInstance)的状态设置为跳过(SKIPPED),并将这些更改保存到数据库。最后,记录日志,表示 DAG 运行实例已经超时。
如果 DAG 运行实例的执行日期晚于当前时间,并且 DAG 不允许未来的执行日期,那么就记录错误日志并返回。
如果 DAG 发生了变化,那么就验证 DAG 的完整性。如果在验证过程中 DAG 消失了,那么就记录警告日志并返回。
调用
dag_run.update_state方法,更新 DAG 运行实例的状态,并获取可以调度的任务实例和需要运行的回调函数。该方法根据其任务实例(TaskInstances)的状态进行判断。这个方法会检查所有任务实例的状态,如果所有任务实例都成功,那么 DagRun 就标记为成功;如果有任何一个任务实例失败,那么 DagRun 就标记为失败;如果所有任务实例都处于死锁状态,那么 DagRun 就标记为失败;否则, DagRun 的状态就被标记为运行中。
如果需要更新 DAG 的下一个运行日期,那么就计算下一个运行日期。
调用
dag_run.schedule_tis方法,调度可以调度的任务实例。返回需要运行的回调函数。
这个方法的返回值是一个 DagCallbackRequest 对象,表示需要执行的回调函数,或者是 None,表示没有需要执行的回调函数。
文件路径:airflow/jobs/scheduler_job_runner.py
def _schedule_dag_run(
self,
dag_run: DagRun,
session: Session,
) -> DagCallbackRequest | None:
callback: DagCallbackRequest | None = None
dag = dag_run.dag = self.dagbag.get_dag(dag_run.dag_id, session=session)
dag_model = DM.get_dagmodel(dag_run.dag_id, session)
if not dag or not dag_model:
self.log.error("Couldn't find DAG %s in DAG bag or database!", dag_run.dag_id)
return callback
if (
dag_run.start_date
and dag.dagrun_timeout
and dag_run.start_date < timezone.utcnow() - dag.dagrun_timeout
):
dag_run.set_state(DagRunState.FAILED)
unfinished_task_instances = session.scalars(
select(TI)
.where(TI.dag_id == dag_run.dag_id)
.where(TI.run_id == dag_run.run_id)
.where(TI.state.in_(State.unfinished))
)
for task_instance in unfinished_task_instances:
task_instance.state = TaskInstanceState.SKIPPED
session.merge(task_instance)
session.flush()
self.log.info("Run %s of %s has timed-out", dag_run.run_id, dag_run.dag_id)
if self._should_update_dag_next_dagruns(dag, dag_model, last_dag_run=dag_run, session=session):
dag_model.calculate_dagrun_date_fields(dag, dag.get_run_data_interval(dag_run))
callback_to_execute = DagCallbackRequest(
full_filepath=dag.fileloc,
dag_id=dag.dag_id,
run_id=dag_run.run_id,
is_failure_callback=True,
processor_subdir=dag_model.processor_subdir,
msg="timed_out",
)
dag_run.notify_dagrun_state_changed()
duration = dag_run.end_date - dag_run.start_date
Stats.timing(f"dagrun.duration.failed.{dag_run.dag_id}", duration)
Stats.timing("dagrun.duration.failed", duration, tags={"dag_id": dag_run.dag_id})
return callback_to_execute
if dag_run.execution_date > timezone.utcnow() and not dag.allow_future_exec_dates:
self.log.error("Execution date is in future: %s", dag_run.execution_date)
return callback
if not self._verify_integrity_if_dag_changed(dag_run=dag_run, session=session):
self.log.warning("The DAG disappeared before verifying integrity: %s. Skipping.", dag_run.dag_id)
return callback
schedulable_tis, callback_to_run = dag_run.update_state(session=session, execute_callbacks=False)
if self._should_update_dag_next_dagruns(dag, dag_model, last_dag_run=dag_run, session=session):
dag_model.calculate_dagrun_date_fields(dag, dag.get_run_data_interval(dag_run))
dag_run.schedule_tis(schedulable_tis, session, max_tis_per_query=self.job.max_tis_per_query)
return callback_to_run
在dag_run.update_state方法中我们看到它返回了可调度的任务实例,也就是这里会决定当前DagRun任务实例(TaskInstances)的调度决策信息。该方法里主要通过调用task_instance_scheduling_decisions实现。
# DagRun.task_instance_scheduling_decisions
task_instance_scheduling_decisions 方法用于获取 DAG 运行实例(DagRun)的任务实例(TaskInstances)的调度决策信息。它首先获取所有任务实例,然后排除在 DAG 中找不到的任务实例。接着,将任务实例分为未完成的和已完成的两组。对于未完成的任务实例,选择状态为可调度(scheduled)的任务实例,并获取准备好的任务实例。最后,返回一个包含所有任务实例、可调度的任务实例、已更改的任务实例、未完成的任务实例和已完成的任务实例的 TISchedulingDecision 对象。
下面是每个代码的分段解释:
- 调用
get_task_instances方法获取所有状态为State.task_states的任务实例。 - 定义一个名为
_filter_tis_and_exclude_removed的函数,用于获取任务实例对应的任务,并排除那些在 DAG 中找不到的任务实例。如果任务实例的状态不是已移除(REMOVED),那么就将其状态设置为已移除,并保存到数据库。 - 调用
_filter_tis_and_exclude_removed函数处理任务实例。 - 将任务实例分为未完成的和已完成的两组。
- 如果有未完成的任务实例,那么就从中选择状态为可调度的任务实例,并调用
_get_ready_tis方法获取准备好的任务实例。如果在这个过程中发生了扩展,那么就重新计算未完成的和已完成的任务实例。 - 如果没有未完成的任务实例,那么就将可调度的任务实例和已更改的任务实例设置为空。
- 返回一个
TISchedulingDecision对象,包含所有任务实例、可调度的任务实例、已更改的任务实例、未完成的任务实例和已完成的任务实例。
这个方法的返回值是一个 TISchedulingDecision 对象,表示任务实例的调度决策信息。
@provide_session
def task_instance_scheduling_decisions(self, session: Session = NEW_SESSION) -> TISchedulingDecision:
tis = self.get_task_instances(session=session, state=State.task_states)
self.log.debug("number of tis tasks for %s: %s task(s)", self, len(tis))
def _filter_tis_and_exclude_removed(dag: DAG, tis: list[TI]) -> Iterable[TI]:
"""Populate ``ti.task`` while excluding those missing one, marking them as REMOVED."""
for ti in tis:
try:
ti.task = dag.get_task(ti.task_id)
except TaskNotFound:
if ti.state != TaskInstanceState.REMOVED:
self.log.error("Failed to get task for ti %s. Marking it as removed.", ti)
ti.state = TaskInstanceState.REMOVED
session.flush()
else:
yield ti
tis = list(_filter_tis_and_exclude_removed(self.get_dag(), tis))
unfinished_tis = [t for t in tis if t.state in State.unfinished]
finished_tis = [t for t in tis if t.state in State.finished]
if unfinished_tis:
schedulable_tis = [ut for ut in unfinished_tis if ut.state in SCHEDULEABLE_STATES]
self.log.debug("number of scheduleable tasks for %s: %s task(s)", self, len(schedulable_tis))
schedulable_tis, changed_tis, expansion_happened = self._get_ready_tis(
schedulable_tis,
finished_tis,
session=session,
)
if expansion_happened:
changed_tis = True
new_unfinished_tis = [t for t in unfinished_tis if t.state in State.unfinished]
finished_tis.extend(t for t in unfinished_tis if t.state in State.finished)
unfinished_tis = new_unfinished_tis
else:
schedulable_tis = []
changed_tis = False
return TISchedulingDecision(
tis=tis,
schedulable_tis=schedulable_tis,
changed_tis=changed_tis,
unfinished_tis=unfinished_tis,
finished_tis=finished_tis,
)
# DagRun.schedule_tis
这段代码定义了一个名为 schedule_tis 的方法,它负责将给定的任务实例(TaskInstances,简称 TIs)设置为调度状态(SCHEDULED)。这个方法接收三个参数:一个是 schedulable_tis,代表可调度的任务实例集合;一个是 session,代表数据库会话;另一个是 max_tis_per_query,代表每个查询中最多处理的任务实例数量。
以下是具体的步骤:
- 遍历
schedulable_tis,将不需要执行的任务实例(如使用 EmptyOperator 且没有回调函数或出口的任务实例)添加到dummy_ti_ids列表中,将需要执行的任务实例添加到schedulable_ti_ids列表中。 - 初始化计数器
count为 0。 - 如果有需要执行的任务实例,那么将
schedulable_ti_ids列表分割成多个块(每个块的大小由max_tis_per_query决定),然后遍历这些块,对每个块执行更新操作,将任务实例的状态设置为调度状态(SCHEDULED),并累加影响的行数到计数器count。 - 如果有不需要执行的任务实例(如使用 EmptyOperator 的任务实例),那么将
dummy_ti_ids列表分割成多个块(每个块的大小由max_tis_per_query决定),然后遍历这些块,对每个块执行更新操作,将任务实例的状态设置为成功状态(SUCCESS),并设置开始时间、结束时间和持续时间为 0,同时累加影响的行数到计数器count。 - 返回计数器
count的值,表示本次调度的任务实例数量。
@provide_session
def schedule_tis(
self,
schedulable_tis: Iterable[TI],
session: Session = NEW_SESSION,
max_tis_per_query: int | None = None,
) -> int:
dummy_ti_ids = []
schedulable_ti_ids = []
for ti in schedulable_tis:
if TYPE_CHECKING:
assert ti.task
if (
ti.task.inherits_from_empty_operator
and not ti.task.on_execute_callback
and not ti.task.on_success_callback
and not ti.task.outlets
):
dummy_ti_ids.append((ti.task_id, ti.map_index))
else:
schedulable_ti_ids.append((ti.task_id, ti.map_index))
count = 0
if schedulable_ti_ids:
schedulable_ti_ids_chunks = chunks(
schedulable_ti_ids, max_tis_per_query or len(schedulable_ti_ids)
)
for schedulable_ti_ids_chunk in schedulable_ti_ids_chunks:
count += session.execute(
update(TI)
.where(
TI.dag_id == self.dag_id,
TI.run_id == self.run_id,
tuple_in_condition((TI.task_id, TI.map_index), schedulable_ti_ids_chunk),
)
.values(state=TaskInstanceState.SCHEDULED)
.execution_options(synchronize_session=False)
).rowcount
if dummy_ti_ids:
dummy_ti_ids_chunks = chunks(dummy_ti_ids, max_tis_per_query or len(dummy_ti_ids))
for dummy_ti_ids_chunk in dummy_ti_ids_chunks:
count += session.execute(
update(TI)
.where(
TI.dag_id == self.dag_id,
TI.run_id == self.run_id,
tuple_in_condition((TI.task_id, TI.map_index), dummy_ti_ids_chunk),
)
.values(
state=TaskInstanceState.SUCCESS,
start_date=timezone.utcnow(),
end_date=timezone.utcnow(),
duration=0,
)
.execution_options(
synchronize_session=False,
)
).rowcount
return count
# 8、DagRun任务实例入队列
在Airflow中,任务实例的处理主要在SchedulerJob._do_scheduling方法中进行,它会根据DAG中任务之间的依赖关系以及任务实例的状态来决定哪些任务实例应该被执行。
在_do_scheduling方法中,会调用_executable_task_instances_to_queued方法来获取可执行的任务实例,并将它们放入队列中等待执行。然后,调用_enqueue_task_instances_with_queued_state方法将这些任务实例发送到执行器(如LocalExecutor、CeleryExecutor等)进行执行。
对于每个任务实例,其执行过程是在BaseOperator.execute方法中进行的。这个方法会调用具体的操作符类(如PythonOperator、BashOperator等)的execute方法来执行任务。
# SchedulerJobRunner._critical_section_enqueue_task_instances
它负责将任务实例(TaskInstances,简称 TIs)排入执行队列。下图是任务实例在该函数的转变。
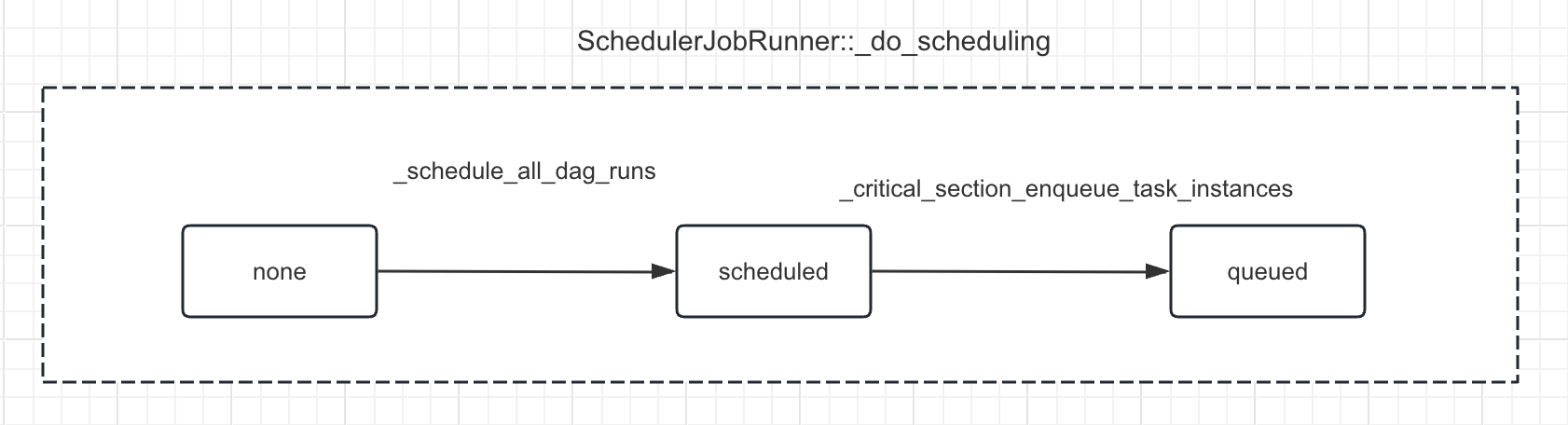
以下是具体的步骤:
- 根据
max_tis_per_query和执行器的可用插槽数确定本次可以处理的最大任务实例数量。 - 调用
_executable_task_instances_to_queued方法获取需要排入队列的任务实例。 - 调用
_enqueue_task_instances_with_queued_state方法将任务实例排入执行队列。
这个方法的返回值是一个整数,表示本次排入队列的任务实例数量。
注意,这个方法是一个关键部分,也就是说,在同一时间只能有一个执行器executor进程执行这个方法。这是通过执行 SELECT ... from pool FOR UPDATE 实现的。对于支持 NOWAIT 的数据库,如果一个调度器被阻塞,那么它会跳过这个关键部分,继续执行其他任务(如创建新的 DAG 运行实例,将任务实例的状态从 None 进行到 SCHEDULED 等);对于不支持这个特性的数据库(如 MariaDB 或 MySQL 5.x),其他的调度器会等待锁释放后才能继续执行。
def _critical_section_enqueue_task_instances(self, session: Session) -> int:
if self.job.max_tis_per_query == 0:
max_tis = self.job.executor.slots_available
else:
max_tis = min(self.job.max_tis_per_query, self.job.executor.slots_available)
queued_tis = self._executable_task_instances_to_queued(max_tis, session=session)
self._enqueue_task_instances_with_queued_state(queued_tis, session=session)
return len(queued_tis)
# SchedulerJobRunner._executable_task_instances_to_queued
它负责根据各种条件找到准备好执行的任务实例(TaskInstances,简称 TIs),并将它们设置为排队状态(QUEUED)。
以下是具体的步骤:
- 从
Pool表中获取所有的资源池信息。 - 计算所有资源池的可用插槽数,并检查是否有空闲插槽。如果没有空闲插槽,直接返回空列表。
- 根据
max_tis参数限制最大处理任务实例数量。 - 初始化各种集合,用于存储无法排队的任务实例(如资源池饱和、DAG 最大活动任务限制、执行器状态、优先级、每个 DAG 最大活动任务实例数、每个 DAG 运行实例最大活动任务实例数等)。
- 使用循环查询数据库,获取符合条件的任务实例。条件包括:任务实例状态为 SCHEDULED,DAG 运行实例状态为 RUNNING,DAG 没有暂停,以及排除上述集合中无法排队的任务实例。查询结果按优先级、执行日期和映射索引排序。
- 遍历查询到的任务实例,检查它们是否满足资源池限制、DAG 最大活动任务限制、任务并发限制等条件。如果满足条件,将任务实例添加到
executable_tis列表中,并更新资源池的可用插槽数、DAG 活动任务数、任务并发数等信息。 - 如果在一次循环中没有找到可执行的任务实例,或者任务实例的数量小于
max_tis,那么就结束循环。否则,继续下一轮循环,查询更多符合条件的任务实例。 - 遍历
executable_tis列表,将任务实例的状态设置为排队状态(QUEUED),并更新排队时间和排队作业 ID。同时,发送任务实例状态更改的度量信息。 - 返回
executable_tis列表,即准备好执行的任务实例。
这个方法的返回值是一个任务实例列表,表示准备好执行的任务实例。
def _executable_task_instances_to_queued(self, max_tis: int, session: Session) -> list[TI]:
from airflow.models.pool import Pool
from airflow.utils.db import DBLocks
executable_tis: list[TI] = []
if session.get_bind().dialect.name == "postgresql":
lock_acquired = session.execute(
text("SELECT pg_try_advisory_xact_lock(:id)").bindparams(
id=DBLocks.SCHEDULER_CRITICAL_SECTION.value
)
).scalar()
if not lock_acquired:
raise OperationalError(
"Failed to acquire advisory lock", params=None, orig=RuntimeError("55P03")
)
pools = Pool.slots_stats(lock_rows=True, session=session)
pool_slots_free = sum(max(0, pool["open"]) for pool in pools.values())
if pool_slots_free == 0:
self.log.debug("All pools are full!")
return []
max_tis = min(max_tis, pool_slots_free)
starved_pools = {pool_name for pool_name, stats in pools.items() if stats["open"] <= 0}
concurrency_map = self.__get_concurrency_maps(states=EXECUTION_STATES, session=session)
num_starving_tasks_total = 0
starved_dags: set[str] = set()
starved_tasks: set[tuple[str, str]] = set()
starved_tasks_task_dagrun_concurrency: set[tuple[str, str, str]] = set()
pool_num_starving_tasks: dict[str, int] = Counter()
for loop_count in itertools.count(start=1):
num_starved_pools = len(starved_pools)
num_starved_dags = len(starved_dags)
num_starved_tasks = len(starved_tasks)
num_starved_tasks_task_dagrun_concurrency = len(starved_tasks_task_dagrun_concurrency)
query = (
select(TI)
.with_hint(TI, "USE INDEX (ti_state)", dialect_name="mysql")
.join(TI.dag_run)
.where(DR.run_type != DagRunType.BACKFILL_JOB, DR.state == DagRunState.RUNNING)
.join(TI.dag_model)
.where(not_(DM.is_paused))
.where(TI.state == TaskInstanceState.SCHEDULED)
.options(selectinload(TI.dag_model))
.order_by(-TI.priority_weight, DR.execution_date, TI.map_index)
)
if starved_pools:
query = query.where(not_(TI.pool.in_(starved_pools)))
if starved_dags:
query = query.where(not_(TI.dag_id.in_(starved_dags)))
if starved_tasks:
task_filter = tuple_in_condition((TI.dag_id, TI.task_id), starved_tasks)
query = query.where(not_(task_filter))
if starved_tasks_task_dagrun_concurrency:
task_filter = tuple_in_condition(
(TI.dag_id, TI.run_id, TI.task_id),
starved_tasks_task_dagrun_concurrency,
)
query = query.where(not_(task_filter))
query = query.limit(max_tis)
timer = Stats.timer("scheduler.critical_section_query_duration")
timer.start()
try:
query = with_row_locks(query, of=TI, session=session, skip_locked=True)
task_instances_to_examine: list[TI] = session.scalars(query).all()
timer.stop(send=True)
except OperationalError as e:
timer.stop(send=False)
raise e
if not task_instances_to_examine:
self.log.debug("No tasks to consider for execution.")
break
task_instance_str = "\n".join(f"\t{x!r}" for x in task_instances_to_examine)
self.log.info("%s tasks up for execution:\n%s", len(task_instances_to_examine), task_instance_str)
for task_instance in task_instances_to_examine:
pool_name = task_instance.pool
pool_stats = pools.get(pool_name)
if not pool_stats:
self.log.warning("Tasks using non-existent pool '%s' will not be scheduled", pool_name)
starved_pools.add(pool_name)
continue
pool_num_starving_tasks.setdefault(pool_name, 0)
pool_total = pool_stats["total"]
open_slots = pool_stats["open"]
if open_slots <= 0:
self.log.info(
"Not scheduling since there are %s open slots in pool %s", open_slots, pool_name
)
pool_num_starving_tasks[pool_name] += 1
num_starving_tasks_total += 1
starved_pools.add(pool_name)
continue
if task_instance.pool_slots > pool_total:
self.log.warning(
"Not executing %s. Requested pool slots (%s) are greater than "
"total pool slots: '%s' for pool: %s.",
task_instance,
task_instance.pool_slots,
pool_total,
pool_name,
)
pool_num_starving_tasks[pool_name] += 1
num_starving_tasks_total += 1
starved_tasks.add((task_instance.dag_id, task_instance.task_id))
continue
if task_instance.pool_slots > open_slots:
self.log.info(
"Not executing %s since it requires %s slots "
"but there are %s open slots in the pool %s.",
task_instance,
task_instance.pool_slots,
open_slots,
pool_name,
)
pool_num_starving_tasks[pool_name] += 1
num_starving_tasks_total += 1
starved_tasks.add((task_instance.dag_id, task_instance.task_id))
continue
dag_id = task_instance.dag_id
current_active_tasks_per_dag = concurrency_map.dag_active_tasks_map[dag_id]
max_active_tasks_per_dag_limit = task_instance.dag_model.max_active_tasks
self.log.info(
"DAG %s has %s/%s running and queued tasks",
dag_id,
current_active_tasks_per_dag,
max_active_tasks_per_dag_limit,
)
if current_active_tasks_per_dag >= max_active_tasks_per_dag_limit:
self.log.info(
"Not executing %s since the number of tasks running or queued "
"from DAG %s is >= to the DAG's max_active_tasks limit of %s",
task_instance,
dag_id,
max_active_tasks_per_dag_limit,
)
starved_dags.add(dag_id)
continue
if task_instance.dag_model.has_task_concurrency_limits:
serialized_dag = self.dagbag.get_dag(dag_id, session=session)
if not serialized_dag:
self.log.error(
"DAG '%s' for task instance %s not found in serialized_dag table",
dag_id,
task_instance,
)
session.execute(
update(TI)
.where(TI.dag_id == dag_id, TI.state == TaskInstanceState.SCHEDULED)
.values(state=TaskInstanceState.FAILED)
.execution_options(synchronize_session="fetch")
)
continue
task_concurrency_limit: int | None = None
if serialized_dag.has_task(task_instance.task_id):
task_concurrency_limit = serialized_dag.get_task(
task_instance.task_id
).max_active_tis_per_dag
if task_concurrency_limit is not None:
current_task_concurrency = concurrency_map.task_concurrency_map[
(task_instance.dag_id, task_instance.task_id)
]
if current_task_concurrency >= task_concurrency_limit:
self.log.info(
"Not executing %s since the task concurrency for"
" this task has been reached.",
task_instance,
)
starved_tasks.add((task_instance.dag_id, task_instance.task_id))
continue
task_dagrun_concurrency_limit: int | None = None
if serialized_dag.has_task(task_instance.task_id):
task_dagrun_concurrency_limit = serialized_dag.get_task(
task_instance.task_id
).max_active_tis_per_dagrun
if task_dagrun_concurrency_limit is not None:
current_task_dagrun_concurrency = concurrency_map.task_dagrun_concurrency_map[
(task_instance.dag_id, task_instance.run_id, task_instance.task_id)
]
if current_task_dagrun_concurrency >= task_dagrun_concurrency_limit:
self.log.info(
"Not executing %s since the task concurrency per DAG run for"
" this task has been reached.",
task_instance,
)
starved_tasks_task_dagrun_concurrency.add(
(task_instance.dag_id, task_instance.run_id, task_instance.task_id)
)
continue
executable_tis.append(task_instance)
open_slots -= task_instance.pool_slots
concurrency_map.dag_active_tasks_map[dag_id] += 1
concurrency_map.task_concurrency_map[(task_instance.dag_id, task_instance.task_id)] += 1
concurrency_map.task_dagrun_concurrency_map[
(task_instance.dag_id, task_instance.run_id, task_instance.task_id)
] += 1
pool_stats["open"] = open_slots
is_done = executable_tis or len(task_instances_to_examine) < max_tis
found_new_filters = (
len(starved_pools) > num_starved_pools
or len(starved_dags) > num_starved_dags
or len(starved_tasks) > num_starved_tasks
or len(starved_tasks_task_dagrun_concurrency) > num_starved_tasks_task_dagrun_concurrency
)
if is_done or not found_new_filters:
break
self.log.info(
"Found no task instances to queue on query iteration %s "
"but there could be more candidate task instances to check.",
loop_count,
)
for pool_name, num_starving_tasks in pool_num_starving_tasks.items():
Stats.gauge(f"pool.starving_tasks.{pool_name}", num_starving_tasks)
Stats.gauge("pool.starving_tasks", num_starving_tasks, tags={"pool_name": pool_name})
Stats.gauge("scheduler.tasks.starving", num_starving_tasks_total)
Stats.gauge("scheduler.tasks.executable", len(executable_tis))
if executable_tis:
task_instance_str = "\n".join(f"\t{x!r}" for x in executable_tis)
self.log.info("Setting the following tasks to queued state:\n%s", task_instance_str)
filter_for_tis = TI.filter_for_tis(executable_tis)
session.execute(
update(TI)
.where(filter_for_tis)
.values(
state=TaskInstanceState.QUEUED,
queued_dttm=timezone.utcnow(),
queued_by_job_id=self.job.id,
)
.execution_options(synchronize_session=False)
)
for ti in executable_tis:
ti.emit_state_change_metric(TaskInstanceState.QUEUED)
for ti in executable_tis:
make_transient(ti)
return executable_tis
# SchedulerJobRunner._enqueue_task_instances_with_queued_state
它负责将已经设置为排队状态(QUEUED)的任务实例(TaskInstances,简称 TIs)实际添加到执行器的队列中。
以下是具体的步骤:
- 遍历
task_instances列表。 - 如果任务实例对应的 DAG 运行实例状态已经结束,那么就将任务实例的状态设置为 None,并跳过当前循环。
- 获取任务实例的执行命令、优先级和队列。
- 记录日志,表示正在将任务实例发送到执行器。
- 调用执行器的
queue_command方法,将任务实例的执行命令添加到队列中。
这个方法没有返回值。注意,这个方法需要一个有效的数据库会话,以便更新任务实例的状态。
def _enqueue_task_instances_with_queued_state(self, task_instances: list[TI], session: Session) -> None:
for ti in task_instances:
if ti.dag_run.state in State.finished_dr_states:
ti.set_state(None, session=session)
continue
command = ti.command_as_list(
local=True,
pickle_id=ti.dag_model.pickle_id,
)
priority = ti.priority_weight
queue = ti.queue
self.log.info("Sending %s to executor with priority %s and queue %s", ti.key, priority, queue)
self.job.executor.queue_command(
ti,
command,
priority=priority,
queue=queue,
)
# BaseExecutor->queue_command
文件路径:airflow/airflow/executors/base_executor.py
在上一步_enqueue_task_instances_with_queued_state函数中,最后调用了Executor的queue_command方法添加到队列中给Executor执行。
def queue_command(
self,
task_instance: TaskInstance,
command: CommandType,
priority: int = 1,
queue: str | None = None,
):
"""Queues command to task."""
if task_instance.key not in self.queued_tasks:
self.log.info("Adding to queue: %s", command)
self.queued_tasks[task_instance.key] = (command, priority, queue, task_instance)
else:
self.log.error("could not queue task %s", task_instance.key)
# 9、DagRun任务实例执行
在前面调用了_do_scheduling调度函数以后,接下来就开始调用Executor执行任务实例。

def _run_scheduler_loop(self) -> None:
...
with create_session() as session:
num_queued_tis = self._do_scheduling(session)
self.job.executor.heartbeat()
...
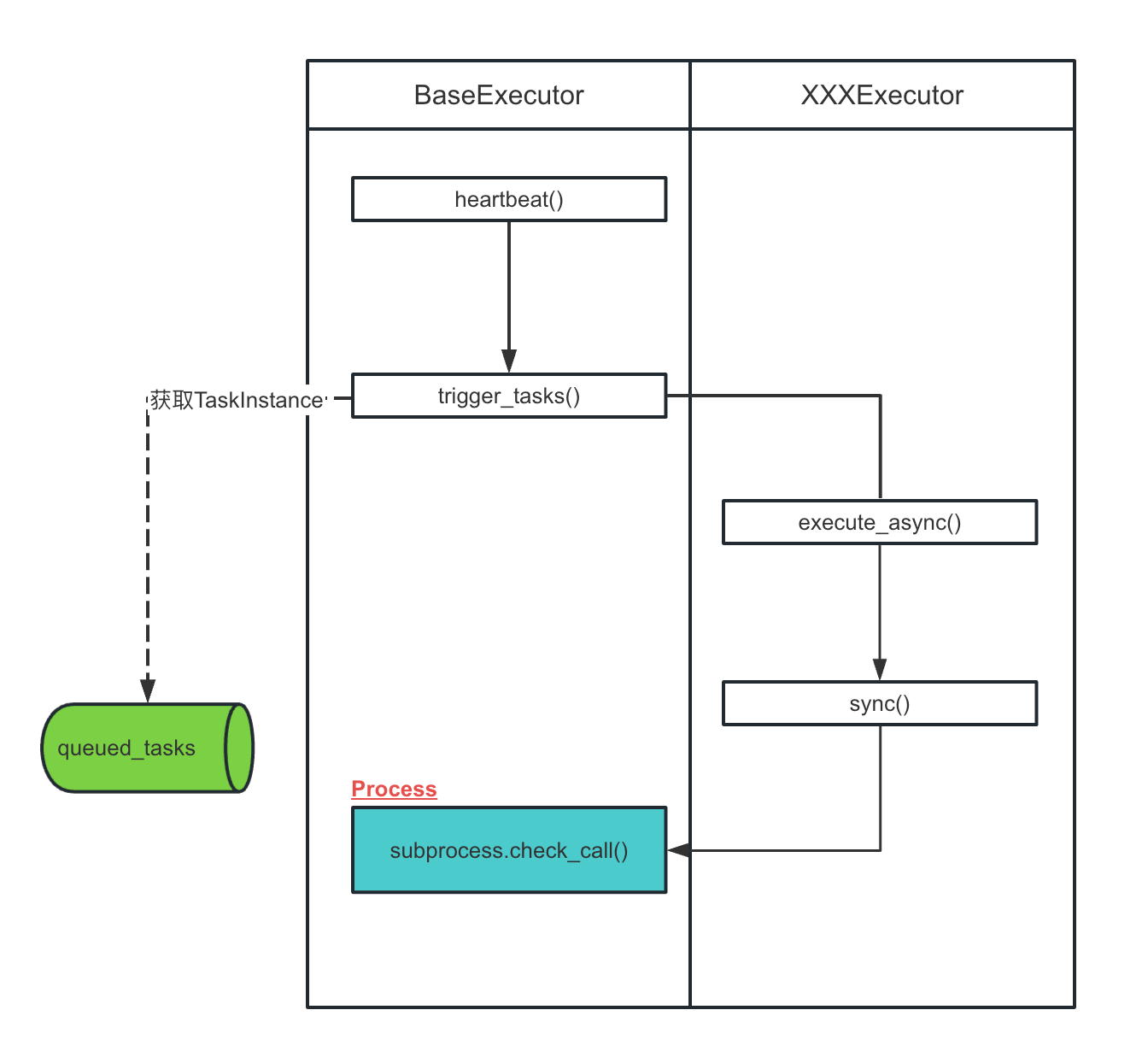
如下图所示,是Airflow源代码中Executor涉及到的关键步骤,下面我们会对这些关键的函数源码展开剖析。
我们知道Airflow启动时,默认使用的executor是SequentialExecutor,
class BaseExecutor(LoggingMixin):
"""
Base class to inherit for concrete executors such as Celery, Kubernetes, Local, Sequential, etc.
"""
def heart_beat
def trigger_tasks
def _process_tasks
def queue_command
...
def execute_async
def sync
def end
def terminate
# 其他方法省略...
所以,后面在调用execute_async和sync方法时,就是调用的SequentialExecutor类里的方法。
class SequentialExecutor(BaseExecutor):
def execute_async
def sync
def end
def terminate
# BaseExecutor.heartbeat
它负责发送心跳以触发新的任务。
通过调用
trigger_tasks方法,根据可用的插槽数触发新的任务。调用子类的
sync方法,用于同步执行器的状态。
注意,这个方法需要在子类中实现 sync 方法,以便同步执行器的状态。
文件路径:airflow/airflow/executors/base_executor.py
class BaseExecutor(LoggingMixin):
...
def heartbeat(self) -> None:
...
self.trigger_tasks(open_slots)
...
self.sync()
# BaseExecutor.trigger_tasks
它负责根据可用的插槽数启动排队任务的异步执行。
以下是具体的步骤:
- 按优先级对排队的任务进行排序。
- 遍历排队任务,最多处理
open_slots个任务。 - 如果任务已经在执行器的
running集合中,说明任务可能已经被外部终止但尚未标记为失败,或者由于延迟任务的竞争条件,任务可能在触发处理期间再次被调度。在这种情况下,我们会尝试多次检查任务是否已从running集合中移除。如果尝试次数超过限制,我们放弃并从队列中移除该任务。 - 如果任务不在执行器的
running集合中,将任务添加到task_tuples列表中。 - 如果
task_tuples列表不为空,调用_process_tasks方法处理任务。
这个方法没有返回值。注意,这个方法需要在子类中实现 _process_tasks 方法,以便处理任务。
文件路径:airflow/airflow/executors/base_executor.py
class BaseExecutor(LoggingMixin):
...
def trigger_tasks(self, open_slots: int) -> None:
sorted_queue = self.order_queued_tasks_by_priority()
task_tuples = []
for _ in range(min((open_slots, len(self.queued_tasks)))):
key, (command, _, queue, ti) = sorted_queue.pop(0)
if key in self.running:
attempt = self.attempts[key]
if attempt.can_try_again():
self.log.info("queued but still running; attempt=%s task=%s", attempt.total_tries, key)
continue
self.log.error(
"could not queue task %s (still running after %d attempts)", key, attempt.total_tries
)
del self.attempts[key]
del self.queued_tasks[key]
else:
if key in self.attempts:
del self.attempts[key]
task_tuples.append((key, command, queue, ti.executor_config))
if task_tuples:
self._process_tasks(task_tuples)
# BaseExecutor->_process_tasks
文件路径:airflow/airflow/executors/base_executor.py
_process_tasks 方法负责处理任务。
以下是具体的步骤:
- 遍历
task_tuples列表,每个元素包含任务的键、命令、队列和执行器配置。 - 从
queued_tasks字典中删除任务。 - 调用
execute_async方法异步执行任务。 - 将任务的键添加到
running集合中,表示任务正在运行。
注意,这个方法需要在子类中实现 execute_async 方法,以便异步执行任务。
文件路径:airflow/airflow/executors/base_executor.py
class BaseExecutor(LoggingMixin):
...
def _process_tasks(self, task_tuples: list[TaskTuple]) -> None:
for key, command, queue, executor_config in task_tuples:
del self.queued_tasks[key]
self.execute_async(key=key, command=command, queue=queue, executor_config=executor_config)
self.running.add(key)
# SequentialExecutor.execute_async
由于execute_async方法是在BaseExecutor的子类中调用执行,所以我们需要分析其子类里的execute_async方法。继承BaseExecutor的子类有LocalExecutor、SequentialExecutor,其中SequentialExecutor是 Airflow 默认的执行器。它会按照顺序一个接一个地执行任务,也就是说,在一个任务完成之前,不会启动下一个任务。
下面,我们分析SequentialExecutor中的execute_async方法:
以下是具体的步骤:
- 定义方法参数,包括任务实例键
key、执行命令command、队列名称queue和执行器配置executor_config。 - 调用
validate_airflow_tasks_run_command方法验证执行命令。这个方法确保传入的命令以 "airflow tasks run" 开头,以防止执行意外的命令。 - 将任务实例键和执行命令作为元组添加到
commands_to_run列表中。这个列表用于存储等待执行的任务命令。
这个方法没有返回值。注意,虽然方法名为 execute_async,但实际上它并不异步执行任务。任务的实际执行是在 SequentialExecutor 的 sync 方法中进行的,该方法会顺序执行 commands_to_run 列表中的任务。
文件路径:airflow/airflow/executors/sequential_executor.py
class SequentialExecutor(BaseExecutor):
....
def execute_async(
self,
key: TaskInstanceKey,
command: CommandType,
queue: str | None = None,
executor_config: Any | None = None,
) -> None:
self.validate_airflow_tasks_run_command(command)
self.commands_to_run.append((key, command))
# SequentialExecutor.sync
它负责顺序执行 commands_to_run 列表中的任务。
以下是具体的步骤:
- 遍历
commands_to_run列表,获取任务实例键key和执行命令command。 - 记录日志,表示正在执行命令。
- 使用
subprocess.check_call函数执行命令。close_fds=True参数表示在执行子进程前关闭所有文件描述符,这有助于防止文件描述符泄漏。 - 如果命令执行成功,调用
success方法更新任务实例键的状态。 - 如果命令执行失败(抛出
subprocess.CalledProcessError异常),调用fail方法更新任务实例键的状态,并记录错误日志。 - 清空
commands_to_run列表,表示所有任务已经执行完成。
注意,这个方法是顺序执行任务的,即在一个任务完成之前,不会启动下一个任务。
文件路径:airflow/airflow/executors/sequential_executor.py
class SequentialExecutor(BaseExecutor):
....
def sync(self) -> None:
for key, command in self.commands_to_run:
self.log.info("Executing command: %s", command)
try:
subprocess.check_call(command, close_fds=True)
self.success(key)
except subprocess.CalledProcessError as e:
self.fail(key)
self.log.error("Failed to execute task %s.", e)
self.commands_to_run = []
这里command的格式通过Airflow的日志打印如下,就是一个本地python文件的执行。
Executing command: ['airflow', 'tasks', 'run', 'tutorial_dag', 'extract', 'manual__2023-11-07T12:16:02.851026+00:00', '--local', '--subdir', '/airflow/example_dags/tutorial_dag.py']
这里使用的命令是airflow的airflow tasks run命令,参数如下。
airflow tasks run -h
Usage: airflow tasks run [-h] [--cfg-path CFG_PATH] [-d {wait,check,ignore}] [-f] [-A] [-i] [-I] [-N] [-l] [--map-index MAP_INDEX] [-m] [-p PICKLE] [--pool POOL]
[--read-from-db] [--ship-dag] [-S SUBDIR] [-v]
dag_id task_id execution_date_or_run_id
Run a single task instance
Positional Arguments:
dag_id The id of the dag
task_id The id of the task
execution_date_or_run_id
The execution_date of the DAG or run_id of the DAGRun
Options:
-h, --help show this help message and exit
--cfg-path CFG_PATH Path to config file to use instead of airflow.cfg
-d, --depends-on-past {wait,check,ignore}
Determine how Airflow should deal with past dependencies. The default action is `check`, Airflow will check if the past dependencies are met for the tasks having `depends_on_past=True` before run them, if `ignore` is provided, the past dependencies will be ignored, if `wait` is provided and `depends_on_past=True`, Airflow will wait the past dependencies until they are met before running or skipping the task
-f, --force Ignore previous task instance state, rerun regardless if task already succeeded/failed
-A, --ignore-all-dependencies
Ignores all non-critical dependencies, including ignore_ti_state and ignore_task_deps
-i, --ignore-dependencies
Ignore task-specific dependencies, e.g. upstream, depends_on_past, and retry delay dependencies
-I, --ignore-depends-on-past
Deprecated -- use `--depends-on-past ignore` instead. Ignore depends_on_past dependencies (but respect upstream dependencies)
-N, --interactive Do not capture standard output and error streams (useful for interactive debugging)
-l, --local Run the task using the LocalExecutor
--map-index MAP_INDEX
Mapped task index
-m, --mark-success Mark jobs as succeeded without running them
-p, --pickle PICKLE Serialized pickle object of the entire dag (used internally)
--pool POOL Resource pool to use
--read-from-db Read dag from DB instead of dag file
--ship-dag Pickles (serializes) the DAG and ships it to the worker
-S, --subdir SUBDIR File location or directory from which to look for the dag. Defaults to '[AIRFLOW_HOME]/dags' where [AIRFLOW_HOME] is the value you set for 'AIRFLOW_HOME' config you set in 'airflow.cfg'
-v, --verbose Make logging output more verbose
该命令调用的函数如下。
# task_run
这段代码定义了一个名为task_run的函数,它用于运行一个单独的任务实例。这个函数接受两个参数:args和dag。args是一个包含命令行参数的对象,dag是一个可选的DAG对象,默认值为None。
函数的主要目的是根据提供的参数执行一个Airflow任务,并返回任务的执行结果。在执行任务之前,它会进行一些参数检查和设置,例如检查--local和--raw选项是否同时使用,加载自定义Airflow配置等。
在函数内部,首先根据提供的参数获取DAG对象。然后,根据DAG对象和任务ID获取任务实例。接下来,根据任务实例和其他参数获取任务实例(TaskInstance)。接着,初始化任务实例的运行上下文。
在运行任务之前,会重新配置ORM(Object-Relational Mapping,对象关系映射)以使用NullPool,以避免在处理大量并发任务时出现数据库连接限制问题。
最后,根据args.interactive参数的值,以交互式或非交互式方式运行任务(调用_run_task_by_selected_method方法),并返回任务的执行结果。在运行任务之后,会触发监听器管理器的before_stopping钩子。
文件路径:airflow/airflow/cli/commands/task_command.py
@cli_utils.action_cli(check_db=False)
def task_run(args, dag: DAG | None = None) -> TaskReturnCode | None:
if args.local and args.raw:
raise AirflowException(
"Option --raw and --local are mutually exclusive. "
"Please remove one option to execute the command."
)
if args.raw:
unsupported_options = [o for o in RAW_TASK_UNSUPPORTED_OPTION if getattr(args, o)]
if unsupported_options:
unsupported_raw_task_flags = ", ".join(f"--{o}" for o in RAW_TASK_UNSUPPORTED_OPTION)
unsupported_flags = ", ".join(f"--{o}" for o in unsupported_options)
raise AirflowException(
"Option --raw does not work with some of the other options on this command. "
"You can't use --raw option and the following options: "
f"{unsupported_raw_task_flags}. "
f"You provided the option {unsupported_flags}. "
"Delete it to execute the command."
)
if dag and args.pickle:
raise AirflowException("You cannot use the --pickle option when using DAG.cli() method.")
if args.cfg_path:
with open(args.cfg_path) as conf_file:
conf_dict = json.load(conf_file)
if os.path.exists(args.cfg_path):
os.remove(args.cfg_path)
conf.read_dict(conf_dict, source=args.cfg_path)
settings.configure_vars()
settings.MASK_SECRETS_IN_LOGS = True
get_listener_manager().hook.on_starting(component=TaskCommandMarker())
if args.pickle:
print(f"Loading pickle id: {args.pickle}")
_dag = get_dag_by_pickle(args.pickle)
elif not dag:
_dag = get_dag(args.subdir, args.dag_id, args.read_from_db)
else:
_dag = dag
task = _dag.get_task(task_id=args.task_id)
ti, _ = _get_ti(task, args.map_index, exec_date_or_run_id=args.execution_date_or_run_id, pool=args.pool)
ti.init_run_context(raw=args.raw)
hostname = get_hostname()
log.info("Running %s on host %s", ti, hostname)
settings.reconfigure_orm(disable_connection_pool=True)
task_return_code = None
try:
if args.interactive:
task_return_code = _run_task_by_selected_method(args, _dag, ti)
else:
with _move_task_handlers_to_root(ti), _redirect_stdout_to_ti_log(ti):
task_return_code = _run_task_by_selected_method(args, _dag, ti)
if task_return_code == TaskReturnCode.DEFERRED:
_set_task_deferred_context_var()
finally:
try:
get_listener_manager().hook.before_stopping(component=TaskCommandMarker())
except Exception:
pass
return task_return_code
这里调用了_run_task_by_selected_method关键方法。
# _run_task_by_selected_method
这个函数_run_task_by_selected_method用于根据所选的模式运行Airflow任务。它接受3个参数:args,dag和ti。args是一个包含命令行参数的对象,dag是一个DAG对象,ti是一个任务实例(TaskInstance)或TaskInstancePydantic对象。
函数的主要目的是根据提供的参数选择合适的方式执行Airflow任务。目前支持3种模式:
- 使用LocalTaskJob运行任务。
- 作为原始任务(raw task)运行。
- 通过执行器(executor)运行任务。
根据args.local和args.raw参数的值,函数会分别调用_run_task_by_local_task_job、_run_raw_task或_run_task_by_executor函数来执行任务。最后,函数返回执行结果,如果没有返回值,则返回None。
文件路径:airflow/airflow/cli/commands/task_command.py
def _run_task_by_selected_method(
args, dag: DAG, ti: TaskInstance | TaskInstancePydantic
) -> None | TaskReturnCode:
if TYPE_CHECKING:
assert not isinstance(ti, TaskInstancePydantic) # Wait for AIP-44 implementation to complete
if args.local:
return _run_task_by_local_task_job(args, ti)
if args.raw:
return _run_raw_task(args, ti)
_run_task_by_executor(args, dag, ti)
return None
def _run_raw_task(args, ti: TaskInstance) -> None | TaskReturnCode:
"""Run the main task handling code."""
return ti._run_raw_task(
mark_success=args.mark_success,
job_id=args.job_id,
pool=args.pool,
)
我们分析其中的_run_raw_task方法,其最终是通过TaskInstance的_run_raw_task方法实现
函数的主要目的是在原始模式下执行Airflow任务,并在任务完成后更新任务状态并运行适当的回调。
在_run_raw_task函数中,任务的实际执行是通过调用self._execute_task_with_callbacks(context, test_mode, session=session)来完成的。这个方法将任务的上下文、测试模式和数据库会话作为参数,并执行任务。在执行任务时,它还会处理任务执行过程中的回调函数。
文件路径:airflow/airflow/models/taskinstance.py
@provide_session
@Sentry.enrich_errors
def _run_raw_task(
self,
mark_success: bool = False,
test_mode: bool = False,
job_id: str | None = None,
pool: str | None = None,
raise_on_defer: bool = False,
session: Session = NEW_SESSION,
) -> TaskReturnCode | None:
if TYPE_CHECKING:
assert self.task
self.test_mode = test_mode
self.refresh_from_task(self.task, pool_override=pool)
self.refresh_from_db(session=session)
self.job_id = job_id
self.hostname = get_hostname()
self.pid = os.getpid()
if not test_mode:
session.merge(self)
session.commit()
actual_start_date = timezone.utcnow()
Stats.incr(f"ti.start.{self.task.dag_id}.{self.task.task_id}", tags=self.stats_tags)
# Same metric with tagging
Stats.incr("ti.start", tags=self.stats_tags)
# Initialize final state counters at zero
for state in State.task_states:
Stats.incr(
f"ti.finish.{self.task.dag_id}.{self.task.task_id}.{state}",
count=0,
tags=self.stats_tags,
)
# Same metric with tagging
Stats.incr(
"ti.finish",
count=0,
tags={**self.stats_tags, "state": str(state)},
)
with set_current_task_instance_session(session=session):
self.task = self.task.prepare_for_execution()
context = self.get_template_context(ignore_param_exceptions=False)
try:
if not mark_success:
self._execute_task_with_callbacks(context, test_mode, session=session)
if not test_mode:
self.refresh_from_db(lock_for_update=True, session=session)
self.state = TaskInstanceState.SUCCESS
except ....
# 各种异常处理代码...
finally:
Stats.incr(f"ti.finish.{self.dag_id}.{self.task_id}.{self.state}", tags=self.stats_tags)
# Same metric with tagging
Stats.incr("ti.finish", tags={**self.stats_tags, "state": str(self.state)})
# Recording SKIPPED or SUCCESS
self.clear_next_method_args()
self.end_date = timezone.utcnow()
_log_state(task_instance=self)
self.set_duration()
_run_finished_callback(callbacks=self.task.on_success_callback, context=context)
if not test_mode:
session.add(Log(self.state, self))
session.merge(self).task = self.task
if self.state == TaskInstanceState.SUCCESS:
self._register_dataset_changes(session=session)
session.commit()
if self.state == TaskInstanceState.SUCCESS:
get_listener_manager().hook.on_task_instance_success(
previous_state=TaskInstanceState.RUNNING, task_instance=self, session=session
)
return None
这里调用了关键方法:_execute_task_with_callbacks
# TaskInstance._execute_task_with_callbacks
_execute_task_with_callbacks函数用于准备任务实例并执行任务。它接受以下参数:
context:任务上下文(Context)对象,包含任务执行所需的信息。test_mode:布尔值,表示是否在测试模式下运行任务,默认值为False。session:SQLAlchemy ORM Session对象。
函数的主要步骤如下:
- 定义一个信号处理器
signal_handler,用于处理任务在执行过程中收到的SIGTERM信号。当接收到信号时,它会调用任务的on_kill方法,并引发一个AirflowTaskTerminated异常。 - 为任务实例清除XCom数据(如果没有下一个要执行的方法)。
- 使用
Stats.timer记录任务执行的时间。 - 设置任务对象的参数。
- 渲染任务的模板,并在非测试模式下,将渲染后的任务实例字段保存到数据库中。
- 将上下文导出到环境变量,以便操作符使用。
- 调用任务的
pre_execute回调函数。 - 调用
_run_execute_callback方法执行on_execute回调。 - 调用
get_listener_manager().hook.on_task_instance_running方法触发任务实例运行事件。 - 使用
set_current_context上下文管理器执行任务,并获取任务执行结果。 - 调用任务的
post_execute回调函数。 - 如果任务上下文中包含
map_index_template,则使用Jinja环境渲染它,并将渲染结果保存到self.rendered_map_index属性中。 - 更新任务执行成功的统计信息。
在整个过程中,函数会处理任务执行过程中的各种回调函数,以及在任务执行前后更新任务实例的状态。
文件路径:airflow/airflow/cli/commands/task_command.py
def _execute_task_with_callbacks(self, context: Context, test_mode: bool = False, *, session: Session):
"""Prepare Task for Execution."""
from airflow.models.renderedtifields import RenderedTaskInstanceFields
if TYPE_CHECKING:
assert self.task
parent_pid = os.getpid()
def signal_handler(signum, frame):
pid = os.getpid()
if pid != parent_pid:
os._exit(1)
return
self.log.error("Received SIGTERM. Terminating subprocesses.")
self.task.on_kill()
raise AirflowTaskTerminated("Task received SIGTERM signal")
signal.signal(signal.SIGTERM, signal_handler)
if not self.next_method:
self.clear_xcom_data()
with Stats.timer(f"dag.{self.task.dag_id}.{self.task.task_id}.duration"), Stats.timer(
"task.duration", tags=self.stats_tags
):
self.task.params = context["params"]
with set_current_context(context):
dag = self.task.get_dag()
if dag is not None:
jinja_env = dag.get_template_env()
else:
jinja_env = None
task_orig = self.render_templates(context=context, jinja_env=jinja_env)
if not test_mode:
rtif = RenderedTaskInstanceFields(ti=self, render_templates=False)
RenderedTaskInstanceFields.write(rtif)
RenderedTaskInstanceFields.delete_old_records(self.task_id, self.dag_id)
airflow_context_vars = context_to_airflow_vars(context, in_env_var_format=True)
os.environ.update(airflow_context_vars)
if not self.next_method:
self.log.info(
"Exporting env vars: %s",
" ".join(f"{k}={v!r}" for k, v in airflow_context_vars.items()),
)
self.task.pre_execute(context=context) # type: ignore[union-attr]
self._run_execute_callback(context, self.task)
get_listener_manager().hook.on_task_instance_running(
previous_state=TaskInstanceState.QUEUED, task_instance=self, session=session
)
with set_current_context(context):
result = self._execute_task(context, task_orig)
self.task.post_execute(context=context, result=result) # type: ignore[union-attr]
if jinja_env is not None and (template := context.get("map_index_template")) is not None:
rendered_map_index = self.rendered_map_index = jinja_env.from_string(template).render(context)
self.log.info("Map index rendered as %s", rendered_map_index)
Stats.incr(f"operator_successes_{self.task.task_type}", tags=self.stats_tags)
Stats.incr("operator_successes", tags={**self.stats_tags, "task_type": self.task.task_type})
Stats.incr("ti_successes", tags=self.stats_tags)
这里调用了关键方法:_execute_task。
# TaskInstance._execute_task
def _execute_task(self, context, task_orig):
"""
Execute Task (optionally with a Timeout) and push Xcom results.
:param context: Jinja2 context
:param task_orig: origin task
"""
return _execute_task(self, context, task_orig)
_execute_task函数用于执行任务并在任务完成后推送XCom结果。它接受以下参数:
task_instance:任务实例(TaskInstance)或TaskInstancePydantic对象。context:任务上下文(Context)对象,包含任务执行所需的信息。task_orig:原始任务(Operator)对象。
函数的主要步骤如下:
- 获取要执行的任务对象
task_to_execute。 - 检查任务是否为MappedOperator类型,如果是,则抛出异常。
- 根据任务实例的
next_method属性,选择要执行的任务方法(execute或resume_execution)以及相应的参数。 - 定义一个内部函数
_execute_callable,用于实际执行任务方法,并处理任务执行过程中的SystemExit异常。 - 如果任务具有执行超时限制,使用
timeout上下文管理器确保任务在超时后被终止。在处理超时时,调用任务的on_kill方法并引发AirflowTaskTimeout异常。 - 如果任务没有执行超时限制,直接调用
_execute_callable函数执行任务方法。 - 根据任务的
do_xcom_push属性,决定是否将任务执行结果推送到XCom。如果任务返回结果并且do_xcom_push为True,则将结果推送到XCom。如果任务具有multiple_outputs属性,则需要对结果进行额外的检查和处理。 - 调用
_record_task_map_for_downstreams函数记录任务映射,以便在下游任务中使用。 - 返回任务执行结果。
在整个过程中,函数会处理任务执行过程中的各种异常情况,并确保任务在超时后被终止。同时,它还会根据任务的属性决定是否将任务执行结果推送到XCom。
def _execute_task(task_instance: TaskInstance | TaskInstancePydantic, context: Context, task_orig: Operator):
task_to_execute = task_instance.task
if TYPE_CHECKING:
assert task_to_execute
if isinstance(task_to_execute, MappedOperator):
raise AirflowException("MappedOperator cannot be executed.")
execute_callable_kwargs: dict[str, Any] = {}
execute_callable: Callable
if task_instance.next_method:
if task_instance.next_method == "execute":
if not task_instance.next_kwargs:
task_instance.next_kwargs = {}
task_instance.next_kwargs[f"{task_to_execute.__class__.__name__}__sentinel"] = _sentinel
execute_callable = task_to_execute.resume_execution
execute_callable_kwargs["next_method"] = task_instance.next_method
execute_callable_kwargs["next_kwargs"] = task_instance.next_kwargs
else:
execute_callable = task_to_execute.execute
if execute_callable.__name__ == "execute":
execute_callable_kwargs[f"{task_to_execute.__class__.__name__}__sentinel"] = _sentinel
def _execute_callable(context, **execute_callable_kwargs):
try:
log.info("::endgroup::")
return execute_callable(context=context, **execute_callable_kwargs)
except SystemExit as e:
if e.code is not None and e.code != 0:
raise
return None
finally:
# Print a marker post execution for internals of post task processing
log.info("::group::Post task execution logs")
if task_to_execute.execution_timeout:
if task_instance.next_method and task_instance.start_date:
timeout_seconds = (
task_to_execute.execution_timeout - (timezone.utcnow() - task_instance.start_date)
).total_seconds()
else:
timeout_seconds = task_to_execute.execution_timeout.total_seconds()
try:
if timeout_seconds <= 0:
raise AirflowTaskTimeout()
with timeout(timeout_seconds):
result = _execute_callable(context=context, **execute_callable_kwargs)
except AirflowTaskTimeout:
task_to_execute.on_kill()
raise
else:
result = _execute_callable(context=context, **execute_callable_kwargs)
with create_session() as session:
if task_to_execute.do_xcom_push:
xcom_value = result
else:
xcom_value = None
if xcom_value is not None: # If the task returns a result, push an XCom containing it.
if task_to_execute.multiple_outputs:
if not isinstance(xcom_value, Mapping):
raise AirflowException(
f"Returned output was type {type(xcom_value)} "
"expected dictionary for multiple_outputs"
)
for key in xcom_value.keys():
if not isinstance(key, str):
raise AirflowException(
"Returned dictionary keys must be strings when using "
f"multiple_outputs, found {key} ({type(key)}) instead"
)
for key, value in xcom_value.items():
task_instance.xcom_push(key=key, value=value, session=session)
task_instance.xcom_push(key=XCOM_RETURN_KEY, value=xcom_value, session=session)
_record_task_map_for_downstreams(
task_instance=task_instance, task=task_orig, value=xcom_value, session=session
)
return result
这里默认调用的是execute方法执行任务实例。execute方法是BaseOperator类及其子类的方法。BaseOperator是所有Airflow操作符的基类。每个Airflow操作符都必须实现execute方法,该方法定义了当操作符被调度执行时应该执行的具体任务。
例如,PythonOperator是BaseOperator的一个子类,它的execute方法执行传入的Python函数;BashOperator的execute方法执行Bash命令;BranchPythonOperator的execute方法执行Python函数并返回要跳转到的任务等。
至此,我们完整地分析了Airflow的流程引擎,从它的流程定义、解析和运行等方面进行源码分析。
