数据管理机制就是流程管理里面的信息流,它描述了如何在业务流程执行过程定义和管理数据。它们可分为四种:
数据可见性:与流程中数据元素的范围和可见性有关的模式。
数据交互(流程内):这种模式侧重于流程中任务之间的数据通信方式。
数据传输(流程外):这种模式考虑了数据元素在流程之间实际传输的方式,以及流程与外部环境之间的传输机制。
基于数据的路由:描述数据元素影响流程其他方面运行的方式的模式,特别是控制流视角。
# 数据可见性
数据可见性模式定义了数据元素与其可见区域的范围。数据元素通常是在流程的上下文中定义的,这种绑定通常定义了数据元素对其他流程可见并能被其他流程使用的范围。这一组有八种不同的模式,它们描述了不同程度的数据范围,具体如下:
环境数据(Environment Data):
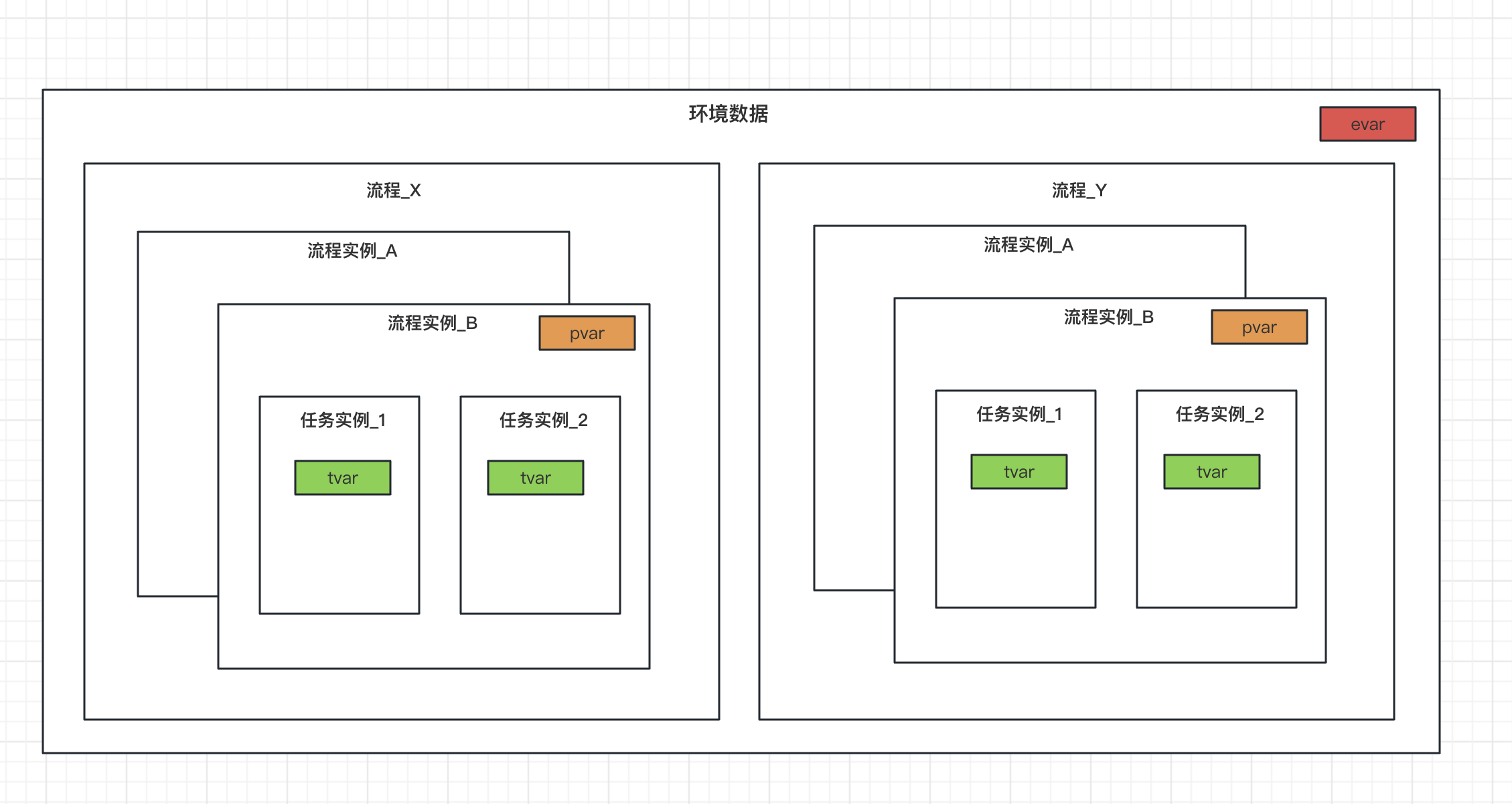
其数据元素也叫环境变量。对应于在流程上下文之外定义但在执行过程中可在流程内访问的数据元素。环境数据元素有可能被不同流程的不同流程实例下的不同实例访问。也就是说所有流程产生的流程实例都可以访问数据元素。它的生命周期与用户相同。下图通过数据元素evar展示了环境数据模式,流程X和流程Y的所有流程实例里的任务实例都可以访问evar。
流程数据(Process Data):
其数据元素也叫流程变量。对应的数据元素在给定流程实例的所有任务中都可访问。下图通过数据元素 pvar 展示了流程数据,流程实例B里的两个任务实例_1和任务实例_2都可以访问pvar。
任务数据(Task Data):
其数据元素也叫局部变量。相当于在特定任务上下文中定义的数据元素。它通常只能在给定的任务实例中访问,生命周期与绑定它的任务实例相同。图 2.8 中与任务 A 相关联的变量 tvar 就说明了任务数据模式,该变量只能在该任务上下文中访问。例如脚本任务重的变量只在当前任务实例生效。
# 数据交互(流程内)
流程内的任务之间可以通过以下两种方式实现数据通信:
- 流程变量:流程实例可以通过前面介绍的pvar变量进行读写来实现通信。
- 基于数据的路由:另一种更灵活的方式是通过下面第四节介绍的变量表达式方式实现对流程实例中任意一个任务输入、输出数据的引用。
# 数据传输(流程外)
# 流程与外部环境之间的数据传输
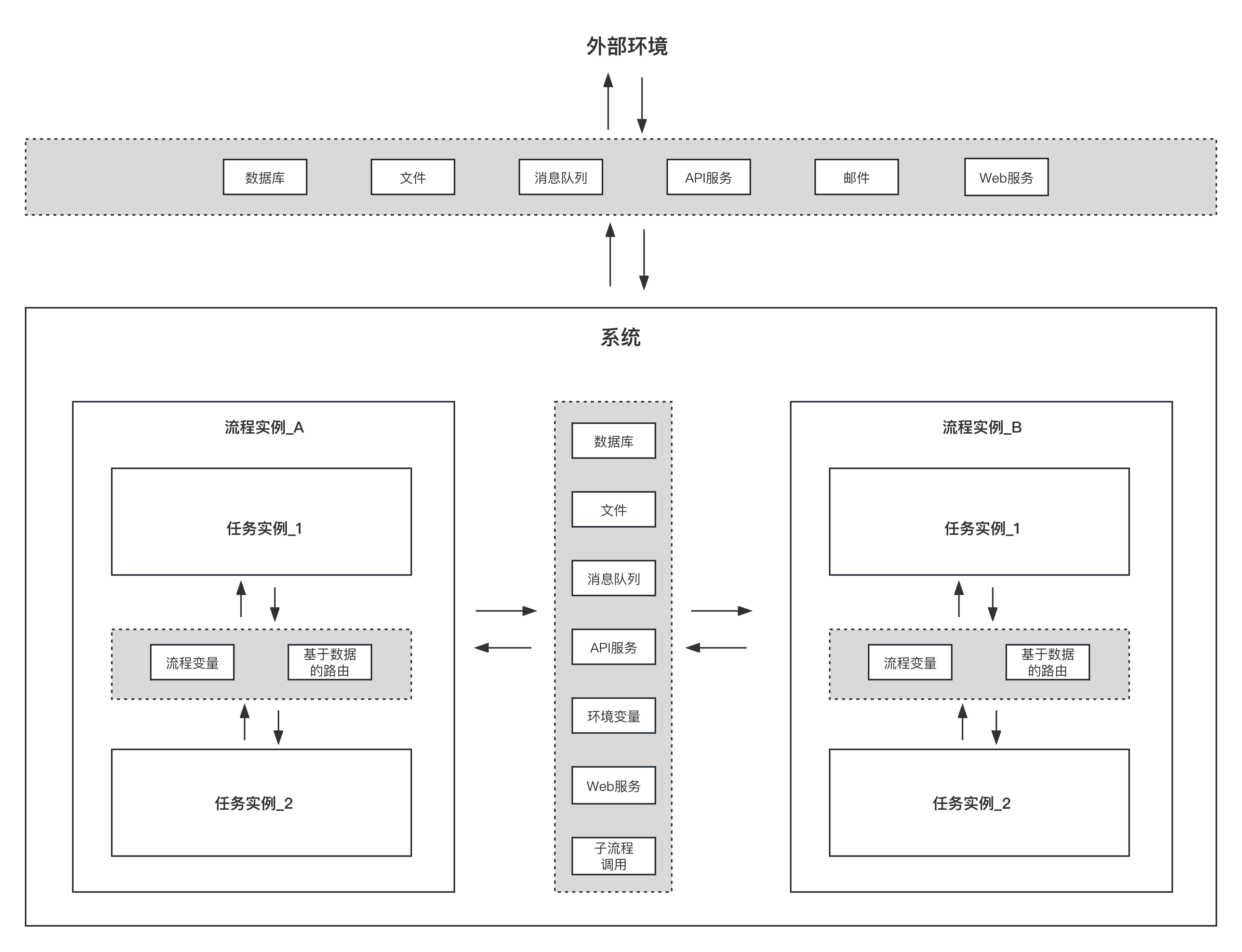
在工作流中,流程与外部环境的数据传输方式主要有以下几种:
- 数据库传输:这是最常见的数据传输方式。流程和外部环境通过共享数据库来传输数据。流程可以查询数据库中的数据,也可以将处理结果写入数据库。
- 文件传输:流程和外部环境可以通过共享文件系统来传输数据。流程可以读取文件中的数据,也可以将处理结果写入文件。
- 消息队列传输:流程和外部环境可以通过消息队列来传输数据。流程可以向消息队列发送消息,也可以从消息队列接收消息。
- API调用:流程可以通过调用外部环境提供的API接口来获取数据或者传输数据。
- 邮件传输:流程可以通过发送邮件的方式,将数据传输给外部环境。
- Web服务:流程可以通过调用外部环境提供的Web服务来获取数据或者传输数据。
以上就是流程与外部环境的主要数据传输方式,实际应用中,可能会根据具体需求,选择一种或者多种方式进行数据传输。
# 流程与流程之间的数据传输
流程与流程之间传输数据也跟上面类似,主要通过以下方式:
- 数据库:流程之间可以通过共享数据库来传输数据。一个流程在数据库中写入数据,另一个流程从数据库中读取数据。
- 消息队列:流程之间也可以通过消息队列来传输数据。一个流程发送消息到队列,另一个流程从队列中接收消息。
- API调用:流程之间可以通过API调用来传输数据。一个流程调用另一个流程的API,将数据作为参数传入。
- 文件交换:流程之间可以通过文件交换来传输数据。一个流程生成一个文件,另一个流程读取这个文件。
- 环境变量:在同一个系统中,流程之间可以通过环境变量来传输数据,一个流程写入环境变量,另一个流程读取环境变量。
- Web服务:流程之间可以通过服务调用来传输数据。一个流程提供一个服务,然后其他流程通过调用这个服务来获取数据。
- 子流程调用:通过子流程任务调用传输数据,父流程可以给子流程传递参数,子流程可以把执行结果输出返回给父流程(注意这里必须是同步方式执行子流程)
下图是流程与外部环境、流程与流程之间以及流程内任务之间的数据传输方式:
# 基于数据的路由
前面我们用JSON的方式定义了流程模型,流程中每个任务的数据结构如下,例如Crontab触发器:
{
"instId": "xxx",
"name": "crontab触发器",
"description": "crontab周期任务",
"template": "crontab",
"positions": [],
"connections": [],
"parameters": {
"expr": {
"label": "expr",
"type": "string",
"value": "*/1 * * * *",
"default": "",
"required": true
}
},
"errorHandler": {},
"loopHandler": {},
"timeout": 0,
"isIgnore": false,
"runtimes": [
{
"parameters": {
"expr": "*/1 * * * *"
},
"output": [],
"startAt": "2023-12-01 21:03:11",
"endAt": "2023-12-01 21:03:11",
"error": "",
"status": "done"
}
]
}
每个任务的数据分为定义数据和运行时数据。
- 定义数据:就是最外层的parameters字段,这里定义了任务包含的入参字段。
- 运行时数据:存储在runtimes字段,该字段是一个数组,因为每个任务可能被多次运行,即创建多个任务实例,所以运行时数据会产生多条。每个运行时数据会把运行时的parameters以及输出结果、发生时间给记录下来,运行时的parameters和定义时的parameters可能不一样,因为定义的入参parameters可能是一个变量表达式而非常量,只有在运行时才知道具体的数值。
这里,我们可以看到每个任务实例都有一个instId来标识区分,所以流程中我们可以通过如下的变量表达式来定位引用任务实例的定义数据和运行时数据。
定义数据引用
# 引用某个入参定义的label
{{instId.parameters.key.label}}
# 引用某个入参定义的type
{{instId.parameters.key.type}}
# 引用某个入参定义的value
{{instId.parameters.key.value}}
# 引用某个入参定义的default
{{instId.parameters.key.default}}
运行时数据引用
# 引用某个入参第一次运行时的value值
{{instId.runtimes.0.parameters.key}}
# 引用某个入参第二次运行时的value值
{{instId.runtimes.1.parameters.key}}
# 引用任务实例第一次运行时的输出结果
{{instId.runtimes.0.output}}
# 引用任务实例第一次运行时的开始时间
{{instId.runtimes.0.startAt}}
# 引用任务实例第一次运行时的结束时间
{{instId.runtimes.0.endAt}}
# 引用任务实例第一次运行时的错误信息
{{instId.runtimes.0.error}}
# 引用任务实例第一次运行时的装填
{{instId.runtimes.0.status}}
前面两个是任务数据的引用,如果想引用数据可见性中提到的环境数据和全局数据,则可以通过如下的语法实现:
# 环境数据引用
{{env.var}}
# 全局数据引用
{{process.var}}
上面只是变量表达式语法的简单使用,在实际运行环境里,任务实例的输出结果可能更复杂,可能是一个复杂的Json嵌套结构,例如Output输出的是一个嵌套的Json结构:
{
"name": {"first": "Tom", "last": "Anderson"},
"age":37,
"children": ["Sara","Alex","Jack"],
"fav.movie": "Deer Hunter",
"friends": [
{"first": "Dale", "last": "Murphy", "age": 44, "nets": ["ig", "fb", "tw"]},
{"first": "Roger", "last": "Craig", "age": 68, "nets": ["fb", "tw"]},
{"first": "Jane", "last": "Murphy", "age": 47, "nets": ["ig", "tw"]}
],
"vals": [
{ "a": 1, "b": "data" },
{ "a": 2, "b": true },
{ "a": 3, "b": false },
{ "a": 4, "b": "0" },
{ "a": 5, "b": 0 },
{ "a": 6, "b": "1" },
{ "a": 7, "b": 1 },
{ "a": 8, "b": "true" },
{ "a": 9, "b": false },
{ "a": 10, "b": null },
{ "a": 11 }
]
}
下面样一些特性,我会议上面这个Json输出结果为例子。
# 基础语法支持
{{instId.runtimes.0.output.name.last}} >> "Anderson"
{{instId.runtimes.0.output.age}} >> 37
{{instId.runtimes.0.output.children}} >> ["Sara","Alex","Jack"]
{{instId.runtimes.0.output.children.#}} >> 3
{{instId.runtimes.0.output.children.0}} >> "Sara"
{{instId.runtimes.0.output.children.1}} >> "Alex"
{{instId.runtimes.0.output.friends.#.first}} >> ["Dale","Roger","Jane"]
{{instId.runtimes.0.output.friends.1.last}} >> "Craig"
# 通配符语法支持
表达式里面可以通过*通配符匹配任何字符串,或者通过?通配符匹配一个字符串。
{{instId.runtimes.0.output.child*.2}} >> "Jack"
{{instId.runtimes.0.output.c?ildren.0}} >> "Sara"
# 转义字符语法支持
像一些特殊字符,例如:.、*、?,可以用\来转义。
{{instId.runtimes.0.output.fav\.movie}} >> "Deer Hunter"
# 数组语法支持
使用#字符可以深入挖掘JSON数组,#本身表示数组长度,也可以通过#获取对象数组中的某个字段列表。
{{instId.runtimes.0.output.friends.#}} >> 3
{{instId.runtimes.0.output.friends.#.age}} >> [44,68,47]
# 查询语法支持
可以使用 #(...)查询数组的第一个匹配项,或使用 #(...)#查找所有匹配项。查询支持 ==、!=、<、<=、>、>=比较运算符,以及简单模式匹配 %(类似)和!%(不类似)运算符。
{{instId.runtimes.0.output.friends.#(last=="Murphy").first}} >> "Dale"
{{instId.runtimes.0.output.friends.#(last=="Murphy")#.first}} >> ["Dale","Jane"]
{{instId.runtimes.0.output.friends.#(age>45)#.last}} >> ["Craig","Murphy"]
{{instId.runtimes.0.output.friends.#(first%"D*").last}} >> "Murphy"
{{instId.runtimes.0.output.friends.#(first!%"D*").last}} >> "Craig"
如果要查询非对象数组,例如:
{{instId.runtimes.0.output.children.#(!%"*a*")}} >> "Alex"
{{instId.runtimes.0.output.children.#(%"*a*")#}} >> ["Sara","Jack"]
甚至可以支持一些嵌套查询的语法:
{{instId.runtimes.0.output.friends.#(nets.#(=="fb"))#.first}} >> ["Dale","Roger"]
~(波形符)运算符会在比较之前将值转换为布尔值。
例如,要查询所有 true 、 false 和null值:
{{instId.runtimes.0.output.vals.#(b==~true)#.a}} >> [2,6,7,8]
{{instId.runtimes.0.output.vals.#(b==~false)#.a}} >> [3,4,5,9,10,11]
{{instId.runtimes.0.output.vals.#(b==~null)#.a}} >> [10,11]
# 修饰符语法支持
修饰符类似于把一些常用的操作,例如数组反转、移除空格等操作包装成一个函数调用的方式使用,例如:
@reverse: 反转数组成员@trim: 删除json中的所有空格@keys: 返回对象的key列表@values: 返回对象的value列表@tostr: 将json转换成字符串@fromstr: 将字符串转换成json
{{instId.runtimes.0.output.children|@reverse}} >> ["Jack","Alex","Sara"]
{{instId.runtimes.0.output.children|@reverse|0}} >> "Jack"
# 自定义修饰符
如果一些内置的修饰符不满足需求,引擎甚至可以支持用户自定义修饰符,提高引擎的变量表达式的语法拓展性。
例如,实现字符串大小写转换的修饰符。
engine.AddModifier("case", func(json, arg string) string {
if arg == "upper" {
return strings.ToUpper(json)
}
if arg == "lower" {
return strings.ToLower(json)
}
return json
})
使用:
{{instId.runtimes.0.output.children.@case:upper}} >> ["SARA","ALEX","JACK"]
{{instId.runtimes.0.output.children.@case:lower.@reverse}} >> ["jack","alex","sara"]
前面介绍的所有语法,都是实现了对数据元素的读操作,并不涉及修改,如果想要实现对数据元素的写操作,可以结合前面设计的【变量读写】任务类型来实现对数据元素读写操作。