# 概述
工作流中的异常是指在执行过程中遇到的预期之外的事件。这些事件可能是因为现实世界的活动和它们的形式表示之间的差异导致的。异常并不是错误,而是被认为是偏离预期的事件,或者是在原始过程模型中没有被解释的事件。这类事件在实际的工作环境中经常发生。
而且,异常是流程的基本组成部分,实际上在企业执行的日常任务中,很大一部分可以归类为异常处理工作。因此,工作流程的每个执行实例都很可能包含一些与计划的偏差。这种偏离计划的情况不应被视为错误,而是作为工作活动的一个自然和有价值的部分,为学习提供了机会,从而为未来的实例制定计划。
# 异常处理的一般框架
异常处理的一般框架可以描述如下:
# 1、异常的类型
异常是在流程执行过程中发生的特定时间点的独特的、可识别的事件。这种情况被认为是可以立即检测到的,并具有特定的类型。
工作流中的异常类型主要有以下五种:
- 任务故障:当前正在执行的任务无法在其当前执行状态下继续执行或进一步前进。这可能是由于用户发起的程序终止、与任务相关的硬件、软件或网络资源的故障,或用户指示相关的任务应该被视为失败而不是成功完成。
- 截止日期到期:在达到期限且任务尚未启动或完成时,就会触发异常。
- 资源不可用性:任务在执行期间需要访问一个或多个资源,如果这些资源在启动时无法使用,那么通常不可能继续进行。资源不可用性可能涉及某种形式的升级或人工干预。
- 外部触发器:这是指示任务的常见方法,即发生了影响任务的事件,需要某种形式的处理。这些触发器可以来自内部和外部来源,并且可能是非链接的任务。
- 约束违反:在流程模型中使用约束是指定流程中控制流、数据或资源元素上的操作不变量的一种常用方法,这些元素需要进行维护,以确保保持其完整性和操作一致性。
如果从异常影响的范围来划分,可以分为以下两个层次:
# 任务级别的异常处理
从资源的角度分析,我们可以看到任务的生命周期里一共有6种状态,分别是:等待分配资源(offered)、指派一个资源负责执行(allocated)、开始(started)、失败(failed)、完成(completed),如下图所示:。
当任务发生异常时,可能出出现如下15种可能的状态转换。
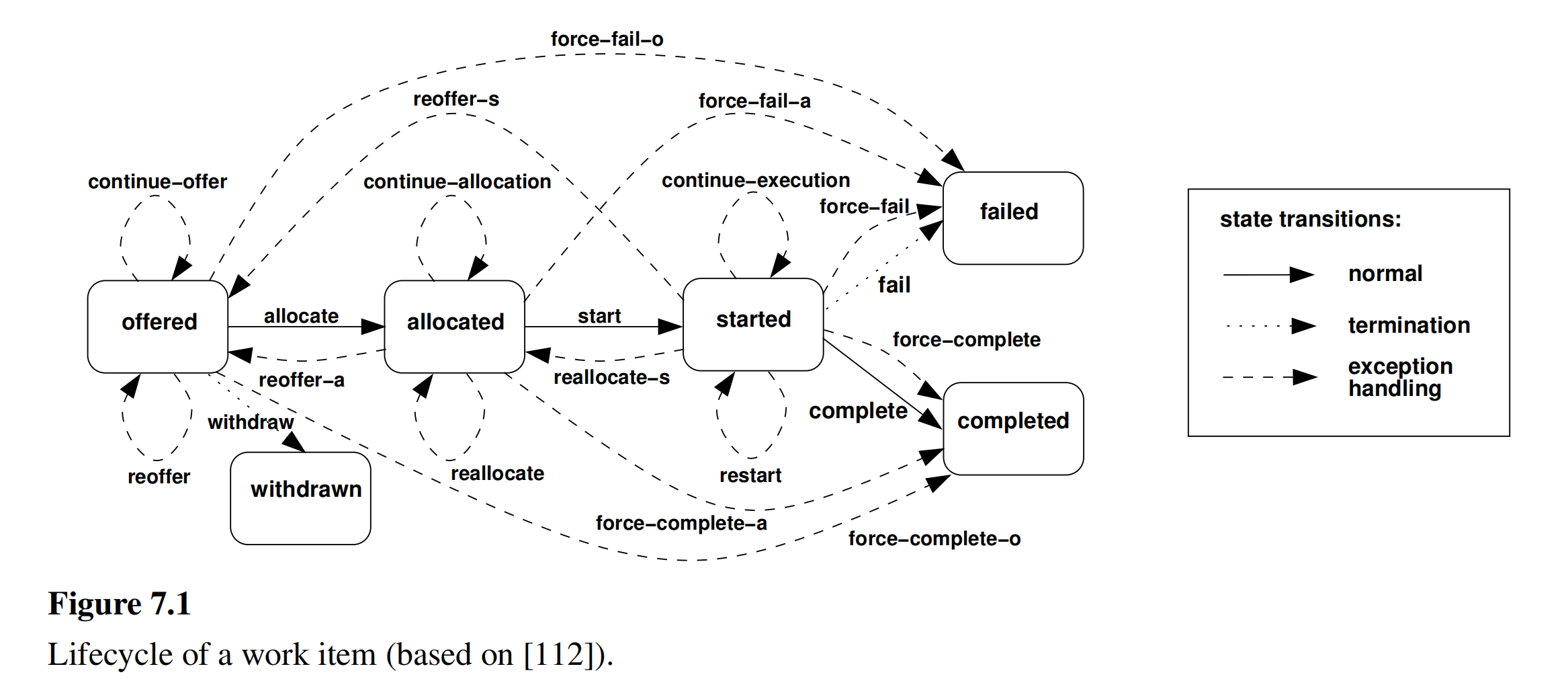
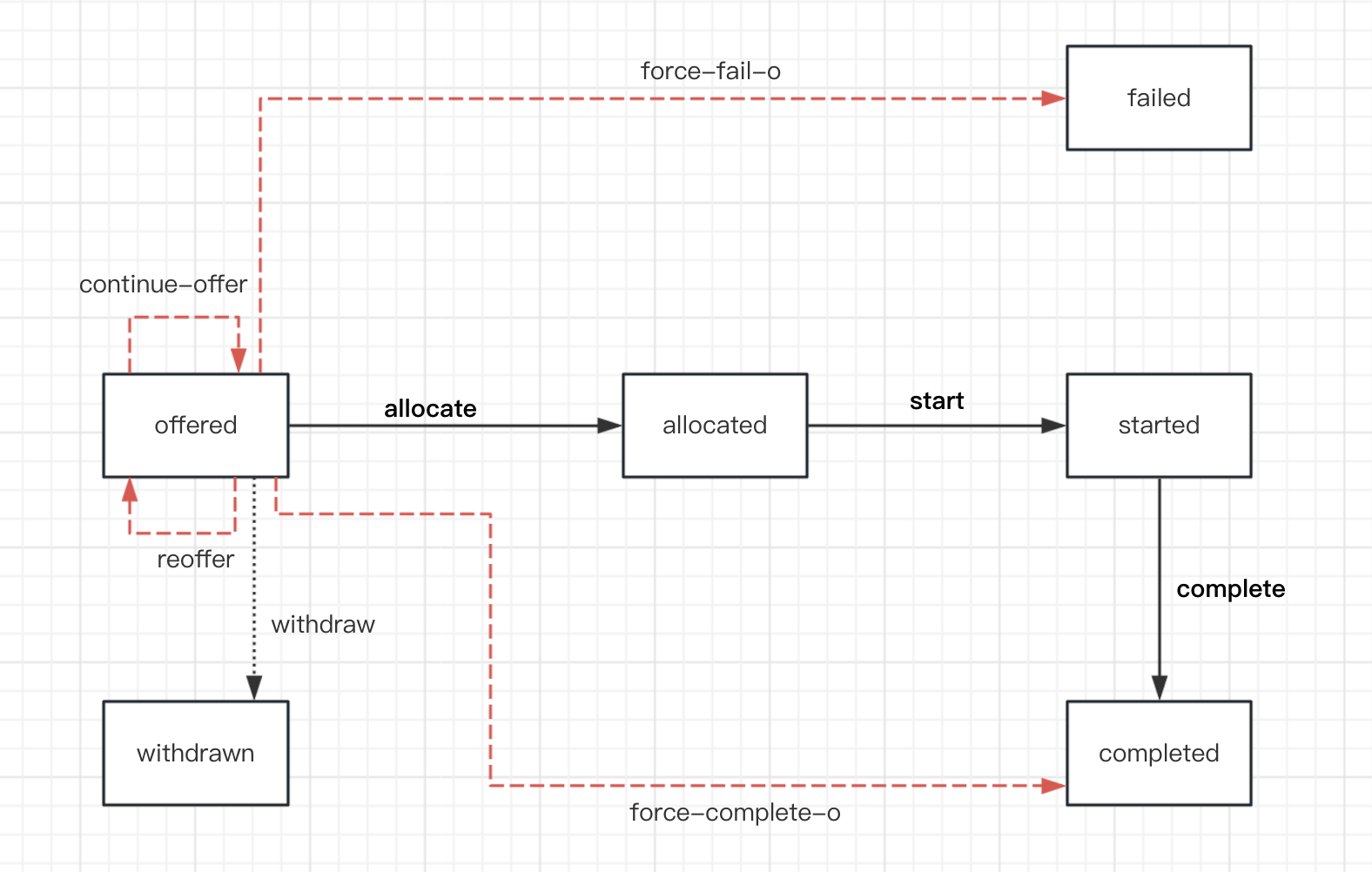
如下图所示,当任务处于offered状态时,如果发生异常,它有如下四种可能的状态变换:
| 缩写 | 状态变换 | 说明 |
|---|---|---|
| OCO | continue-offer | 任务已提供给一个或多个资源,其状态不会因异常而改变。 |
| ORO | reoffer | 任务已提供给一个或多个资源,但由于例外情况,这些提供被撤回,任务再次提供给一个或多个资源(这些资源不一定与之前提供给它的资源相同)。 |
| OFF | force-fail-o | 任务已提供给一个或多个资源,这些提供被撤回,任务的状态变为失败,此路径上的任何后续任务都不会触发。 |
| OFC | force-complete-o | 该任务已提供给一个或多个资源,这些提供被撤回,任务的状态变为已完成,所有后续任务都被触发 |
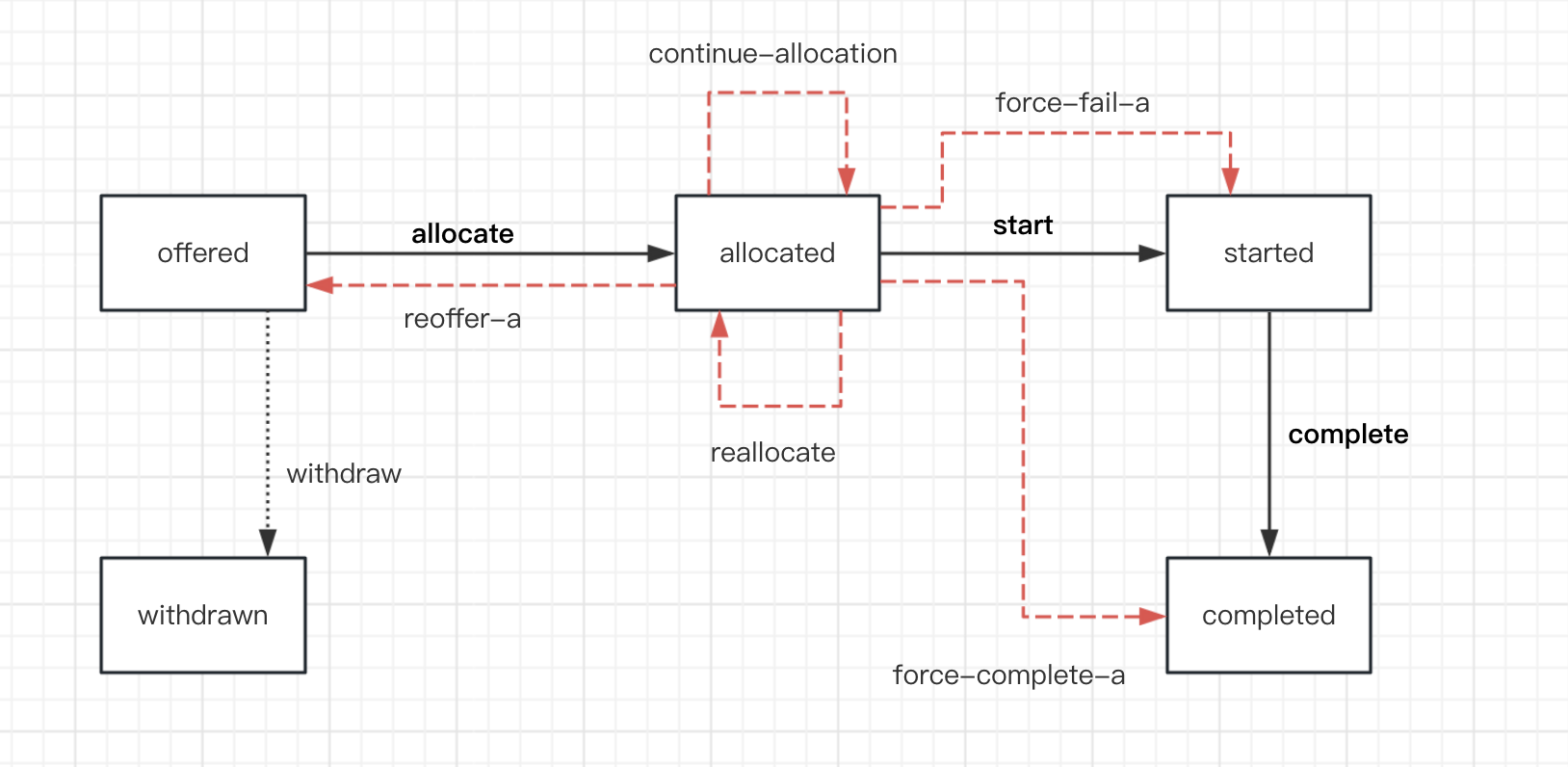
当状态处于allocated状态时,如果发生异常,它会出现以下五种可能的状态变换:
| 缩写 | 状态变换 | 说明 |
|---|---|---|
| ACA | continue-allocation | 任务已分配给特定资源,该资源将在未来某个时间执行该任务,异常情况不会导致任务状态发生变化。 |
| ARA | reallocate | 任务已分配给某一资源,该分配已撤销,任务被分配给另一资源。 |
| AFF | force-fail-a | 任务已分配给某一资源,该资源分配被撤销,任务的状态变为失败,不会触发后续任务。 |
| AFC | force-complete-a | 任务已分配给某一资源,该资源分配被撤销,任务的状态变为已完成,所有后续任务都会触发。 |
| ARO | reoffer-a | 任务已分配给某个资源,该分配被撤销,任务被提供给一个或多个资源(该组不一定包括之前分配给它的资源) |
当状态处于started状态时,它处理异常处理时,有如下五种可能得状态变换:
| 缩写 | 状态变换 | 说明 |
|---|---|---|
| SCE | continue-execution | 任务已启动,其状态不会因异常而改变。 |
| SRS | restart | 任务已启动,当前执行实例的进度停止,任务由之前执行该任务的同一资源从头开始重新启动。 |
| SRA | reallocate-s | 任务已启动,当前执行实例的进度停止,任务被重新分配到不同的资源供以后执行。 |
| SRO | reoffer-s | 任务已启动,当前执行实例的进度已停止,并将其提供给一个或多个资源(该组资源不一定包括正在执行该任务的资源)。 |
| SFF | force-fail | 正在执行的任务将停止继续执行,其状态也将变为失败。不会触发后续任务。 |
| SFC | force-complete | 正在执行的任务将停止继续执行,其状态也变为已完成。所有后续任务都被触发。 |
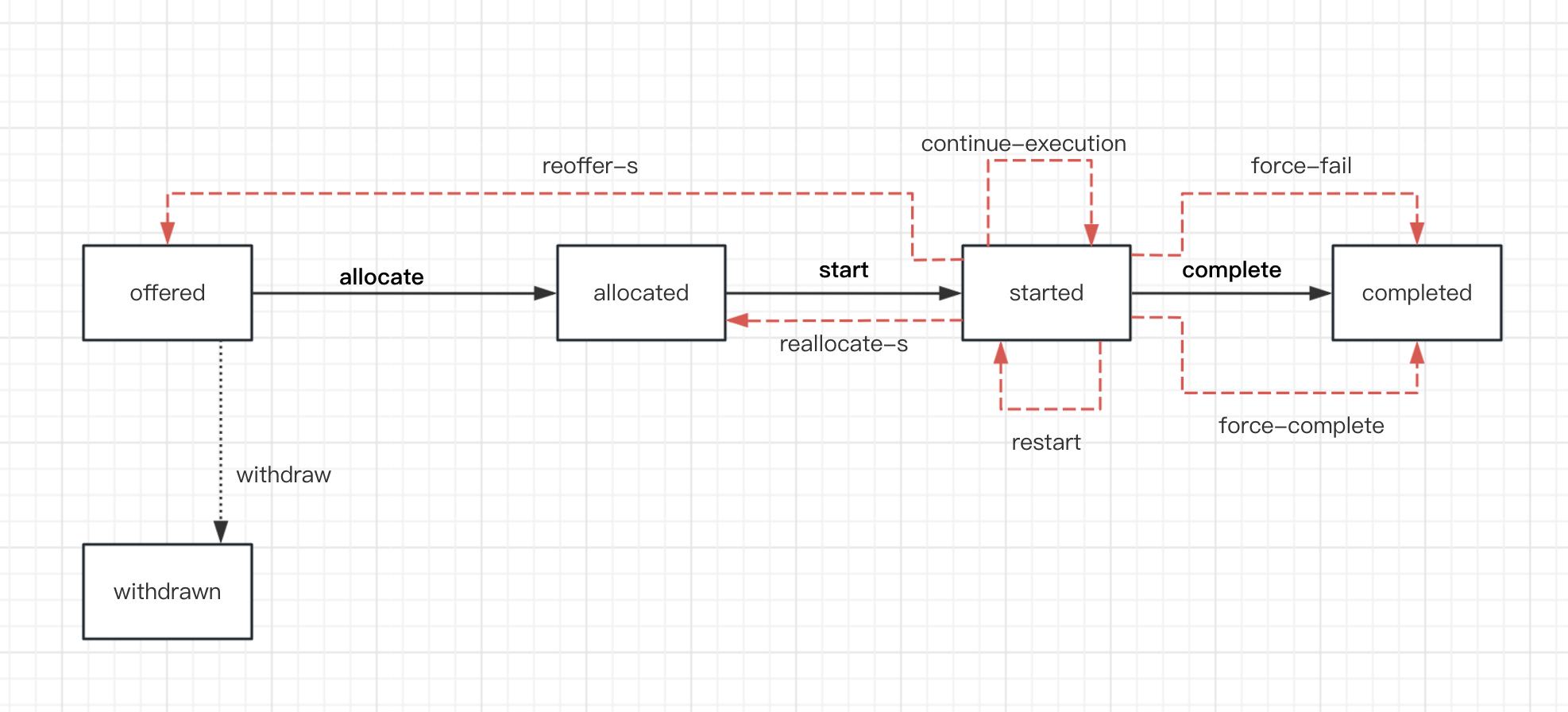
在任务级别的异常处理中,处理方法取决于检测任务的当前执行状态以及处理异常后的状态。例如,当检测到正在执行的任务失败时,其状态会相应地改变。具体的处理策略可以根据异常的类型、任务的当前状态以及期望的后续状态来确定。
# 流程级别的异常处理
异常发生时,可能影响同一流程实例中的其他任务。因此,在流程级别上处理异常时,需要考虑以下三种可能的选择:
- 继续当前流程实例:可以继续工作流实例,在任何其他任务的执行中不发生干预。
- 删除当前流程实例:删除当前流程实例中所有剩余任务。
- 删除所有流程实例:删除所有其他执行中的使用相同流程模型的流程实例下的剩余任务。
在后两种情况下,可以根据与相应任务定义相关的静态设计时间信息(例如任务类型、资源需求等)以及相关的运行时信息(例如实际分配给的资源、开始时间等)来指定要删除的任务的选择。
# 2、异常的检测
通常,将在当前正在执行的任务的上下文中检测到特定异常的发生。
# 3、异常的处理策略
在业务流程管理(BPM)中,对异常情况的处理至关重要。以下是一些常用的异常处理方法:
不操作:检测到异常以后,忽略跳过,继续执行下一步任务。
抛异常:在一个子流程中捕获异常,并在父流程中再次抛出。或者在任务中抛出异常,让全局异常捕获处理。
默认异常处理器:为工作流定义一个默认的异常处理程序,当发生未被特定处理程序捕获的异常时,由默认处理程序进行处理。
取消任务:当发生异常时,取消当前正在执行的任务实例。
取消流程:当发生严重的异常时,取消整个工作流实例。
人工干预:当检测到异常时,可以通知相关人员进行人工干预。人工干预可以快速解决问题,但可能需要较高的人力成本。例如在一个电商订单处理流程中,当订单支付状态异常时,流程自动通知客服人员检查并处理异常订单。
自动重试:对于某些可恢复的异常,可以尝试自动重试。例如,当网络连接失败时,可以等待一段时间后再次尝试。自动重试可以降低人工干预的成本,但可能无法解决所有异常。例如在一个数据同步流程中,当网络连接失败导致数据同步异常时,系统等待一段时间后自动尝试重新同步数据。
补偿:发生异常时,执行一些操作来抵消之前的活动,这通常用于处理业务逻辑错误。例如在一个库存管理系统中,当发现商品入库数量异常时,系统自动回滚到入库操作之前的状态,并通知相关人员进行核查。
恢复:在异常被处理后,恢复被暂停的工作流实例。
重新执行:在异常被处理后,重新执行导致异常的活动。
# 事务
# 数据库中的事务
在计算机科学和数据库管理中,事务(Transaction)是一组数据库操作,被视为一个不可分割的工作单位。事务包含了一个或多个数据库操作(例如插入、更新、删除等),这些操作要么全部执行成功,要么全部不执行,没有中间状态。事务确保数据库从一个一致的状态转移到另一个一致的状态。
事务通常满足以下四个属性,通常被称为ACID属性:
- 原子性(Atomicity): 事务是一个原子操作,要么全部执行成功,要么全部失败回滚,没有中间状态。
- 一致性(Consistency): 事务开始前和结束后,数据库必须保持一致状态。这意味着事务执行后,数据库中的数据应该满足一定的约束,不破坏事务前的一致性。
- 隔离性(Isolation): 多个事务并发执行时,每个事务的执行都应该与其他事务隔离,一个事务的执行不应影响其他事务的执行。这保证了在并发环境下数据库的一致性。
- 持久性(Durability): 一旦事务完成(提交),其结果应该被永久保存在数据库中,即使系统发生故障,也不应该丢失已提交的事务。
事务的典型应用场景包括金融系统、库存管理、在线购物等需要确保数据完整性和一致性的领域。在数据库管理系统中,使用事务可以防止数据损坏、确保数据的正确性,以及支持并发控制。
事务是数据库系统中保持数据一致性的机制,它要么完全执行,要么完全不执行。在事务中,通常涉及一系列的操作,这些操作要么全部成功提交,要么全部回滚。本地事务和分布式事务是两种不同的事务模型,分别应用于单一数据库系统和分布在多个数据库系统之间的情境。
# 本地事务
定义: 本地事务是在单一数据库中执行的事务,它仅涉及到该数据库内的数据和操作。
特点:
- 所有事务操作在同一数据库中完成。
- 通常使用数据库提供的事务管理机制,如SQL中的
BEGIN TRANSACTION、COMMIT和ROLLBACK。 - 数据库系统负责管理事务的隔离性、一致性、持久性和原子性。
示例:
-- 开始一个事务 BEGIN TRANSACTION; -- 在事务中执行一些操作 UPDATE 表名 SET 列名 = 新值 WHERE 条件; DELETE FROM 表名 WHERE 条件; -- 检查是否有错误 IF 错误条件 THEN -- 发生错误,回滚事务 ROLLBACK; ELSE -- 没有错误,提交事务 COMMIT; END IF;在上述例子中,
BEGIN TRANSACTION标志着事务的开始,接着执行了一些更新和删除操作。在检查错误条件后,如果发现错误,就执行ROLLBACK操作来撤销之前的所有操作。如果没有错误,则执行COMMIT操作来确认事务,使之前的操作生效。使用回滚操作是事务处理的关键部分,它确保了数据库的一致性,即使在操作过程中发生了错误
# 分布式事务
- 定义: 分布式事务是在分布在多个数据库系统之间执行的事务,它可能涉及到多个独立的、相互协作的数据库系统。
- 特点:
- 事务涉及多个数据库,可能分布在不同的物理位置。
- 通常需要采用分布式事务协议来确保事务的 ACID(原子性、一致性、隔离性、持久性)特性。
- 常见的分布式事务协议包括两阶段提交(2PC)、三阶段提交(3PC)等。
- 示例:
- 在一个分布式系统中,用户的操作可能跨越多个服务或数据库。例如,一个电子商务系统的订单支付操作可能涉及到用户账户服务、库存服务、支付服务等。
两者的主要区别:
- 范围:
- 本地事务仅涉及单一数据库,所有操作在同一数据库事务中执行。
- 分布式事务涉及多个数据库,可能分布在不同的物理位置。
- 协调机制:
- 本地事务使用数据库提供的本地事务管理机制。
- 分布式事务通常需要使用专门的分布式事务协议,如两阶段提交。
- 隔离性:
- 本地事务在同一数据库中操作,隔离性由数据库管理。
- 分布式事务需要额外的机制来确保在多个数据库之间的隔离性。
- 复杂性:
- 本地事务相对简单,仅涉及单一数据库的事务管理。
- 分布式事务的实现较为复杂,需要考虑多个参与者的协调和通信,以确保事务的一致性。
# 业务流程中的事务
在业务流程中,"事务" 一词的含义可能与数据库管理系统中的事务略有不同。在业务流程中,事务通常指的是一系列有序的、相关的业务操作,这些操作一起完成特定的业务目标。业务流程中的事务可以涵盖多个步骤和活动,旨在实现一个完整的业务功能。
这里的 "事务" 可能包括一系列业务活动,如填写表单、审批流程、数据处理、通知等。这些活动按照特定的顺序和规则组织在一起,形成一个事务单元,目的是完成一个特定的业务任务或满足特定的业务需求。
举例来说,考虑一个简单的采购流程:
- 提交采购申请: 员工填写采购申请表单,描述所需的物品和数量。
- 审批流程: 申请表单被提交给上级或相关审批人员进行批准。
- 采购订单生成: 一旦获得批准,系统生成采购订单。
- 物品采购: 采购部门根据订单购买所需物品。
- 入库: 收到物品后,进行入库操作。
- 付款: 生成付款单并完成付款。
整个采购过程就是一个业务流程事务,包括了多个步骤,每个步骤都有其特定的任务和条件。在这个业务流程中,每个步骤的成功完成都依赖于前一个步骤的成功完成。如果其中任何一步失败,整个事务可能被中断或需要回滚到之前的状态。这也是异常处理需要考虑的问题,也是最复杂的地方,因为这事务中的任务可能涉及多个不同的系统。
# 补偿
补偿机制是一种用于处理事务执行中出现异常或错误的机制,以确保业务流程的一致性和完整性。当某个任务或步骤发生故障时,补偿机制会触发一系列的补偿操作,这些操作的目的是撤销或修复已经执行的任务,将系统状态恢复到正常状态。
以下是补偿机制的一般性特征和步骤:
# 特性和步骤
定义补偿任务: 在业务流程的某个节点或任务中,定义一个补偿任务。这个任务描述了在发生异常情况时应该执行的操作。
关联补偿任务: 将补偿任务与可能引发异常的任务相关联。
触发补偿机制: 当流程执行中发生异常时,系统将触发与异常相关联的补偿任务。异常可以是由于外部系统故障、超时、无效数据等原因引起的。
执行补偿操作: 补偿任务的执行会导致一系列的补偿操作,这些操作的目的是撤销或修复之前已经执行的任务,以保持系统的一致性。
事务回滚: 在某些情况下,补偿机制可能需要执行事务回滚,以确保所有相关的操作都能被撤销。这通常要求支持事务的系统。
# 补偿机制示例
考虑一个简单的采购流程:
- 提交采购请求任务: 员工提交采购请求。
- 扣除库存任务: 扣除相应产品的库存。
- 支付任务: 完成支付。
- 关联补偿任务: 在支付任务中,关联一个补偿任务,例如,如果支付失败,执行补偿操作。
- 触发补偿机制: 如果支付失败,系统触发与支付任务关联的补偿任务。
- 执行补偿操作: 补偿任务可能包括撤销库存扣除操作,以保持一致性。
这个例子中的补偿机制保证了在支付任务失败时,库存的扣除操作能够被正确地撤销,确保系统的一致性。
# 编程中的异常处理
异常处理机制落到底层其实就是通过代码来实现。所以,编程语言中的异常处理机制是可以借鉴过来使用的。
下面用python语言举例。
Python的异常处理机制是通过使用 try-except 语句来实现的。当程序运行到 try 代码块中,如果发生异常,Python会跳到 except 代码块中执行相应的处理。如果没有发生异常,Python会跳过 except 代码块,继续执行后续的代码。除此之外,还可以使用 finally 代码块,无论是否发生异常,finally 代码块中的代码都会被执行。
所以,一个标准的Python异常处理通常包括以下几个部分:
- try 代码块:放置可能发生异常的代码,一般是业务代码。
- except 代码块:处理特定异常的代码。
- finally 代码块(可选):无论是否发生异常,都会执行的代码。
在实际写代码时,我们会区分全局异常和局部异常的处理。
全局异常处理是指在程序的最顶层(通常是主函数)设置一个try/except块来捕获所有可能出现的异常。这样做的好处是可以确保程序在出现异常时不会立即崩溃,而是会执行一些清理工作,然后优雅地退出。
局部异常处理是指在可能引发特定异常的代码附近设置try/except块。这样做的好处是可以针对不同的异常类型提供不同的处理逻辑。
下面举例说明一个简单的异常处理:
# 全局异常处理
def main():
try:
# 这里是可能引发异常的代码
print(divide(1, 0)) # 输出:Error: Division by zero.
print(divide(1, "a")) # 输出:Error: Invalid input type. Both x and y should be numbers.
except Exception as e:
print(f"Caught an exception: {e}")
# 这里是处理异常的代码,比如清理资源、记录错误日志等
if __name__ == "__main__":
main()
# 局部异常处理
def divide(x, y):
try:
result = x / y
except ZeroDivisionError:
print("Error: Division by zero.")
return None
except TypeError:
print("Error: Invalid input type. Both x and y should be numbers.")
return None
else:
return result
在上述代码中,我们展示了Python中全局和局部异常处理的实现方式。
- 在全局异常处理的例子中,我们定义了一个名为
main的函数,该函数中的代码被放在一个try块中。这意味着如果这些代码中的任何一行引发了异常,Python将立即跳到except块。在这个例子中,我们尝试执行divide(1, 0),这将引发ZeroDivisionError异常,因为我们不能除以零。当这个异常被引发时,Python立即跳到except块,并打印出异常的信息。 - 在局部异常处理的例子中,我们定义了一个名为
divide的函数,该函数接受两个参数x和y,并尝试返回x除以y的结果。在这个函数中,我们使用了两个except块来分别处理ZeroDivisionError和TypeError异常。如果y为零,将引发ZeroDivisionError异常,我们打印出错误信息并返回None。如果x或y不是数字,将引发TypeError异常,我们同样打印出错误信息并返回None。
# 异常处理机制的实现
前面,我们把异常区分成全局和局部两种实现方式,局部的是各个任务节点自己实现处理的,而全局则是兜底处理那些任务节点遗漏未处理的异常。
在第三节中,我们定义了各个任务节点的JSON结构模型,其中的errorHandler就是设置异常处理相关的配置。
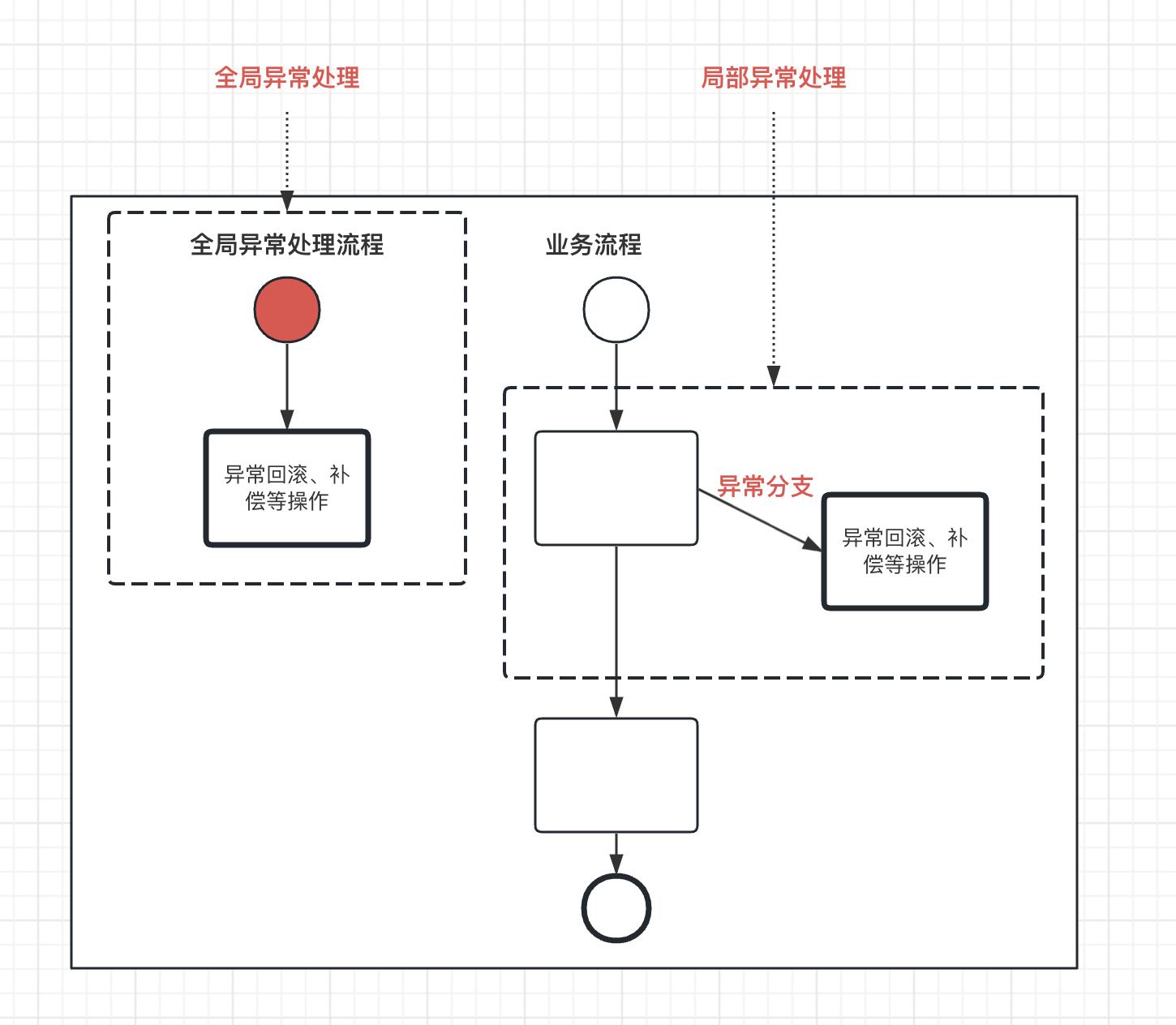
# 局部异常处理
异常处理方式
如下所示,局部异常处理有4种方式:
- 重试(retry):可以设置retryCount重试次数、retryInterval重试间隔(单位:秒)。
- 忽略(ignore):忽略异常的发生,什么也不做,继续执行下一个任务节点。
- 抛出异常(throwException):当认为任务节点发生异常时不适合处理,可以统一向上抛出异常,让全局异常捕获处理。
- 捕获(catch):可以设置异常处理的分支(exceptionBranch),在这个分支里,可以设置做异常的回滚、补偿以及接入人工干预流程等操作。
{
"operation": "retry/ignore/throwException/catch",
"retryCount": 1,
"retryInterval": 1,
"exceptionBranch": "",
"exceptionType": "abort/timeout/resource unaviable/constraint/unknown",
"exceptionMsg": "异常详情"
}
要捕获的异常类型(exceptionType)如前面介绍的:
- abort:外部任务执行异常
- timeout:执行超时异常
- resource unaviable:资源不可用异常
- constraint:不满足任务或流程的一些约束规则异常
- unknown:一些意料之外的异常
exceptionMsg字段会把异常的内容返回,便于后续的异常分支可以获取做判断分析。
# 全局异常处理
如果出现一些任务节点抛出异常或者预料之外的异常,则全局异常处理需要进行捕获响应处理。
在实现上,可以定义一个全局异常捕获节点,一旦流程中添加了这个全局异常捕获节点,则引擎就需要去监控全局异常并响应。
一旦捕获到任务节点未处理的异常,就可以捕获到类似如下JSON数据,可以知道发生异常的任务节点、异常的信息等信息。下面这些信息作为这个【全局异常捕获节点】的输出。
{
"createAt": "2023-12-18T20:26:52.001582519+08:00",
"error": "{\"Name\":\"test\",\"Content\":\"throw error\"}",
"errorAppInstId": "v3g1sjx7pk",
"errorAppName": "Throw Exception",
"executionUid": "2023511736724707847770112",
"workflowId": 7,
"workflowName": "【DEMO】Error handler"
}
上述实现方式的好处是,正常的业务流程不会混杂太多异常的处理过程,如果想保持业务流程的清晰,可以统一放到全局处理流程上处理。可以把异常处理的逻辑从业务逻辑中剥离出来,单独成一个流程,甚至可以传递给子流程去响应处理。