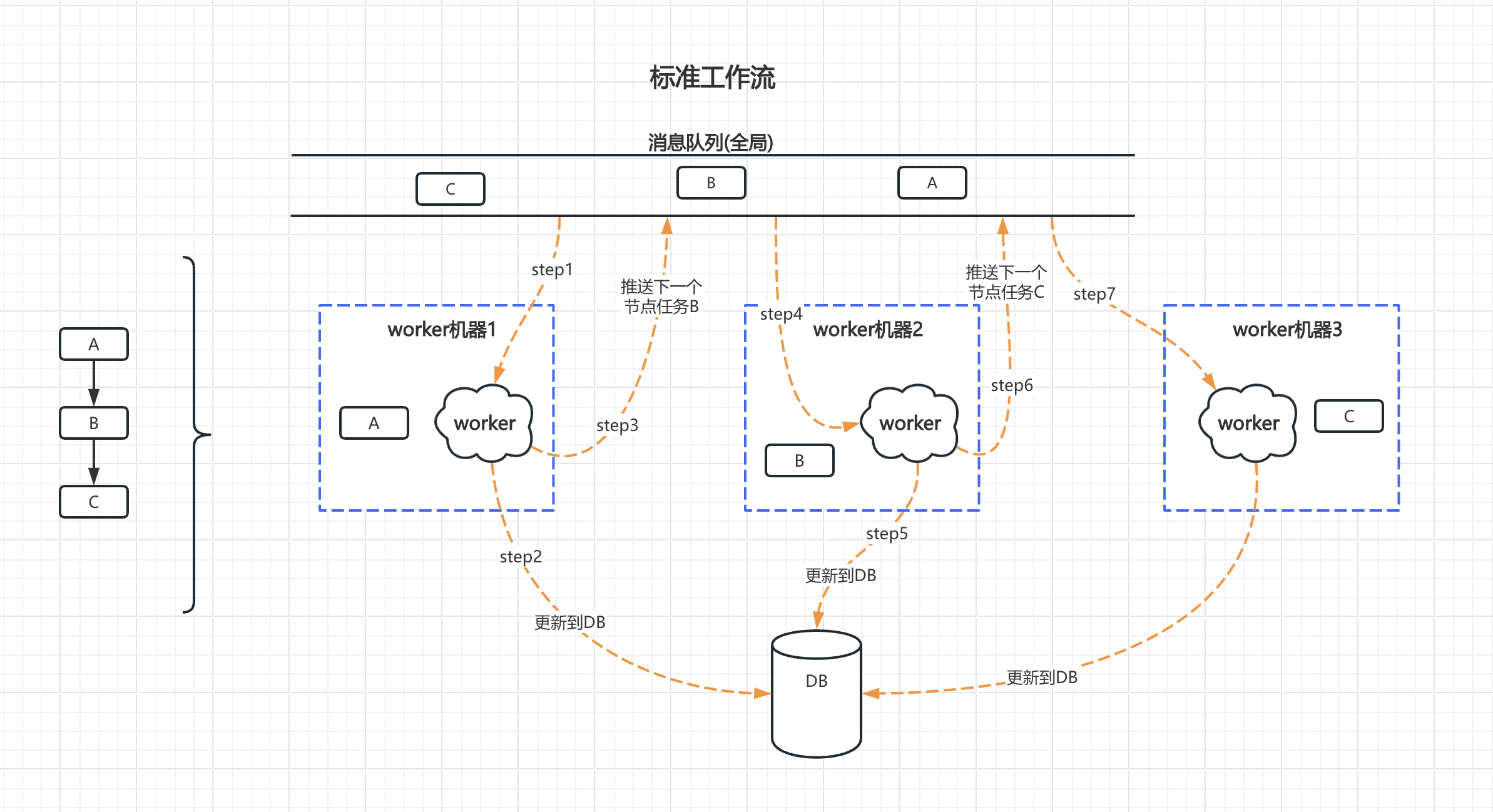
下图是流程引擎的执行原理图,流程中每个节点是基础的执行单元Job,基于Token的令牌执行机制,执行单元Job依次进入消息队列,然后由后端的worker节点消费执行。
在实际的业务场景中,有高频的API调用、审批、定时任务等等使用场景。不同的使用场景,对于流程引擎的执行有一定的区别。
例如高频的API请求,这种要求流程引擎对流程实例的执行效率和速度一定要快,且任务量极大。
例如审批场景,这种场景对流程引擎的执行速度要求不高,但是由于涉及到审批,整个流程实例的运行时间可能会很长,这里每执行完一个Job,就需要进行数据保存,避免运行过程中由于系统异常导致丢失。
前者更关注运行的结果,后者更关注运行的过程(各节点运行情况),着重点不一样。
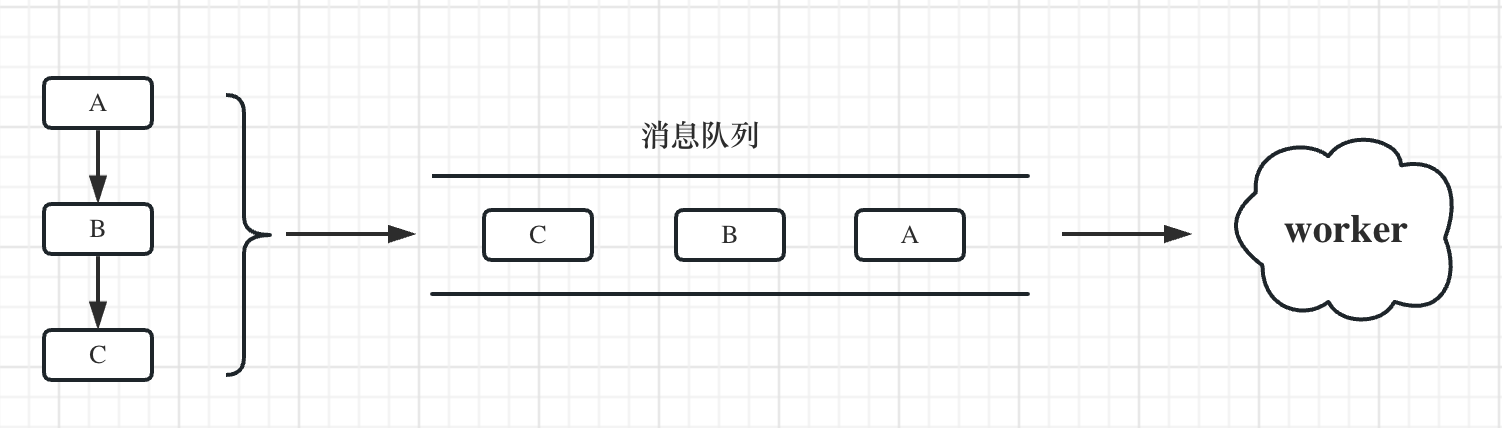
这些场景通过整理,可以归结为以下两种工作流类型。
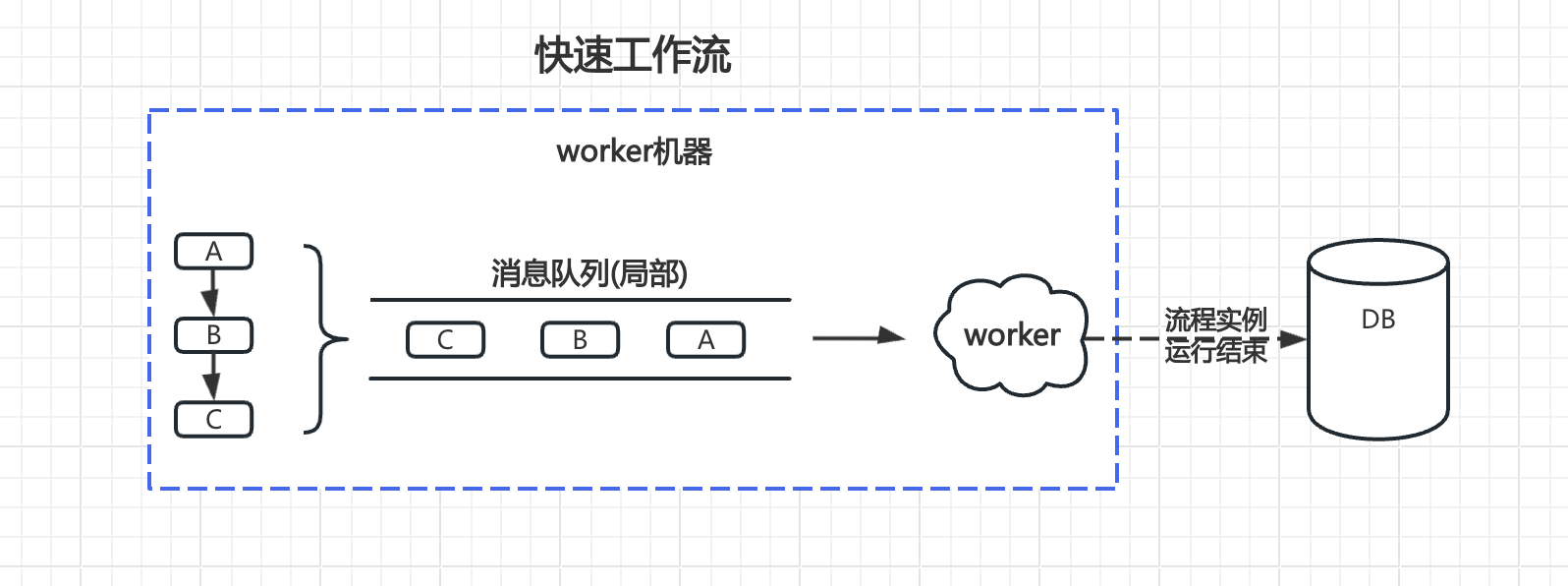
# 快速工作流
特点:
- 纯内存型的流程引擎
- 流程中没有耗时任务,执行时长通常在10s内
- 关注运行结果,且任务量极大
- 流程实例的所有的执行Job都在同一台机器上运行,可减少在不同机器上执行时增加网络传输时间
- 流程实例的执行全过程都是在内存中操作,不跟DB等其他中间件有交互,以此减少对db的频繁操作,提高执行效率
- 流程实例所使用的消息队列是局部本地的(当前机器的消息队列)
# 标准工作流
特点:
- 分布式流程引擎
- 适合长时间运行、持久可审计,且存在与用户交互
- 关注运行过程
- 流程实例的各个执行Job在分布式机器集群上运行(可以让集群各节点负载更均衡)
- 流程实例中每个节点执行结束时,运行时的数据都会及时存储到DB中
- 流程实例所使用的消息队列是全局分布式的(所有集群节点共用)