流程分析分以下三个阶段,每个阶段分析的数据都不一样。
- 运行前。分析流程结构的合理性。
- 运行中。分析当前的执行状况。
- 运行后。分析历史数据,找到的瓶颈所在并进行优化。
# 运行前流程结构分析
在工作流管理系统中,流程定义是一个关键步骤,它决定了工作流的执行路径和处理逻辑。然而,在定义流程的过程中,经常会出现一些错误,这些错误可能会导致工作流的执行出现问题,甚至导致工作流的失败。以下是一些常见的流程定义错误:
# 流程没有起始和结束
正常一个流程至少要有一个起始节点和一个结束节点,没有起始节点,就无法知道流程从哪里开始执行,没有结束节点,流程就不知道要执行到哪里才是结束。前面我们介绍基于Petri网的工作流网的定义中就有一个:必须包含一个起点和终点,这里也是一样的要求。
例如下面缺少一个起始节点。
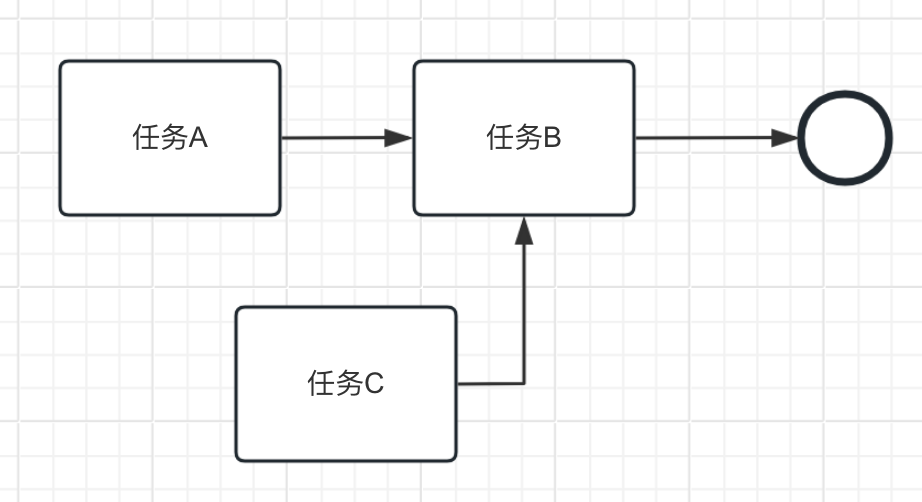
# 存在无法执行的任务
这种情况通常被称为"死任务",即任务在任何情况下都无法被执行。这可能是因为任务的输入条件永远无法满足,或者任务的执行逻辑存在问题。例如下图的任务C就是一个孤单的任务。
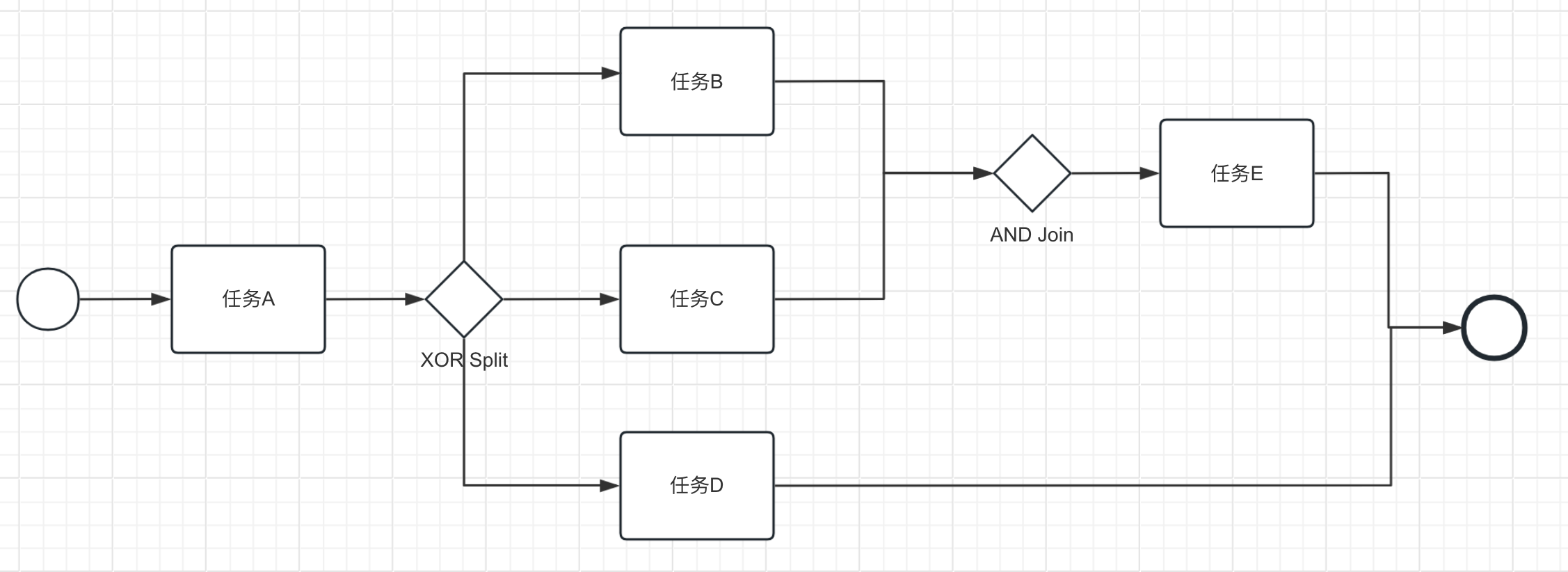
# 存在任务阻塞
这种情况通常被称为"死锁",即任务在到达结束状态前发生了阻塞,无法继续执行。这可能是因为任务之间的依赖关系设置不正确,或者任务的执行逻辑存在问题。例如下面的任务E就会一直阻塞,因为前面的AND Join需要任务B和任务C都完成才能满足条件继续执行。但是XOR Split只有一个分支会执行,这就意味着任务B和任务C要么都不执行,要么只有一个分支执行,所以AND Join永远无法满足条件。
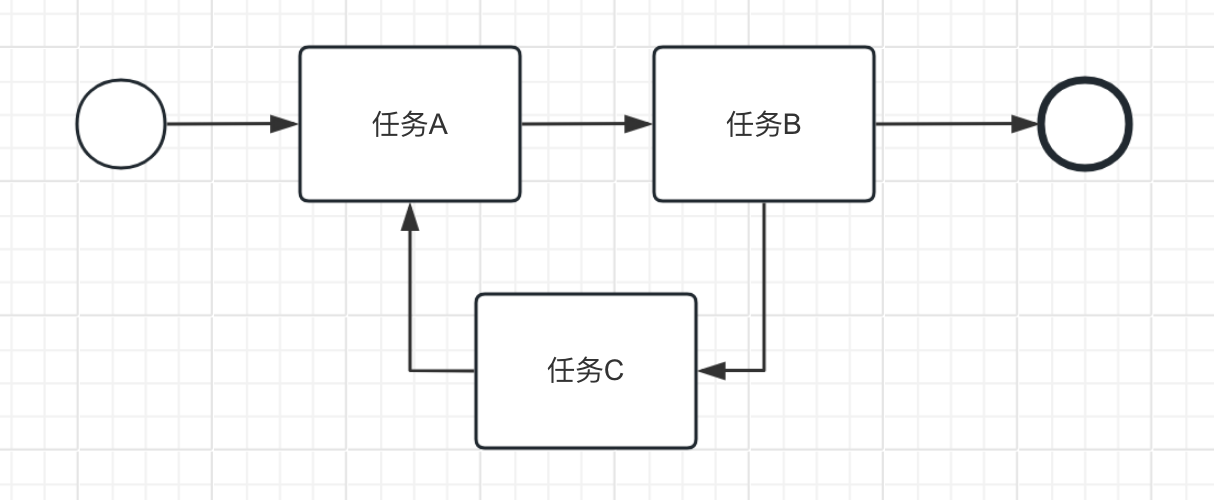
# 存在无尽的任务循环
这种情况通常是任务被引入了无休止的循环中,无法达到结束状态。这可能是因为任务之间的依赖关系设置不正确。例如下面的任务A、B、C就进入了死循环,永远无法结束。
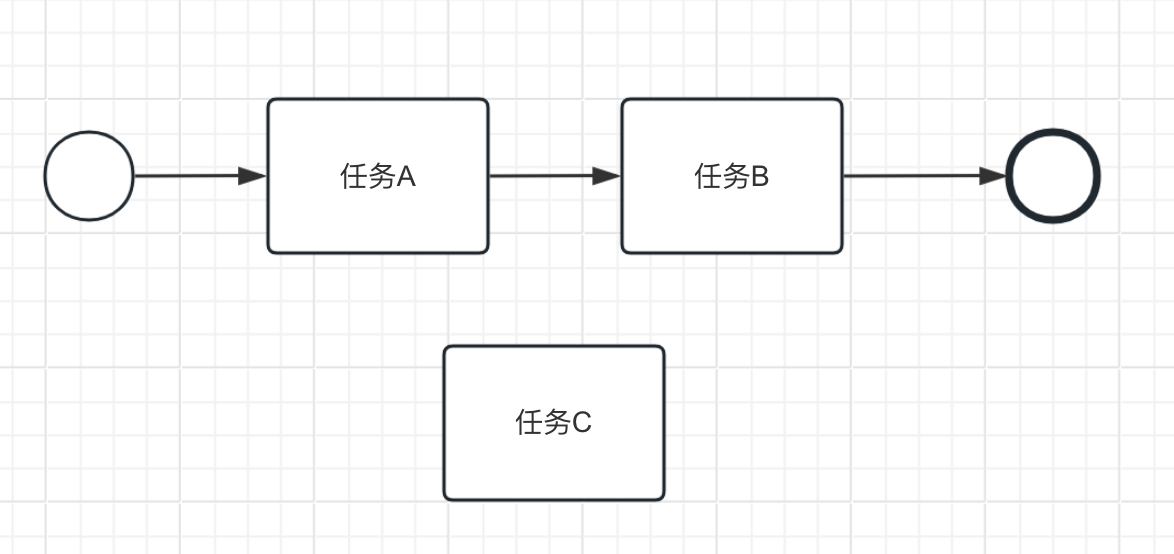
# 在达到结束状态后,仍有任务在执行
这种情况可能是因为工作流的结束条件设置不正确。正常的流程在执行到结束节点时,其他所有运行中的节点都应该已经结束才对。这就有点像Linux操作系统中的孤儿进程,即一个父进程退出结束了,而它的一个或多个子进程如果还在运行,那么这些子进程将成为孤儿进程。
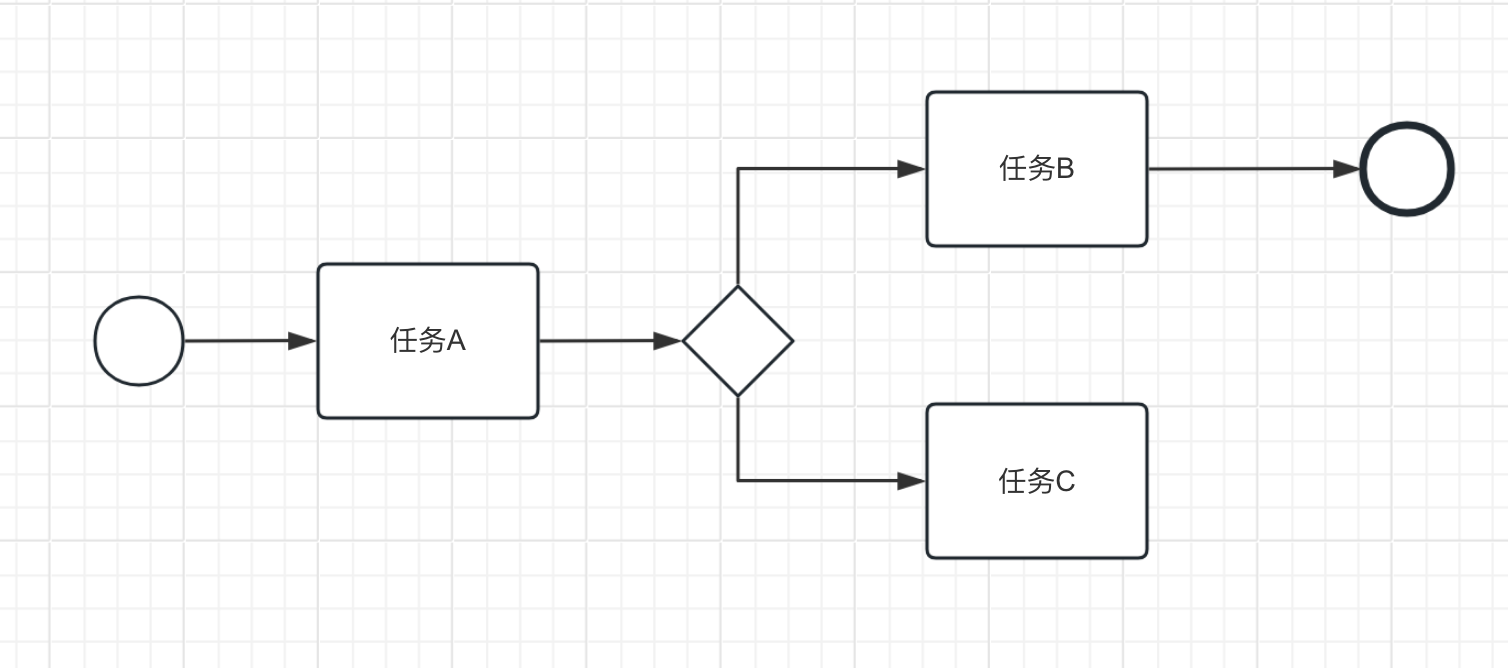
例如下面出现并行的任务B和任务C,但是没有对分支进行合并,导致执行完任务B结束后,任务C依然可能还在执行。
# 并行分支不同步
正常的流程,并行分支是有多少个分支出去,最终这些分支都要汇聚到一起,即保证这些分支是同步的,否则无法控制子分支的结束,这就造成了流程执行的不可控局面出现,可能会出现资源泄漏之类的问题。
这有点像我们写多线程时,在开启多个子线程任务后,一般都会有一个Join或Wait的等待所有子线程执行结束的步骤,保证这些子线程能正常结束,否则子线程就时不可控的因素。
Golang并发控制:
package main
import (
"fmt"
"time"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Add(2) //设置计数器,数值即为goroutine的个数
go func() {
defer wg.Done() //goroutine执行结束后将计数器减1
//Do something
time.Sleep(1*time.Second)
fmt.Println("Goroutine 1 finished!")
}()
go func() {
defer wg.Done() //goroutine执行结束后将计数器减1
//Do something
time.Sleep(2*time.Second)
fmt.Println("Goroutine 2 finished!")
}()
wg.Wait() //主goroutine阻塞等待计数器变为0
fmt.Printf("All Goroutine finished!")
python的多线程同步:
在 Python 中使用多线程时,可以通过 threading 模块创建和管理线程,并使用 join() 方法等待子线程结束。
通过这种方式,你可以有效地管理多线程任务,并确保在继续执行主程序之前,所有子线程都已完成。
以下是一个简单的示例,演示了如何创建多个线程并等待它们完成。
import threading
import time
# 定义一个线程要执行的函数
def worker(thread_id):
print(f"线程 {thread_id} 开始工作")
time.sleep(2) # 模拟耗时操作
print(f"线程 {thread_id} 工作完成")
# 创建一个线程列表
threads = []
# 创建并启动多个线程
for i in range(5):
thread = threading.Thread(target=worker, args=(i,))
threads.append(thread)
thread.start()
# 等待所有子线程结束
for thread in threads:
thread.join()
print("所有线程已完成")
例如下面的任务B和任务C没有合并分支。
# 运行中流程记录分析
在执行时生成的流程实例中,可以分析出以下有用信息或指标:
- 流程执行时间:通过分析流程实例的开始和结束时间,可以计算出流程的执行时间,从而了解流程的效率。
- 任务执行情况:流程实例中包含了各个任务的执行情况,可以了解每个任务的完成情况、执行时间、执行人等信息,有助于分析任务的效率和质量。
- 节点流转路径:通过流程实例中的节点信息,可以了解流程在执行过程中的流转路径,以便分析流程的合理性和优化流程设计。
- 异常情况:流程实例中可能包含异常情况,例如任务超时、流程终止等,通过分析这些异常情况,可以找到流程的瓶颈和潜在问题。
- 参与者信息:流程实例中包含了参与者的信息,例如执行人、审批人等,有助于分析参与者的工作负荷和协作情况。
# 运行后历史数据分析
通过分析历史的运行记录数据,将流程的历史运行数据进行量化和可视化,来了解流程的表现情况,从而揭示流程中运行的瓶颈以及有待改进的地方。通过数据驱动的方法进行流程优化,帮助管理者有效地改进当前的资源分配决策。
这里的流程分析可以从不同的视角来进行,例如:控制流视角、数据视角、资源视角等。
控制流视角可以解释流程整体的运行状况能让管理者一目了然发现瓶颈所在;数据视角可以查看到流程运行时的上下面数据以及运行时的数据;资源视角以人的角度来分析,可以看到每个员工的任务安排(即甘特图)。
下面我们分别从最主要的控制流视角、数据视角和资源视角三个来介绍。
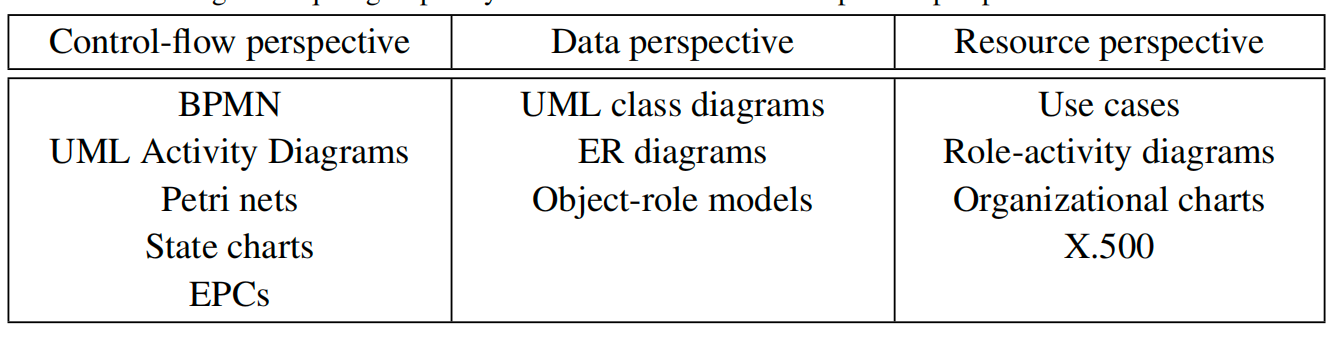
业务流程的三个模式
控制流视角:
控制流模式关注的是业务流程中的任务集合以及这些任务之间的流转关系。这包括三个方面:
- 功能视角: 描述组成业务流程的各项活动。
- 控制视角: 描述这些活动之间的路由,即活动执行的顺序。
- 行为视角: 描述个别活动实际上如何被进行。
数据视角:
数据模式关注的是在执行业务流程时所需的信息,即“运行时的工作数据”。
资源视角:
资源模式关注的是实际执行业务流程的人员和设施,以及他们运作的组织背景和彼此之间的各种关系。这包含了两点:
- 资源视角: 确定实际执行业务流程的人员和设施。
- 组织视角: 描述人员和物理资源如何被利用以完成业务流程,以及它们之间的关系。
总体而言,这三个模式为业务流程提供了全面的描述,涵盖了控制的执行流程、所涉及的数据以及执行人员和资源。通过这些模式,企业能够更好地理解、管理和优化其业务流程。它们提供了一个多维度的视角,帮助企业在制定和优化业务流程时考虑到不同方面的需求和关注点。
如下是三种模式的对应工具和技术:
# 控制流视角
# 时间瓶颈分析
在业务流程中,如果想分析人工任务的瓶颈所在,则需要如下图一样,通过分析历史的数据,得到每个人工任务节点的平均执行时间,并在展示时以颜色深浅的方式更友好的方式展现给管理者,让管理者能够一眼就看出流程的时间瓶颈卡点所在。
同时,在前面任务节点的生命周期,我们知道,一个需要分配人工资源的任务,在进入【已开始】状态之前,有一个等待人员分配和就绪的时间,在下图的展示中,标注在箭头连线上。
这样就可以非常直观地看到流程中所有环节的平均耗时,快速定位到时那个节点出现了瓶颈。
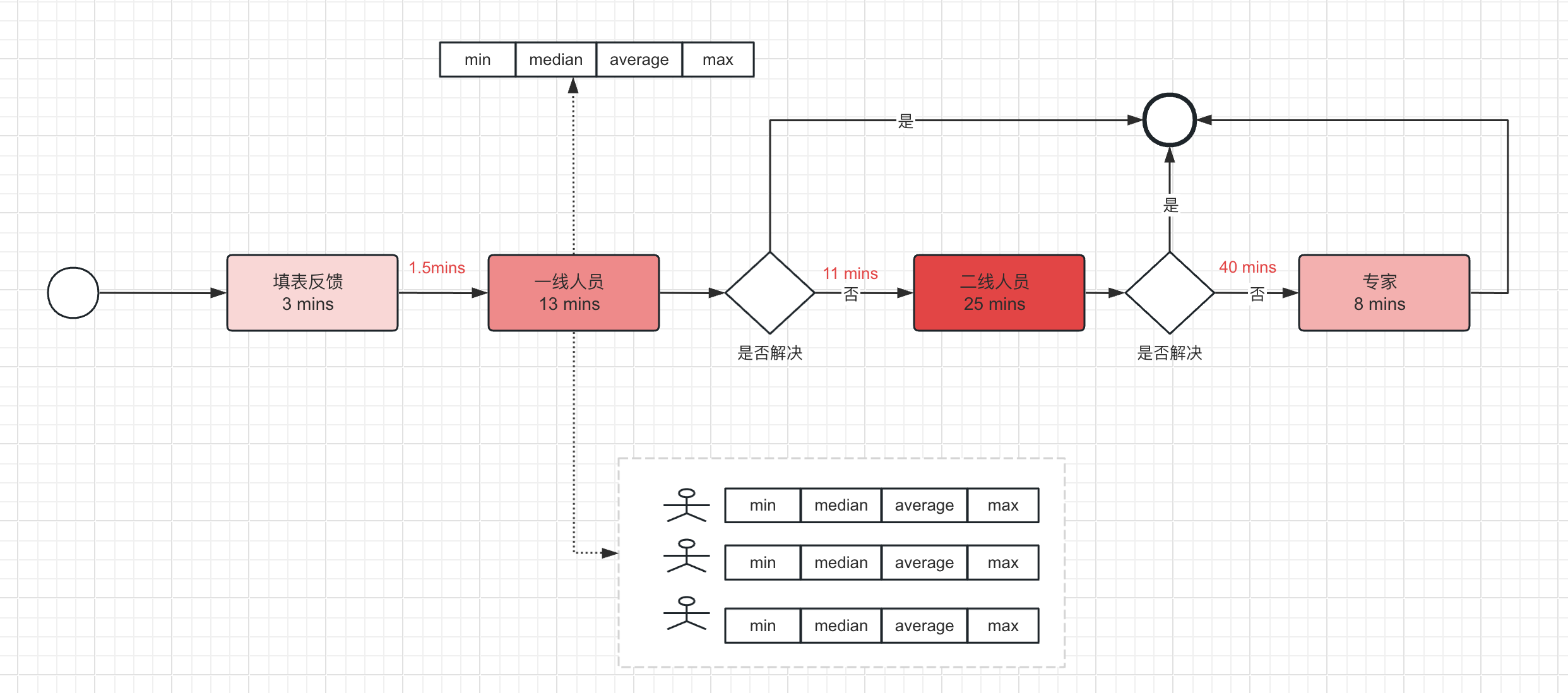
在这个视角下可以监控分析下面几个关键的指标:
流程(案例Case)统计
- 流程的最小耗时(min)
- 流程的中位数耗时(median)
- 流程的平均耗时(average)
- 流程的最大耗时(max)
任务统计
监控分析流程中各个任务节点的统计数据(注意:下面的指标是流程中每个任务节点都有的数据)
- 任务的最小耗时(min)
- 任务的中位数耗时(median)
- 任务的平均耗时(average)
- 任务的最大耗时(max)
资源统计
更近一步,由于流程中同一个任务节点可能分配给不同的人员处理,不同人员之间的能力差异会导致任务执行耗时不同。通过对流程中任务进一步分析人员的执行情况,可以看到哪个员工处理时长久导致整体耗时变长,从而进行优化。
- 每个人员的最小耗时(min)
- 每个人员的中位数耗时(median)
- 每个人员的平均耗时(average)
- 每个人员的最大耗时(max)
资源分配耗时统计
如上图中我们可以看到任务在人员就绪之前,有一个资源分配,即人员分配调度的过程,这里面也会产生一定的耗时,也是流程中需要关注的一个瓶颈所在。
# 空间瓶颈分析
这里的空间指的是流程中哪个任务出现了堆积,导致瓶颈问题产生,也就是分析流程中哪个位置出现了问题。
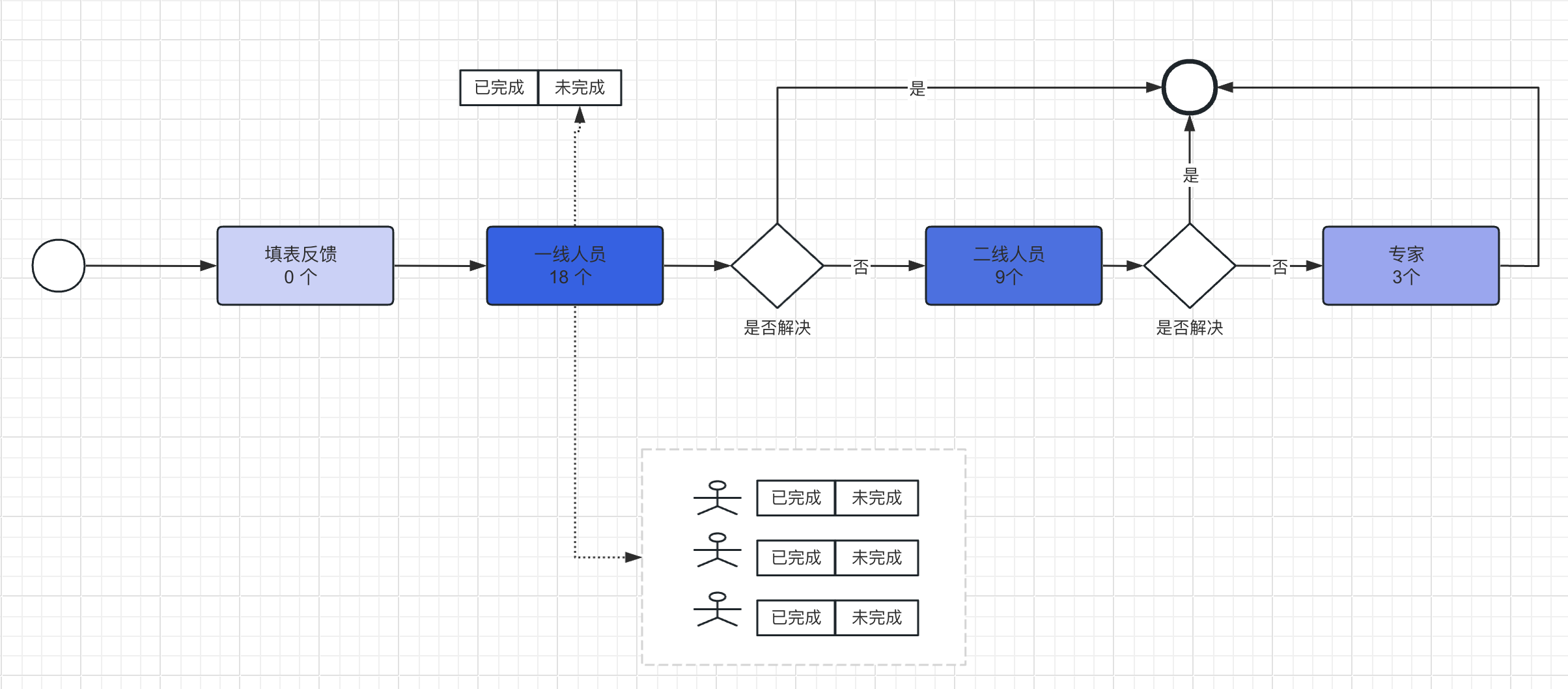
如下图,就可以一目了然看到流程中哪个任务堆积了大量任务,可以及时进行改善。
流程(案例Case)统计
- 已完成的流程实例数量和百分比
- 未完成的流程数量和百分比
任务统计
监控分析流程中各个任务节点的统计数据(注意:下面的指标是流程中每个任务节点都有的数据)
- 已完成的任务数量和百分比
- 未完成的任务数量和百分比
# 数据视角
数据视角下可以把前面自定义的变量历史数据统一进行展示,这里实际上是变相支持用户自己设计一套监控指标,给系统预留了一个拓展空间。
流程中每个任务节点如果设置了自定义变量后,在查看历史数据时,都可以看到一个表格数据,表格会展示历史每次运行后的变量值。
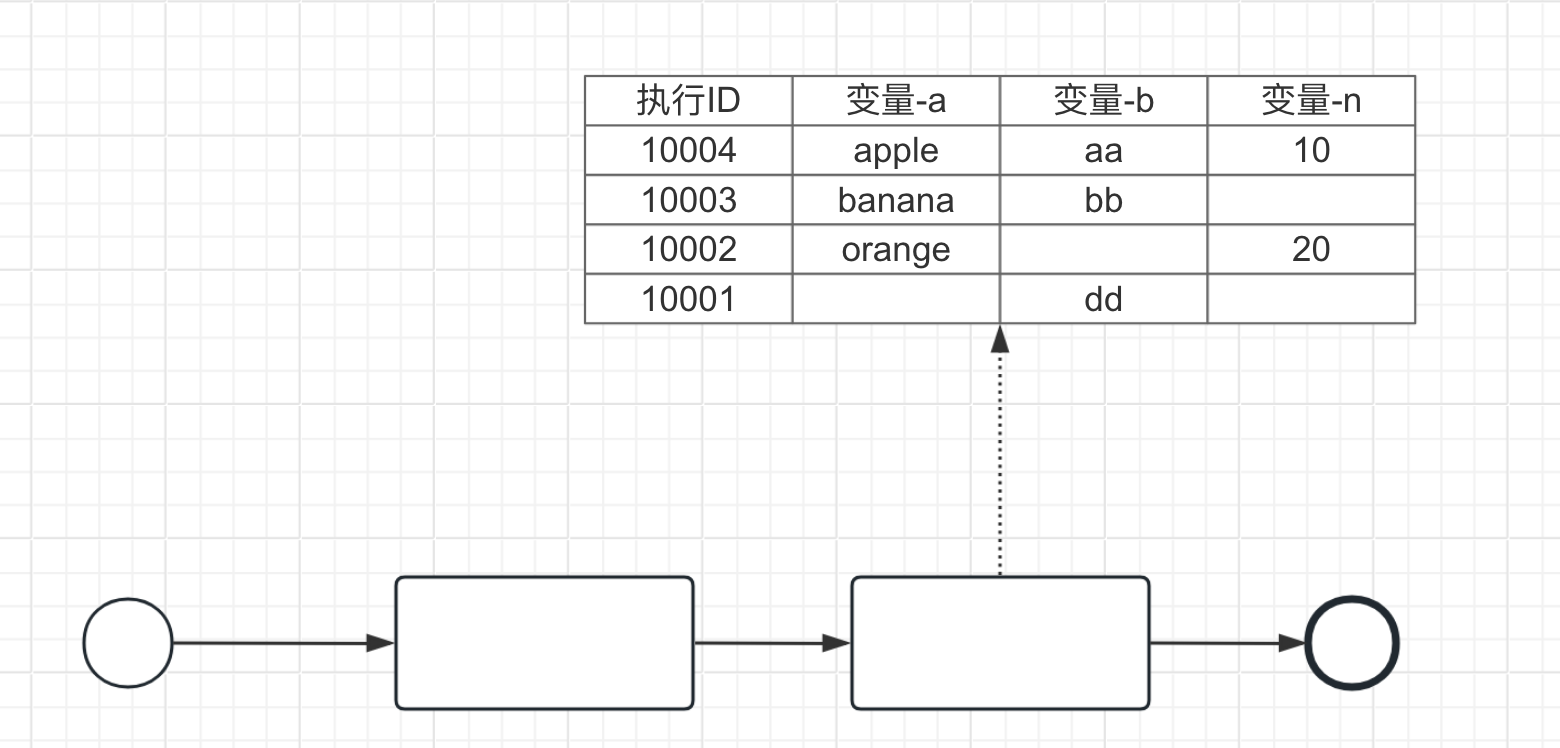
同时,每一个运行中的流程实例,都记录了运行时的上下文数据,即运行时产生的数据。
# 资源视角
资源视角下每个员工都可以看到自己过去、现在和未来的任务排期(甘特图),而站在管理者角度,则可以看到所有员工的任务排期,让管理者对项目进度有整体的把握。
当然这里的任务甘特图是基于前面引擎的资源调度能力规划的。
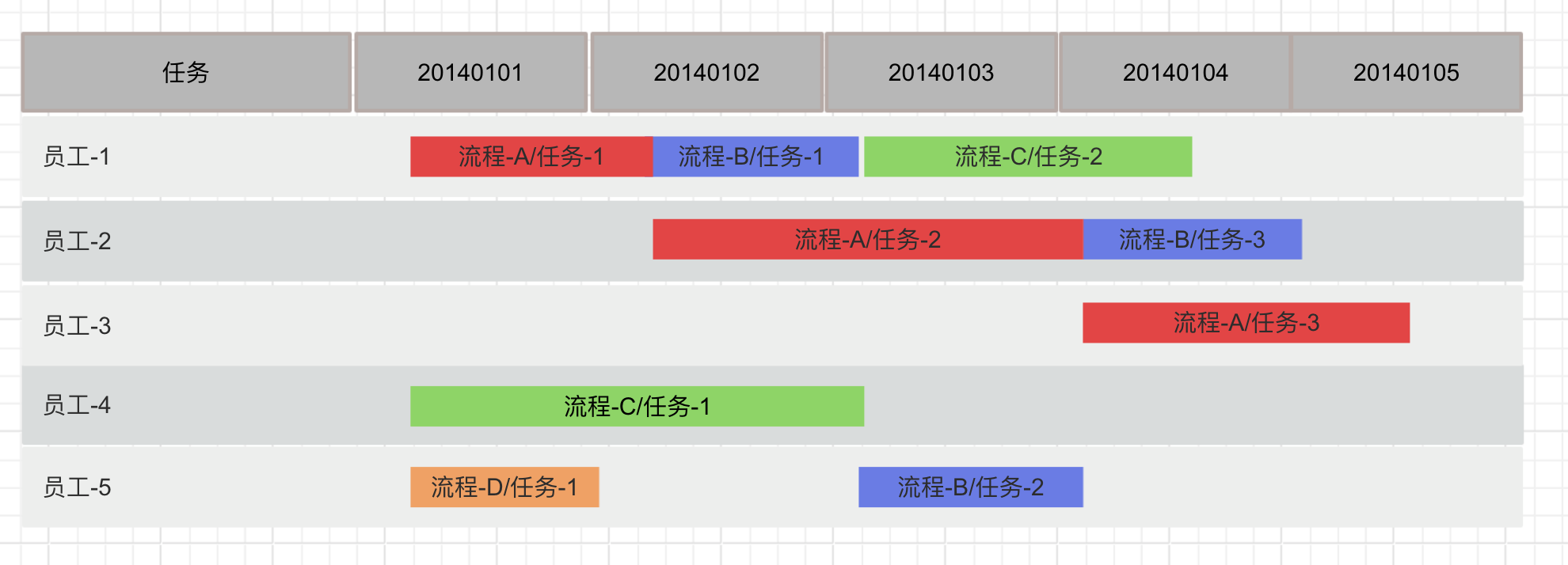
备注:这里资源默认指人非自动化机器。