与资源服务相结合的每个任务都可以指定为手动任务(默认任务)或自动任务(而任务是手动任务还是自动任务仅与资源服务相关)。手动任务是由人力资源执行的任务;根据定义,自动任务不需要人力资源,而是可以在运行时执行指定的代码集。
定义任务,这些任务定义构成整个流程定义的一部份。
# 子流程执行
原理
子流程节点完整JSON结构如下:
{
"instId": "xxx",
"name": "子流程",
"type": "Task",
"description": "子流程",
"template": "sub-workflow",
"positions": [],
"connections": [],
"parameters": {
"child_workflow_id": {
"label": "child_workflow_id",
"type": "integer",
"value": 0,
"default": 0,
"required": true
},
"operation": {
"label": "operation",
"type": "string",
"value": "",
"default": "sync",
"required": true
},
"whenParentComplete": {
"label": "whenParentComplete",
"type": "string",
"value": "continue",
"default": "continue",
"required": false
}
},
"errorHandler": {},
"loopHandler": {},
"timeout": 0,
"isIgnore": false,
"runtimes": []
}
- child_workflow_id
要运行的子流程ID。
- operation
该节点主要负责触发子流程运行,其运行有两种方式,一种是同步运行子流程,这种是阻塞式的。另一种是异步地运行子流程,这种是非阻塞式的。
(1)同步运行子流程
触发创建子流程实例,并推送到消息队列。然后阻塞,直到子流程运行结束后,获取子流程的输出结果并返回,最后才继续往下执行。
(2)异步运行子流程
触发创建子流程实例,并推送到消息队列。然后直接运行下一个节点任务,不等待子流程运行结果。
- whenParentComplete
如果operation设置为async,当父工作流在子工作流之前执行结束时,子工作流采取的行为。默认是terminate,即终止子工作流执行。如果选择continue,则子工作流继续执行。
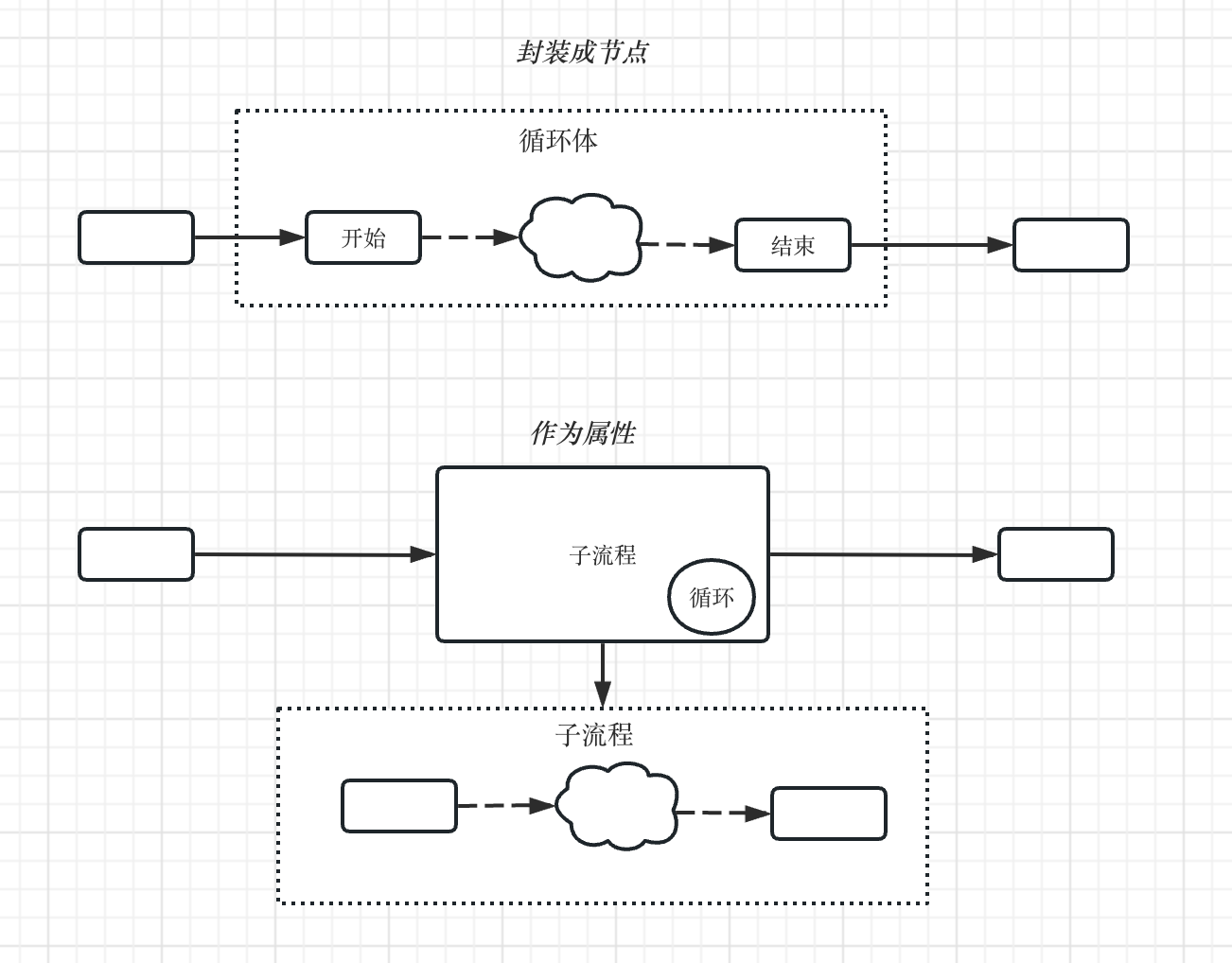
自流程的循环设置
在流程定义里,对于循环有两种实现方式,一种是将循环定义为节点的属性;一种是将循环封装成一个节点类型,在流程图上体现出来。
两种实现方式都可以,我个人更倾向于将循环定义为子流程的属性。循环体内的任务可以通过在子流程上实现,然后在父工作流上引用并设置循环参数。
这种方式实现的循环功能更灵活,也可以轻松支持无限的循环嵌套。
定义循环属性的JSON结构如下,其各个字段的意义在上一节流程定义中已经介绍,这里不在重复。
{
"loopType": "for",
"maxIteration": 1000,
"stopCond": {
"index": 1,
"type": "String",
"value1": "",
"operation": "equal",
"value2": ""
}
}
这里需要注意的是:
同步方式运行子流程
支持for和do...while两种循环
异步方式运行子流程
仅支持for循环,因为do...while循环需要获取子流程的输出结果判断,所以不支持这种循环方式
实现
- 同步方式运行子流程
常见的做法是创建子流程实例并推送到消息队列,然后定时轮询子流程状态,子流程结束后就跳出循环。这种方式有一个致命的问题,就是运行子流程节点,会一直阻塞在后台运行。如果出现系统重启,那么这个运行中的子流程节点就会丢失数据。而且这种方式运行会一直占用系统资源,并不推荐。
那么,有什么办法,可以将这种同步阻塞的任务异步化呢?
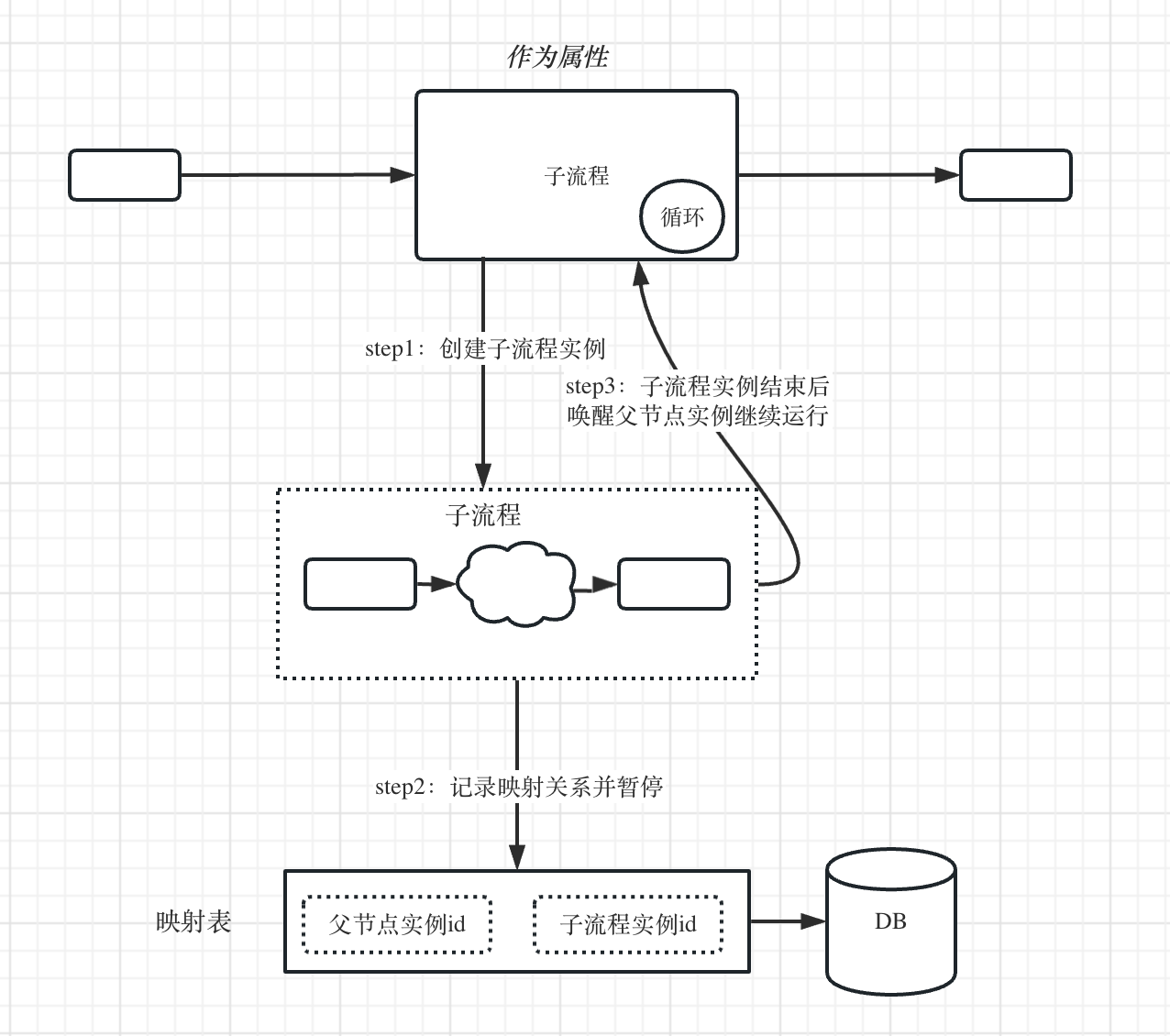
如上图所示,我们在实现上,可以在创建子流程实例后,获取到子流程实例ID,将子流程节点,即父节点实例ID和子流程实例ID的映射关系存储到数据库。
然后该父节点实例就进入暂停状态,这时候的节点实例任务是没有加载到内存中运行的,没有消耗任何的机器资源。
当子流程实例运行结束时,会去维护的映射表上查询是否有关联的父节点实例,如果有,就唤醒这个父节点实例任务继续往下执行。
通过这种方式,就可以将同步运行子流程的方式巧妙地**“异步化”**。
而子流程的同步运行方式的循环实现,你可以理解成本质上就是一个串行的流程任务,并且有一个开关控制运行次数而已。
由于是同步方式运行,只能在上一个子流程实例运行完以后,才能接着运行下一个子流程实例。所以,我们需要对上一步的实现逻辑进行一点改造。如下图所示:
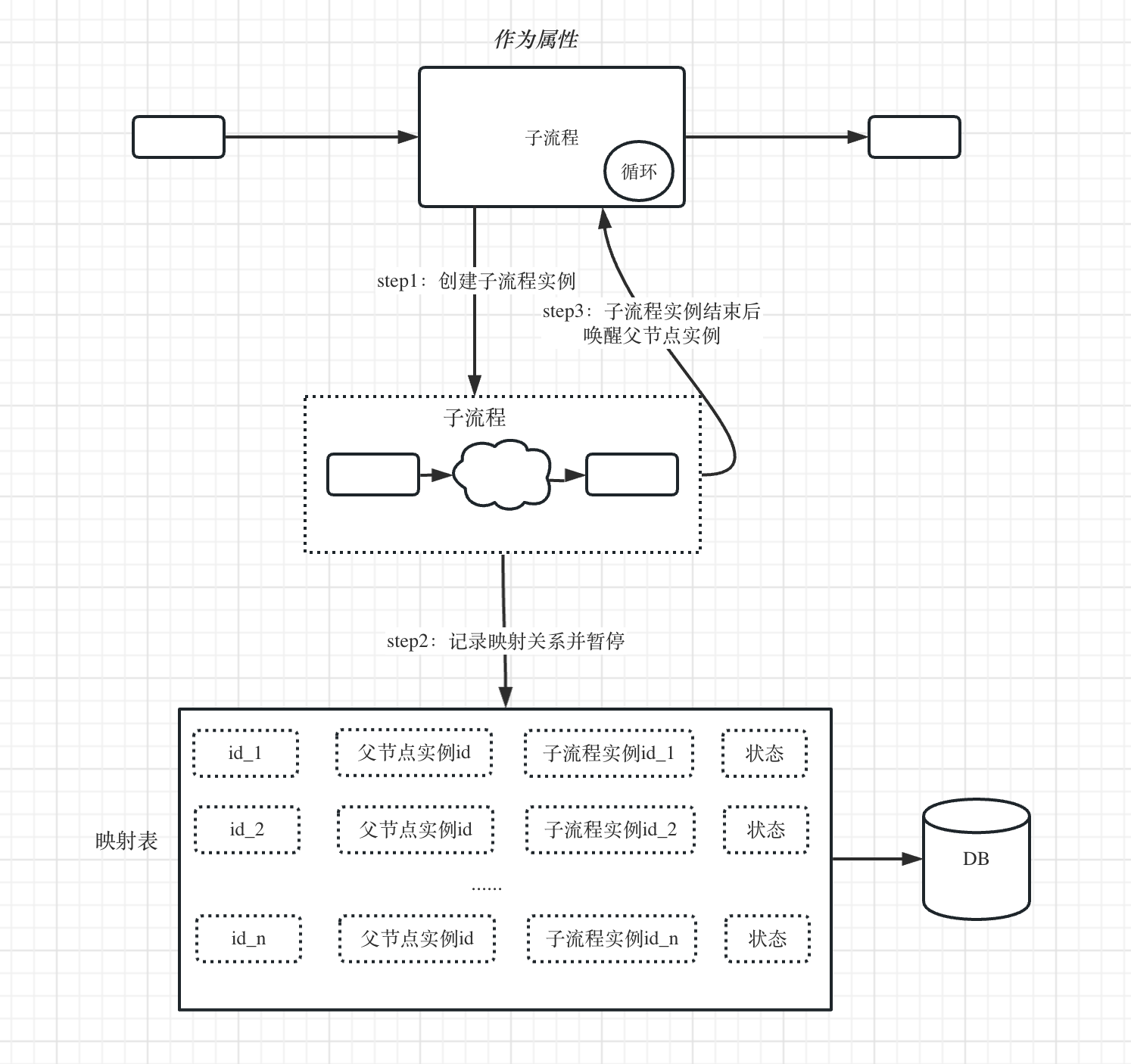
A、在第一次创建子流程实例,这里产生第一条映射关系id_1。
B、子流程运行结束后,查询映射表中是否有未处理的映射关系(状态为:未处理),如果有就唤醒对应的父实例节点任务。
C、父实例节点任务被唤醒后,会判断当前循环条件是否满足或达到最大循环次数
(1) 如果满足,则跳出循环,继续运行下一个节点任务
(2) 如果不满足,则继续创建下一个子流程实例运行,又回到步骤A进入下一个循环
- 异步方式运行子流程
由于异步方式运行子流程,在触发创建子流程实例以后,不等待子流程执行结束,直接运行下一个节点任务。所以不需要像同步方式那样需要一个映射表来维护关系。所以它的循环只支持for方式,不支持do...while方式(无法获取子流程输出结果)。
异步方式的循环,就有点类似编程里面的多线程并发执行功能。
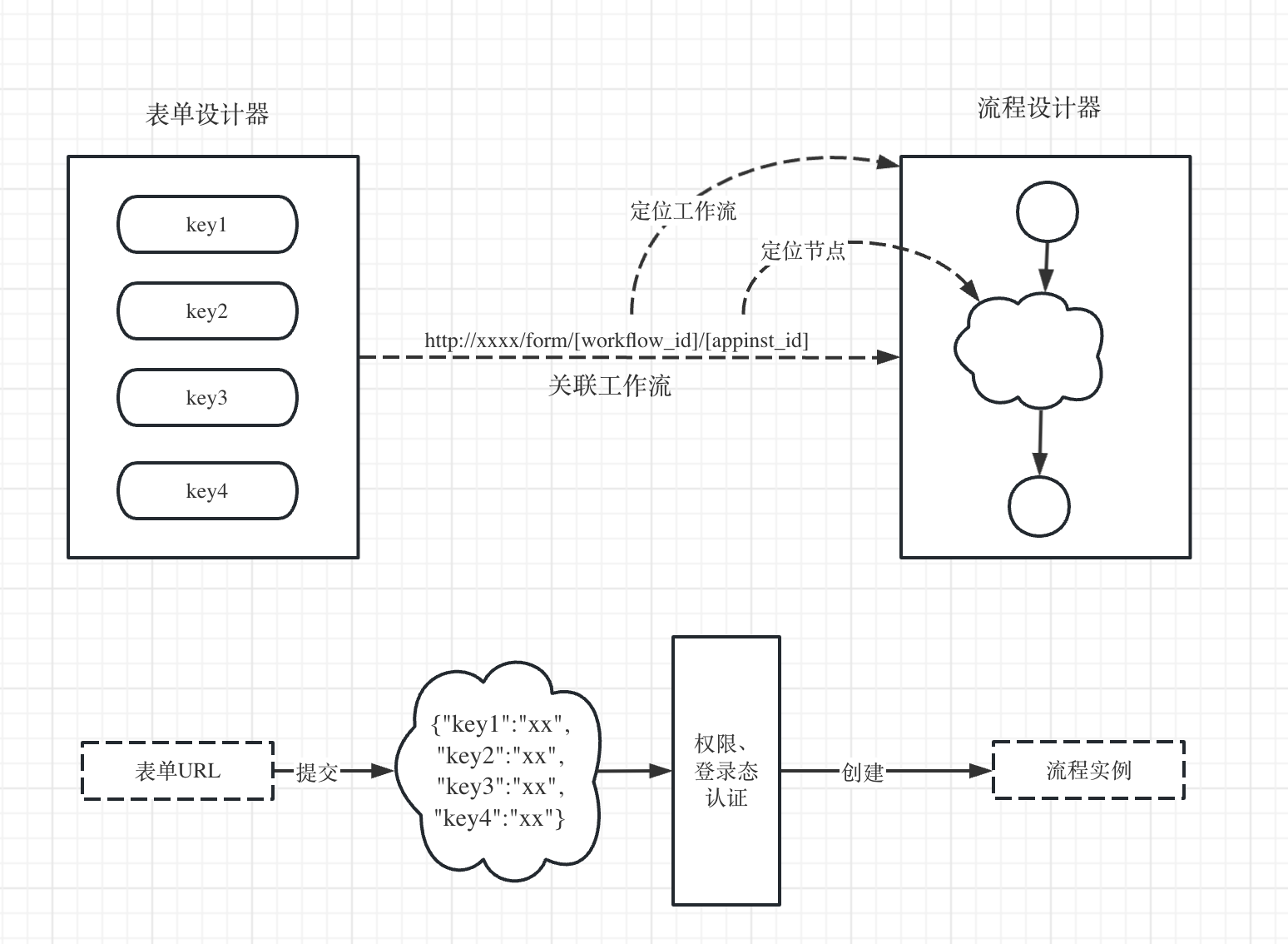
# 人工任务-表单
这里表单任务跟前面的表单节点一样,只不过这个是放在流程中间位置。这里就不重复展开。http://xxxx/form/[workflow_id]/[appinst_id]
# 人工任务-审批
原理
审批节点完整JSON结构如下:
{
"instId": "xxx",
"name": "审批",
"type": "Task",
"description": "审批",
"template": "approval",
"positions": [],
"connections": [],
"parameters": {
"members": {
"label": "members",
"type": "array",
"value": [],
"default": [],
"required": true
},
"title": {
"label": "title",
"type": "string",
"value": "",
"default": "sync",
"required": true
},
"content": {
"label": "content",
"type": "string",
"value": "",
"default": "",
"required": false
},
"attr": {
"label": "attr",
"type": "string",
"value": "会签",
"default": "会签",
"required": false
},
"timeout": {
"label": "timeout",
"type": "integer",
"value": 0,
"default": 0,
"required": false
},
"aggree_btn": {
"label": "aggree_btn",
"type": "string",
"value": "同意",
"default": "同意",
"required": false
},
"disaggree_btn": {
"label": "disaggree_btn",
"type": "string",
"value": "驳回",
"default": "驳回",
"required": false
},
"true_branch": {
"label": "true_branch",
"type": "string",
"value": "",
"default": "",
"required": false
},
"false_branch": {
"label": "false_branch",
"type": "string",
"value": "",
"default": "",
"required": false
},
"timeout_branch": {
"label": "timeout_branch",
"type": "string",
"value": "",
"default": "",
"required": false
}
},
"errorHandler": {},
"loopHandler": {},
"timeout": 0,
"isIgnore": false,
"runtimes": []
}
- members
设置有审批权限的成员。
- title
审批标题。
- content
审批内容。
- attr
审批关系,例如常见的会签、或签。
会签:必须所有审批人都同意,审批才通过,继续到下一个节点。
或签:只要任意一人审批(同意或驳回),审批就结束,继续到下一个节点。
- aggree_btn和disaggree_btn
设置同意和驳回按钮名称,主要是适应一些自定义的场景。
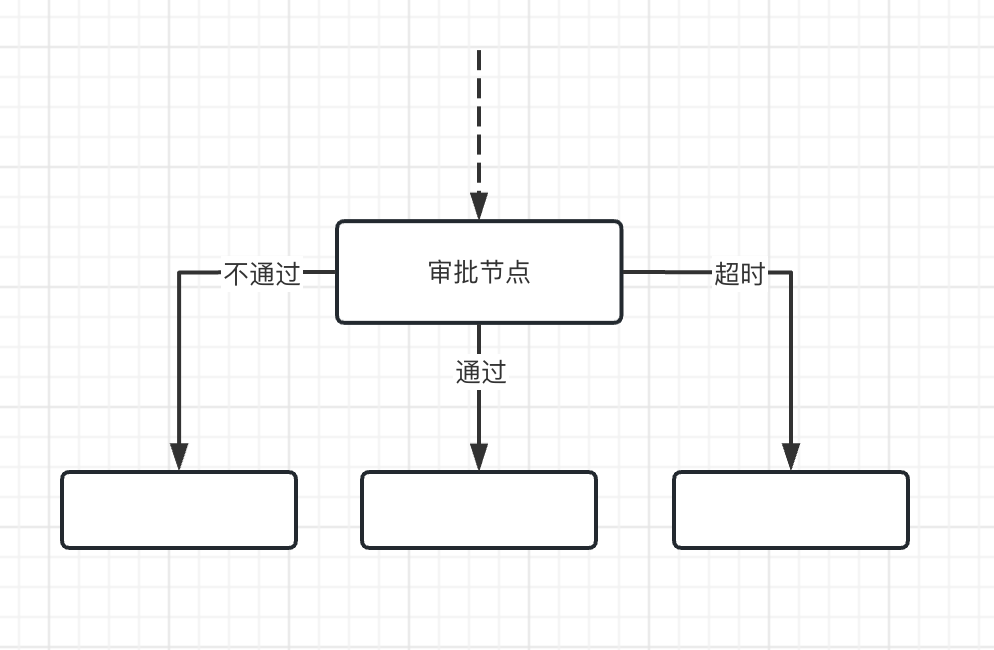
- true_branch和false_branch
设置审批节点通过和不通过的下一个节点。这里如果审批不通过,可以将false_branch连接到前面的分支,实现驳回的功能。
- timeout
审批超时时间,默认0,表示没有超时设置。如果设置了超时时间,则必须连接超时分支,即:timeout_branch指向的下一个节点。
当发起审批后,等待审批的时间超过timeout,就会触发执行timeout_branch分支。
- timeout_branch
超时分支,配合timeout一起使用。
这里仅仅展示的只是节点关联的字段功能。除了运行前设置审批节点,还有运行中审批节点的操作,例如:转移审批、增减审批人等中国特色的审批功能。
实现
如下图所示是审批的实现过程。
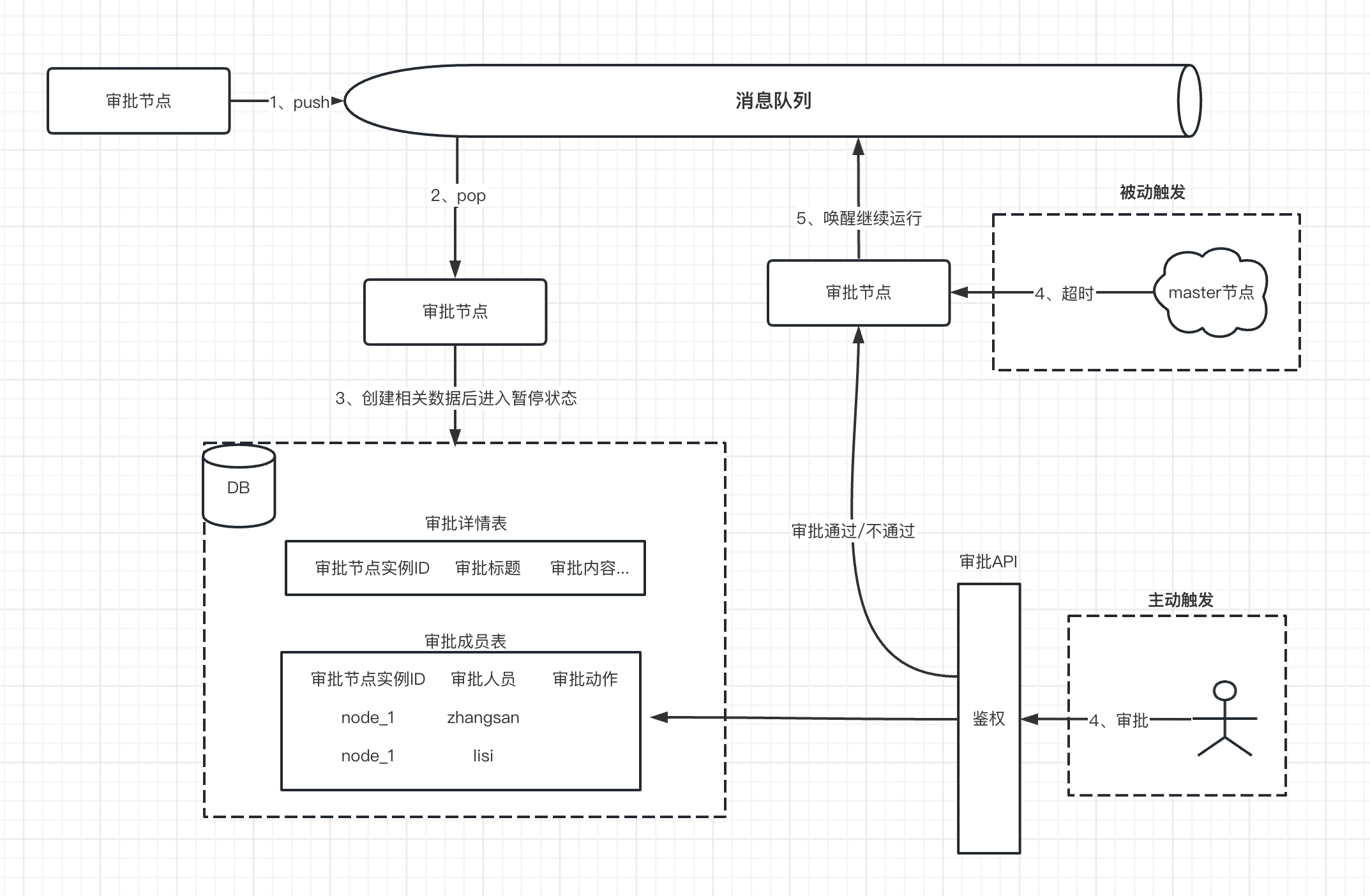
Step1:当第一次运行审批节点(从消息队列消费),这时候需要把审批相关的数据持久化存储到DB中。主要涉及两张表。
在创建好相关审批数据后,这时候就进行暂停状态。等待后续用户的主动审批触发或者审批超时被动触发,唤醒审批节点继续运行。
审批详情表
| 字段 | 说明 |
|---|---|
| execution_id | 当前流程实例ID |
| appinst_id | 审批节点实例ID |
| title | 审批标题 |
| content | 审批内容 |
| attr | 审批关系:会签、或签 |
| aggree_btn | 同意按钮名称 |
| disaggree_btn | 驳回按钮名称 |
| true_branch | 通过分支指向的下一个节点ID |
| false_branch | 不通过分支指向的下一个节点ID |
| timeout | 超时,单位:秒 |
| timeout_branch | 超时分支指向的下一个节点ID |
| result | 审批结果:通过、不通过、超时 |
| create_at | 该条记录创建时间 |
审批成员表
| 字段 | 说明 |
|---|---|
| appinst_id | 审批节点实例ID |
| user | 审批用户 |
| operation | 审批动作:同意、驳回 |
| comment | 审批留言 |
| operate_at | 操作时间 |
| create_at | 该条记录创建时间 |
Step2:主动审批触发或被动超时触发
- 主动审批触发
用户在调用审批接口操作时,系统会通过查询上一步的审批成员数据判断是否有审批的权限或者审批是否结束了。
如果没权限或审批结束,直接返回错误提示给用户。
如果可以审批,这时候就会更新审批成员表中对应改用户记录的operation、comment、operate_at三个字段。
同时,还会根据审批关系(会签、或签)判断当前审批节点是否可以结束。如果未结束,就退出。如果可以结束,则还要更新审批详情表的结果,并且把该审批节点唤醒,即推送到消息队列。
- 被动超时触发
如果审批节点设置了超时时间,则后台worker集群中的master节点会进行监控,只要超过审批时间还未操作,就修改审批详情表的结果,并且把该审批节点唤醒,推送到消息队列。
Step3:当上一步,审批节点被唤醒推送到消息队列。即第二次执行审批节点,这时候主要是获取审批的详情和成员的审批结果数据并返回输出。
然后,引擎会根据审批结果或超时分支选择下一个节点继续运行。
# 脚本任务
原理
脚本节点完整JSON结构如下:
{
"instId": "xxx",
"name": "脚本任务",
"type": "Task",
"description": "脚本任务",
"template": "script",
"positions": [],
"connections": [],
"parameters": {
"language": {
"label": "language",
"type": "string",
"value": "python",
"default": "python",
"required": true
},
"code": {
"label": "code",
"type": "string",
"value": "",
"default": "",
"required": true
},
"timeout": {
"label": "timeout",
"type": "integer",
"value": 60,
"default": 60,
"required": true
},
},
"errorHandler": {},
"loopHandler": {},
"timeout": 0,
"isIgnore": false,
"runtimes": []
}
- language
脚本任务使用的编程语言,例如:python、php、js、shell等常用的编程语言。
- code
代码。
- timeout
脚本执行的超时时间。脚本执行超过这个时间,引擎会强制结束。
实现
脚本任务的实现原理有三种方式。
- 一种是使用本地原生的解释器执行
- 一种方法就是通过内置到引擎的解释器来解释执行
- 最推荐的一种就是调用目前流行的serverless来实现。毕竟流程引擎是负责任务调度而不是执行,所以这种方式是最推荐的脚本执行方法
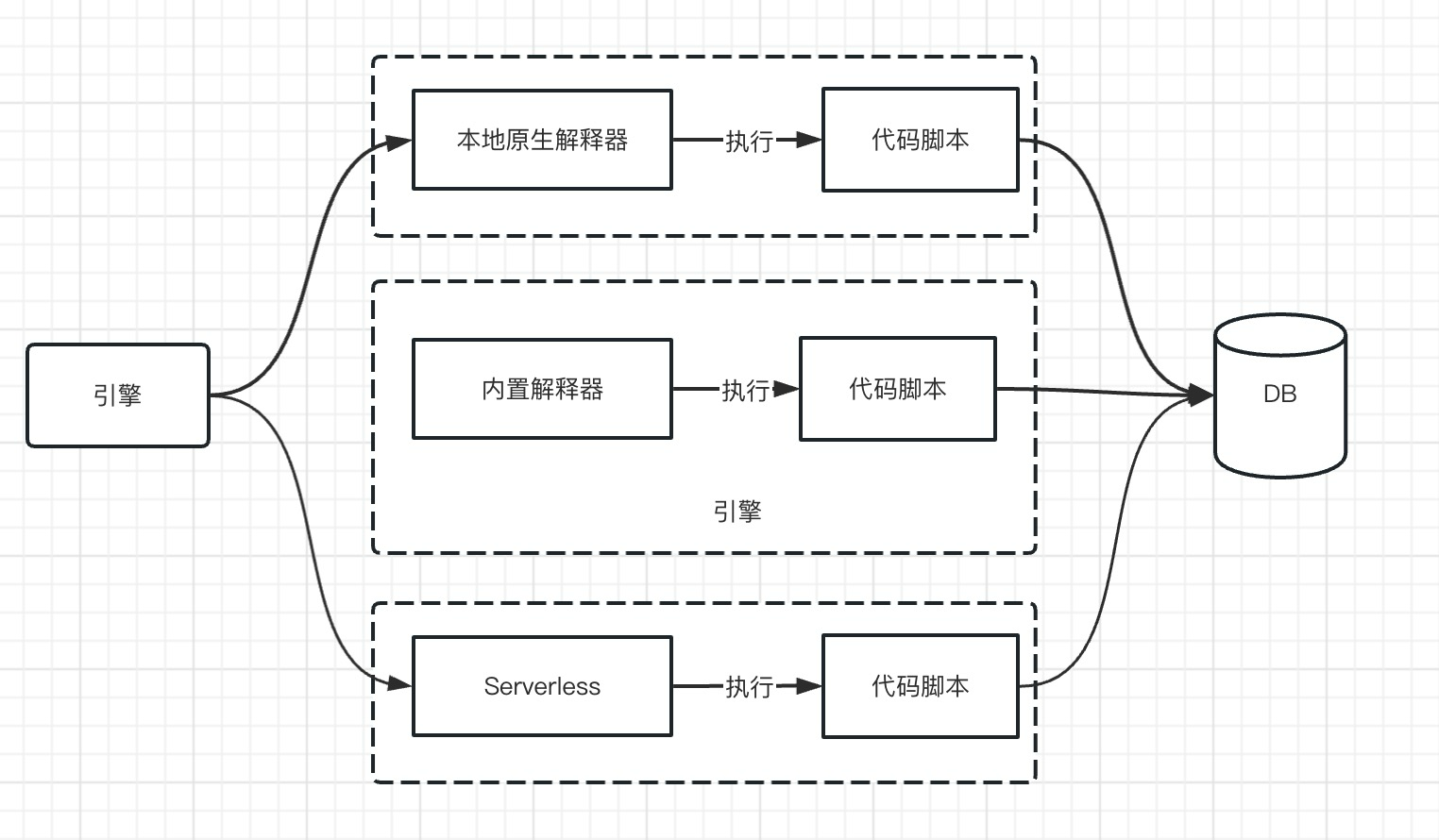
- 本地原生解释器
例如:python解释器、php解释器、nodejs解释器等等。这种就要求物理机或者容器的本地环境要安装好上述python、php、nodejs等编程环境。
然后在执行时,创建代码脚本,引擎会创建一个新的进程通过调用本地解释器来执行代码脚本。这种跟我们平时在命令行下执行代码脚本是一样的。
当然这种频繁的创建、删除文件是很低效率的,优化的做法是可以在本地实现创建好脚本缓存,这种就可以直接执行。
但是这种方式也会带来一定的安全隐患,毕竟是在本地环境执行脚本。
- 内置解释器
在github上就很多开源的内置解释器。可以继承到引擎里。但目前大部分开源的内置解释器功能不太完善,对于一些简单的脚本可以使用。优点是不需要对外部安装环境有依赖。
- Serverless
这种方式通过调用Serverless的云API进行创建、编辑和保存要运行的代码,Serverless会生成一个API提供给引擎进行调度运行。这种方式的一个好处是解耦了脚本执行的繁重逻辑,让引擎完全聚焦于调度上。而且由于脚本执行可能存在恶意代码执行等各种威胁,使用Serverless这种容器技术来执行,可以很好地解决安全上的问题。
# 发送任务
例如邮件发送、短信发送、企业微信消息发送、钉钉消息发送等。这种本质上就是对常用的发送接口进行代码封装,功能上跟使用脚本任务写代码实现是一样的。
不过作为一种比较常见的任务,可以单独封装继承来使用。
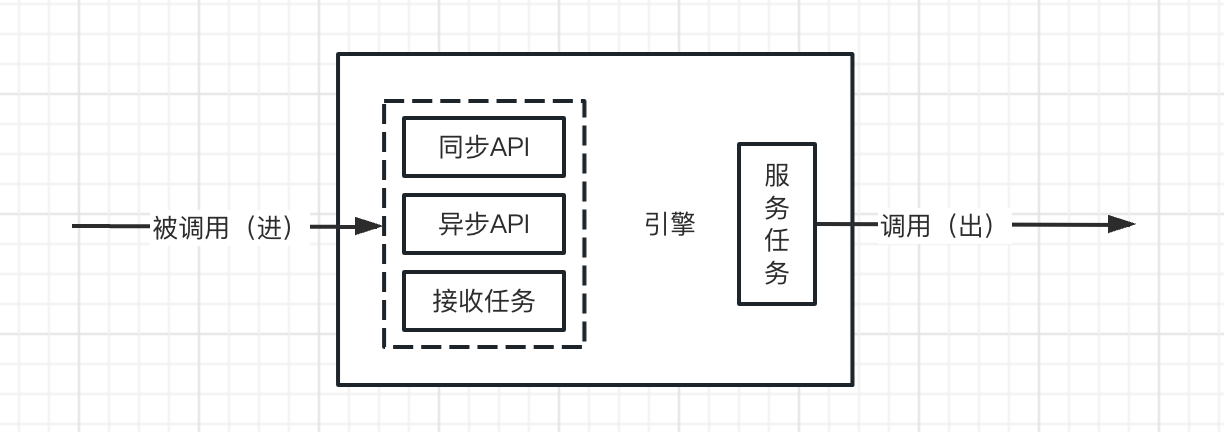
# 服务任务
服务节点主要是通过HTTP或RPC等方式调用第三方服务。
至此,我们可以总结得到,同步API、异步API、接收任务等提供接口服务,实现了被第三方系统集成(被调用)的功能
而服务任务通过接口或RPC等方式调用,实现了第三方系统的集成(调用)。
这4个节点类型实现了:
- 数据流向的一进、一出
- 跟第三方系统的集成和被继承
这就解决了引擎的灵活性和扩展性。
# 变量读写任务
变量读写节点完整JSON结构如下:
{
"instId": "xxx",
"name": "变量读写",
"type": "Task",
"description": "变量读写",
"template": "variable",
"positions": [],
"connections": [],
"parameters": {
"scope": {
"label": "scope",
"type": "string",
"value": "env/local",
"default": "local",
"required": false
},
"operation": {
"label": "operation",
"type": "string",
"value": "read/write",
"default": "",
"required": true
},
"type": {
"label": "type",
"type": "string",
"value": "string/number/bool",
"default": "",
"required": true
},
"key": {
"label": "key",
"type": "string",
"value": "",
"default": "",
"required": true
},
"value": {
"label": "value",
"type": "string",
"value": "",
"default": "",
"required": true
}
},
"errorHandler": {},
"loopHandler": {},
"timeout": 0,
"isIgnore": false,
"runtimes": []
}
原理
可以对流程变量或环境变量进行读写操作。用于在流程执行过程中变量的控制、存储。
- scope
变量分两种类型:
(1)本地变量:作用范围在某个工作流实例内
(2)环境变量:作用范围在某个用户内,即这个用户下不同流程的不同流程实例都可以对流程变量进行读写操作
- operation
变量支持读和写操作。
- type
变量类型,例如常见的字符串(string)、数字(number)和布尔值(bool)
- key
变量名称,注意:
(1)本地变量名称:在工作流实例内不能出现重复
(2)环境变量名称:在用户下不能出现重复
- value
变量值,根据变量类型有所区别。在变量读写节点上设置的value值可以作为默认值。例如第一次读取变量时,就取该值。
(1)string:字符串
(2)number:整数
(3)bool:0/1
实现
变量的读写本质上是将数据更新、存储到数据库内,本质上是数据库的操作。
有三种实现方式:
(1)存储到关系型数据库中(例如:MySQL)
这种方式需要两张表来存储局部变量和全局变量的数据:
本地变量表(local_variable)
| execution_id | key | type | value | create_at | update_at |
|---|---|---|---|---|---|
| 工作流实例ID | 变量名称 | 变量类型 | 变量值 | 创建时间 | 最近更新时间 |
环境变量表(env_variable)
| user | key | type | value | create_at | update_at |
|---|---|---|---|---|---|
| 用户 | 变量名称 | 变量类型 | 变量值 | 创建时间 | 最近更新时间 |
通过调用读写变量节点,其实就是对这两张表的key值进行读和写操作,只不过变量的作用范围不同而已。
DB方式来存储变量一个优势是持久化存储不丢失,劣势就是读写频率不能太高。
(2)存储到缓存中(例如:Redis)
如果通过Redis中间件来实现,由于Redis是存内存的非关系型数据库。其数据的读写效率比上面DB方式实现要高很多,速度也更快。
我们可以通过Redis的SET和GET命令来实现。
- 流程变量
读:
GET local#execution_id#key
写:
SET local#execution_id#key
同时还使用Redis的无序集合SET保存当前工作流实例使用过的流程变量,用于后续工作流实例运行结束时临时数据的清理。
SADD local_variable#execution_id key1
- 环境变量
读:
GET env#user#key
写:
SET env#user#key
Redis方式存储的一个好处是读写速度非常快,劣势是不能存储太多数据。
而且工作流实例在执行完以后,实例里面的变量仍然存储在Redis中,这些数据后期是基本不会用到,持续增长下去会导致Redis内存空间不够。所以最终还是需要通过关系型数据库来落地存储。
所以,这里推荐第三种方案,就是结合数据库和Redis缓存的组合方案,充分发挥两者的优点。
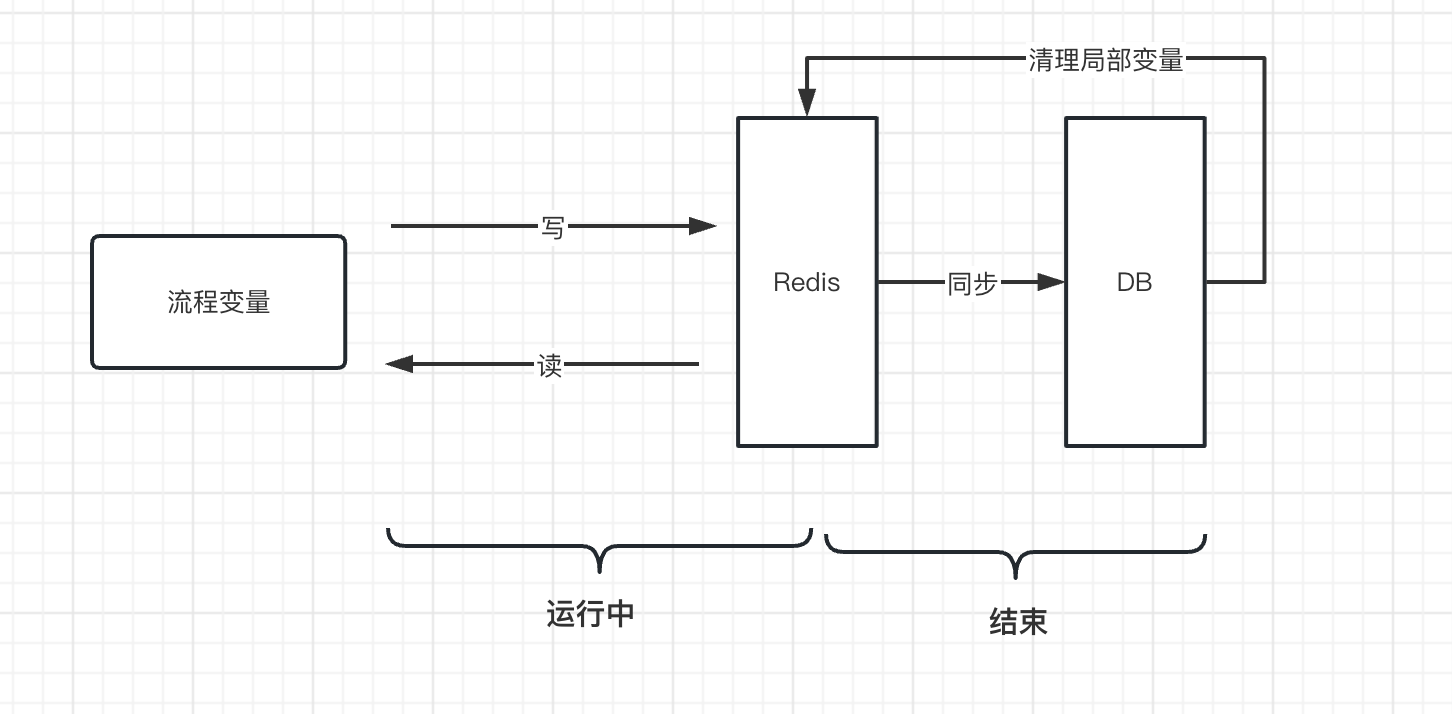
(3)DB+缓存的组合(例如:MySQL+Redis)
如下图,Redis和DB组成一个二级冷热数据分层的存储结构。Redis存储热数据,DB存储冷数据。
读写操作在Redis缓存层操作,工作流实例运行结束时,变量数据才落数据库。这样可以极大提高读写频率,减轻数据库负载。
- 流程变量
- 在工作流实例运行时:读写在Redis缓存上操作
- 在工作流实例结束时:变量数据同步到数据库中,然后清理Redis上跟该工作流实例关联的流程变量
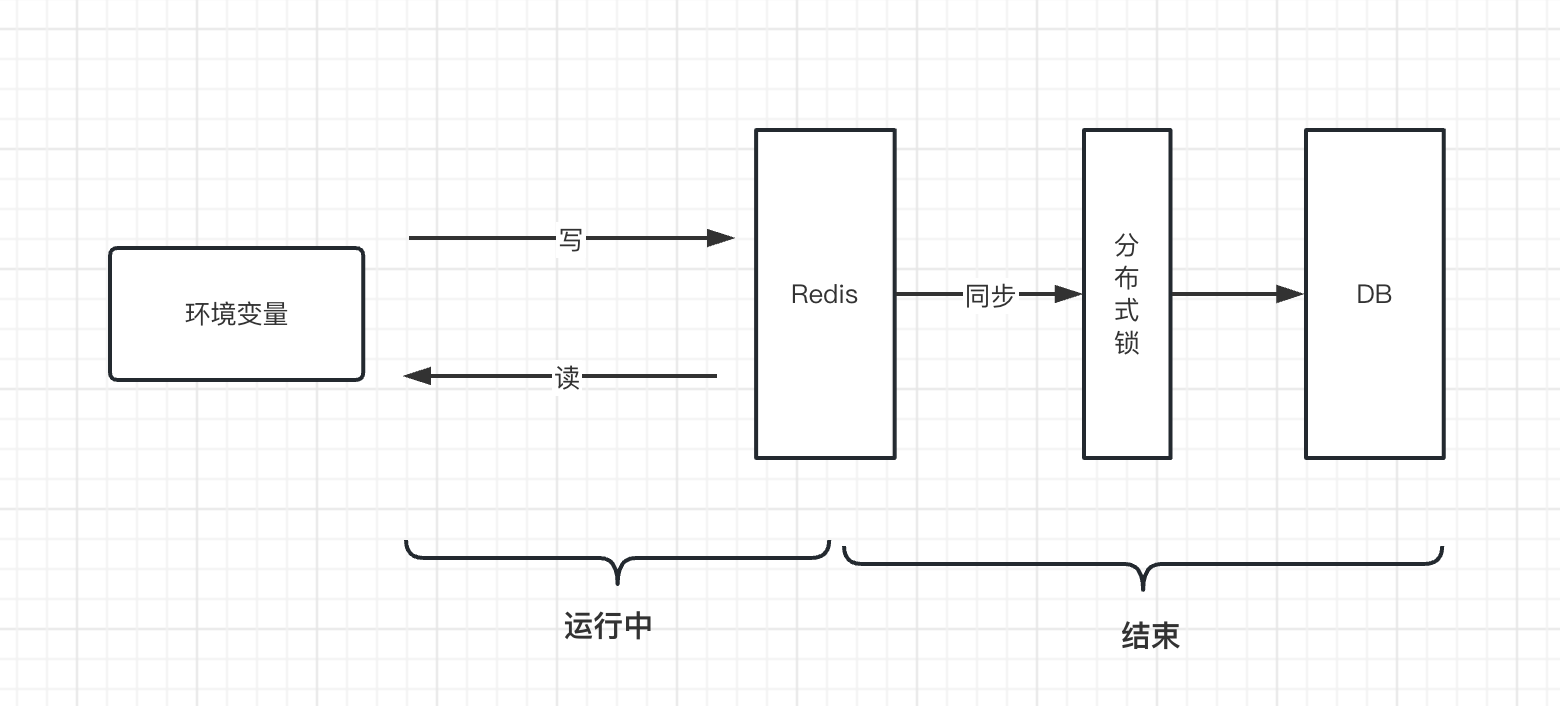
- 环境变量
- 在工作流实例运行时:读写在Redis缓存上操作
- 在工作流实例结束时:由于全局变量是用户空间内,也就是用户下所有工作流实例都可以对环境变量进行读写,在运行结束时,存在并发对数据库的写操作,可能导致存在数据竞争的问题,所以环境变量在工作流实例运行结束时同步数据到DB之前,需要通过分布式锁来保证每次用户名下的某个环境变量同步到数据库这个操作同一时间只有一个线程在操作。
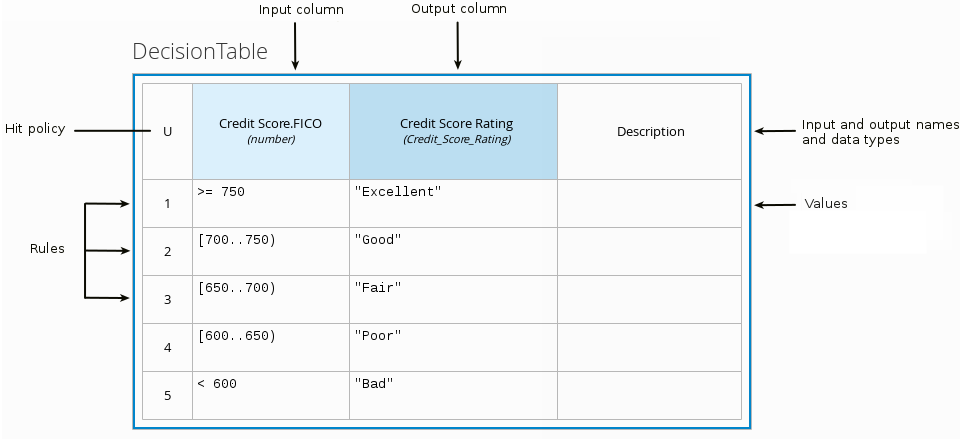
# 业务规则任务
业务规则任务即调用规则引擎来进行决策。业务规则可以说是对业务策略的表达,规则引擎是将打包的规则集合进行解析和执行。
它的实现方式就是if..elseif...else,也就是条件判断的组合。这个其实可以通过后面讲的条件判断节点进行组合实现。
只不过规则引擎通过类似表格的方式进行规则集合的组合,使用起来更加精练方便。
规则引擎是一个很大的主题,可以作为一个新的专题写一本书,这里就不拓展讲,简单提及一下。
