网关节点决定流程的流转方向,本文会介绍几个最常用的网关界定及其结构定义。
基于Petri网分
AND Split 和 AND Join
OR Split 和 OR Join
XOR Split 和 XOR Join
AND表示后续的任务节点同时触发
OR表示后续任务节点可以触发一个或多个,没有排他性,即每个节点任务不会影响其他的节点任务。
XOR表示后续的任务节点只触发一个,有排他性,也就是只能触发其中一个。
基于路由分
顺序路由
分支路由
并行路由
循环路由
# 并行节点
原理
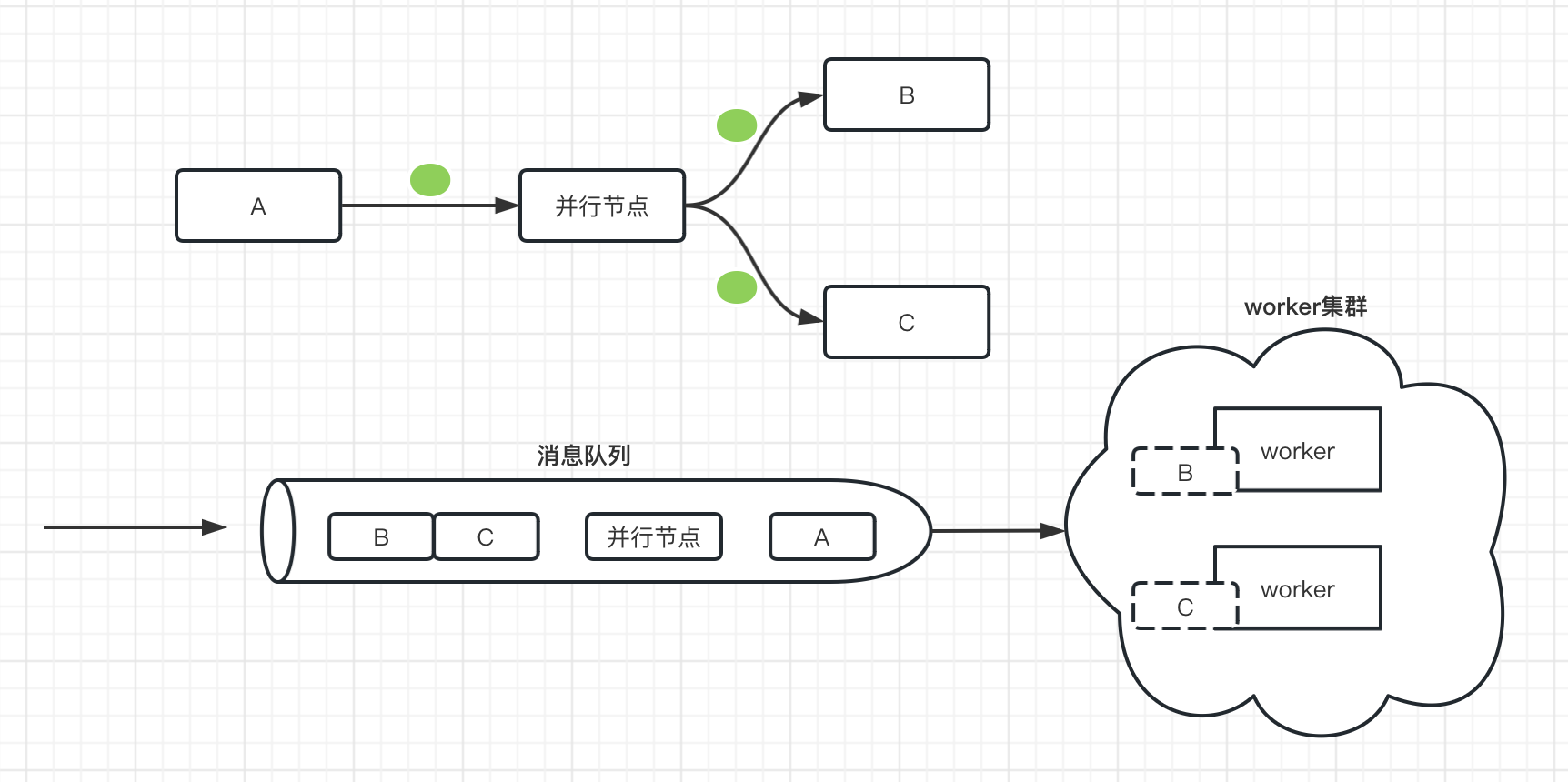
并行节点指向的几条分支节点,可以并行地运行。
如下图,token的流向,在进入并行节点出来后,会根据并行节点的后置节点个数,复制出同样个数的token给下一个节点,这样下一个节点拿到token后就可以执行。
{
"instId": "xxx",
"name": "并行",
"type": "Gateway",
"description": "并行",
"template": "parallel",
"positions": [],
"connections": ["节点1", "节点2"],
"parameters": {
},
"errorHandler": {},
"loopHandler": {},
"timeout": 0,
"isIgnore": false,
"runtimes": []
}
并行节点的定义很简单,在connections里的数组成员即是并行的节点个数,一般跟汇聚Join节点搭配使用,其原理类似go代码里并行之后的wait行为。
func main() {
wg := sync.WaitGroup{}
wg.Add(100)
for i := 0; i < 100; i++ {
go func(i int) { // 并行节点
fmt.Println(i)
wg.Done()
}(i)
}
wg.Wait() // 类似汇聚join节点
}
实现
前面,我们提到,工作流实例中,最基础的执行单元是节点任务实例,它的执行是基于消息队列实现。
在执行完并行节点后,引擎获取到并行节点的下一个节点(>=1个),然后同时将这些后置节点一起推送到消息队列。后端的worker集群快速消费获取到节点任务实例,由于后端的worker集群是多机器的,所以在用户看来B、C节点的执行就是同时的。
# 条件判断节点
原理
条件判断节点完整JSON结构如下:
{
"instId": "xxx",
"name": "条件判断",
"type": "Gateway",
"description": "条件判断",
"template": "condition",
"positions": [],
"connections": [],
"parameters": {
"condition_list": {
"label": "condition_list",
"type": "array",
"value": [
{
"index": 1,
"type": "string/number",
"value1": "aaa",
"operation": "equal/not_equal/contain/not_contain/start_with/not_start_with/end_with/not_end_with/regex",
"value2": "bbb"
}
],
"default": [],
"required": true
},
"relation": {
"label": "relation",
"type": "string",
"value": "or/and",
"default": "or",
"required": true
},
"false_branch": {
"label": "false_branch",
"type": "string",
"value": "",
"default": "",
"required": false
},
"true_branch": {
"label": "true_branch",
"type": "string",
"value": "",
"default": "",
"required": false
}
},
"errorHandler": {},
"loopHandler": {},
"timeout": 0,
"isIgnore": false,
"runtimes": []
}
- condition_list
condition_list是由一系列的条件组合合成。每个条件的字段功能描述如下:
(1)index:表示条件数组中第几个成员
(2)type:条件中对比的数据类型,一般包括字符串(string)和数字(number)
(3)operation:两个要对比的数据采用哪种对比关系。
对于字符串(string)类型的数据,value1和value2其对比关系如下:
a. equal:等于
b. not_equal:不等于
c. contain:包含
d. not_contain:不包含
e. start_with:以什么开头
f. not_start_with:不以什么开头
g. end_with:以什么结尾
h. not_end_with:不以什么结尾
i. regex:其中value1为正则表达式,value2为被判断是否符合value1的正则表达式
对于数字(number)类型的数据,value1和value2其对比关系如下:
j. gt:大于
k. gte:大于等于
l. lt:小于
n. lte:小于等于
o. equal:等于
p. not_equal:不等于
q. value1和value2:要比较的两个数据。这里除了常量,还可以使用后面介绍的变量表达式在运行时动态解析对比。
- relation
由于条件判断可以由多个条件组合合成,这些组合的条件关系可以使用如下两种:
a. or(或):表示只要有一个条件为真,则返回真,否则返回假
b. and(且):表示只有全部为真,则返回真,否则有一个假就返回假
在运行到条件判断节点,引擎会根据节点的执行结果(true或false),选择下一个要运行的节点B或C。
如下图,token进入条件判断节点出来后,只选择其中一个分支传递,也就是说另一个没有被传递token的节点就无法执行。
- false_branch
节点输出结果为false时流转的分支节点
- true_branch
节点输出结果为true时流转的分支节点
实现
实现上也是基于消息队列,只不过条件判断节点运行结束后,只会选取后置节点中的一个来执行,即推送到消息队列。
# 事件网关节点
原理
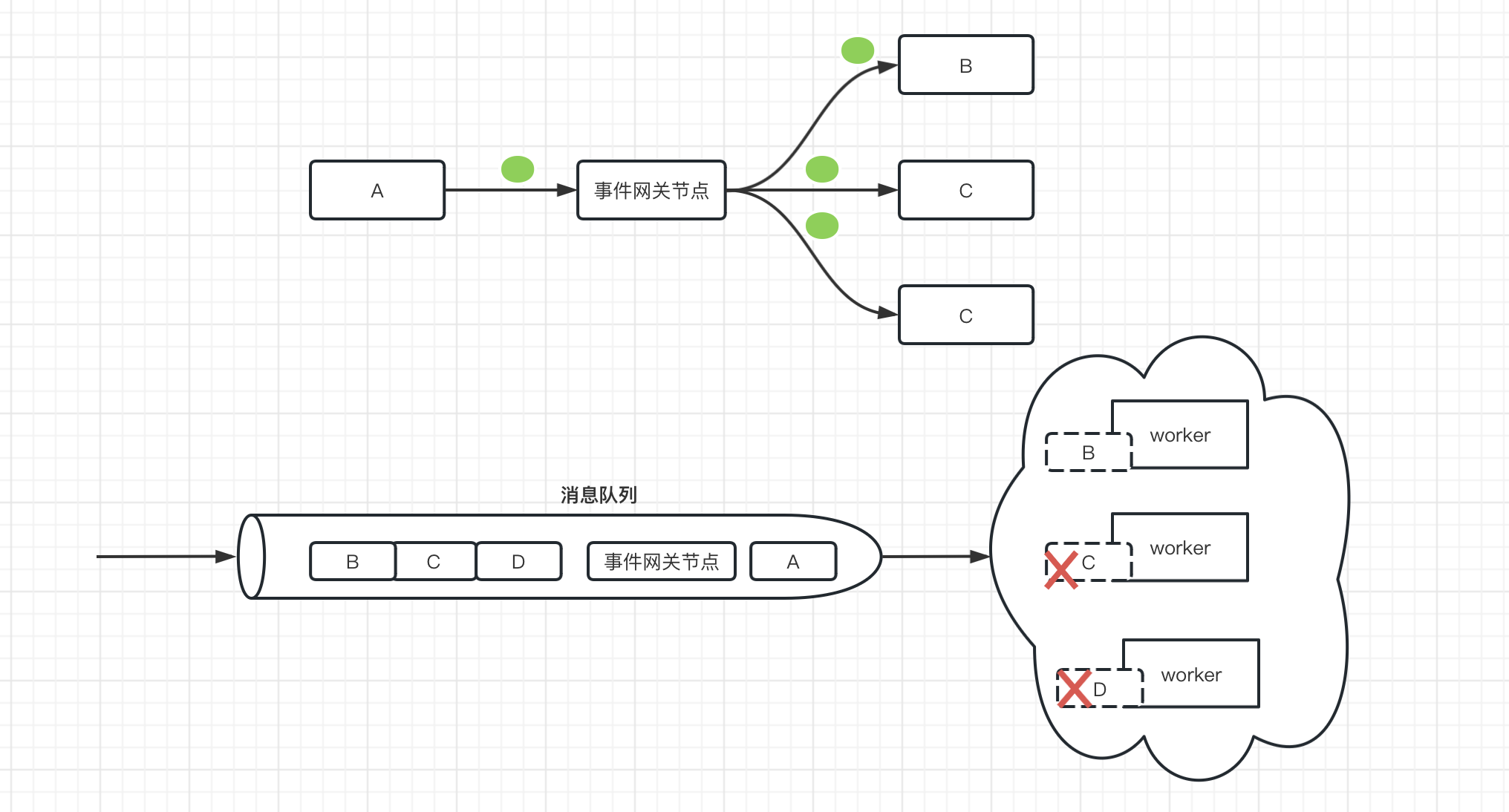
如下图,token在流入事件网关节点流出后,会复制跟后置节点同样个数的token,也就是说事件网关的后置节点会同时运行。
但是,不同的是,只要有任意一个后置节点运行结束,则另外其他几个后置节点就被强制终止运行,具有排他性,这是跟并行节点的区别所在。
实现
实现上前面步骤跟的并行节点一样。后面还要加多一个实现,就是只要有一个后置节点执行结束,就立刻强制终止其他几个后置节点。
# 汇聚Join节点
原理
汇聚节点完整JSON结构如下:
{
"instId": "xxx",
"name": "汇聚",
"type": "Gateway",
"description": "汇聚",
"template": "aggregation",
"positions": [],
"connections": [],
"parameters": {
"prev_instid_list": {
"label": "prev_instid_list",
"type": "array",
"value": [],
"default": [],
"required": true
},
"relation": {
"label": "relation",
"type": "string",
"value": "all/anyone/specific",
"default": "all",
"required": true
}
},
"errorHandler": {},
"loopHandler": {},
"timeout": 0,
"isIgnore": false,
"runtimes": []
}
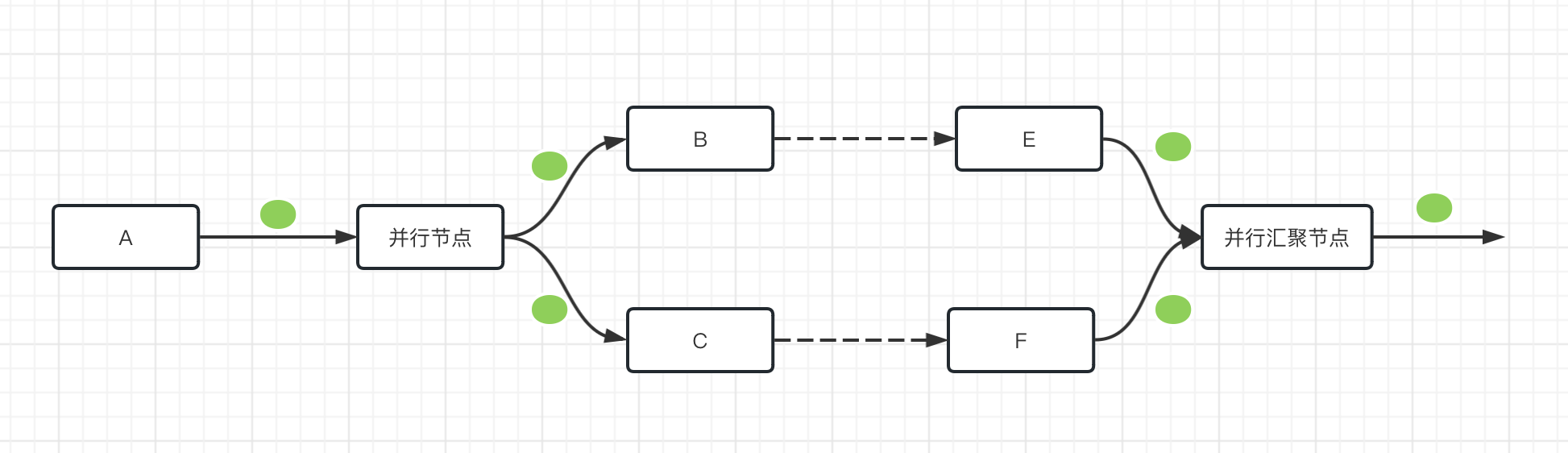
汇聚节点一般是要跟并行节点组合使用。只有满足汇聚节点条件后,才会继续往下执行。
汇聚可以设置的条件有以下几种情况(relation字段),假设前置节点有n个。
all:所有n个前置节点全部完成(相当于Petri网的AND Join)
any:任意一个前置节点运行完成(相当于Petri网的OR Join)
specific:指定m(1<m<n)个前置节点完成(prev_instid_list数组成员)(相当于Petri网的OR Join)
如下图,token从汇聚节点流出后,又汇聚变成一个。
实现
- Step1:每次汇聚节点的前置节点任务执行完,就将运行数据记录到下表
| 字段 | 说明 |
|---|---|
| execution_id | 工作流实例ID |
| aggregation_appinst_id | 汇聚节点实例ID |
| previous_appinst_id | 汇聚节点的潜前置节点实例ID |
- Step2:每次运行汇聚节点,引擎都从上表中获取前面已经执行过的前置节点实例。然后对比节点设置的完成条件是否满足。如果不满足,则不运行下一个节点,继续回到Step1。如果满足条件,则继续运行下一个节点。
注意:由于系统可能是在分布式环境,分布式汇聚节点任务的执行要通过分布式锁,保证每次执行当前工作流实例ID的并行节点实例只有一个,其余未得到分布式锁的任务可以轮询100ms来等待分布式锁释放。这样可以避免出现并发操作数据的情况。
备注:分布式锁的实现可以通过ETCD、Redis分布式锁等方式实现。
