流程建模这部分内容,我会从流程定义、事件节点定义、任务节点定义和网关节点定义四大部分来展开介绍。让你了解如何设计一个流程建模语言,包括工作流的定义、节点的定义和分类(事件、任务和网关)、运行时数据的定义以及事件类型定义;
流程定义这一节内容,主要介绍工作流、节点和运行时数据的JSON结构怎么设计。
# 流程定义
传统BPMN采用XML的语言来定义流程,虽然描述很完整,但是其描述复杂,比较难上手理解。
区别于传统做法,我们采用Json这种互联网上更通用的格式来定义流程,这种数据格式在系统之间也更容易传递交互、更容易理解。
如下是,一个完整的工作流定义。
需要注意,workflow流程定义是一个静态数据,其运行时的数据execution,即流程实例则是动态数据。一个流程(workflow)被执行时,会产生流程实例(execution),这个流程实例也会包含流程定义的结构,同时也包含此次运行时的数据,他们是一对多的关系。
以下数据工作流定义的字段结构:
# workflow定义
| 属性 | 说明 | 是否必须 |
|---|---|---|
| id | 工作流ID,唯一标识工作流的身份 | 是 |
| name | 工作流名称 | 是 |
| description | 工作流描述 | 否 |
| version | 工作流版本 | 否 |
| startTaskInstId | 工作流开始运行的节点。默认为空,表示从流程实例的节点开始运行。 | 否 |
| endTaskInstId | 工作流运行结束时的节点。默认为空,表示运行到流程实例结束为止。 | 否 |
| engine | 引擎类型,支持:快速模式(fast)、标准模式(standard),默认是标准模式。两者区别见《引擎执行模式》一节内容。 | 是 |
| status | 工作流状态,状态轮转见后面内容。 | 是 |
| creator | 工作流创建人 | 是 |
| executor | 工作流执行触发人 | 否 |
| timeout | 工作流执行的超时时间,默认为0表示没有时间限制。 | 否 |
| inputDataSchema | 声明和验证工作流的输入数据。 | 否 |
| outputDataSchema | 声明和验证工作流的输出数据 | 否 |
| error | 工作流执行的错误信息 | 否 |
| extension | 扩展字段可以用来设置并发限制等附加信息,以此来增强工作流的定义 | 否 |
| metadata | 元数据主要用来存储工作流核心定义之外的信息,例如作者邮件、环境信息、分类等 | 否 |
| nodes | node节点数组 | 是 |
其Json结构参考如下:
{
"id": "1541815603606036480",
"name": "Unknown",
"description": "",
"startTaskInstId": "",
"endTaskInstId": "",
"engine": "fast",
"status": "",
"creator": "admin",
"executor": "",
"timeout": 0,
"inputDataSchema": {
"string_value": {
"type": "string",
"max": 100,
"min": 10,
"default": "",
"required": true
}
},
"outputDataSchema": {
"string_value": {
"type": "string",
"max": 100,
"min": 10,
"default": "",
"required": true
}
},
"error": "",
"extension": {
"rateLimit": 10
},
"metadata": {
"email": "xxx@qq.com"
},
"nodes": [
{
"instId": "xxx",
"name": "脚本任务执行",
"type": "task",
"description": "执行脚本任务",
"template": "script",
"positions": [],
"connections": [],
"parameters": {
"code": {
"label": "代码",
"type": "string",
"value": "",
"default": "",
"required": true
}
},
"errorHandler": {},
"loopHandler": {},
"timeout": 0,
"isIgnore": false,
"runtimes": [
{
"index": 0,
"startAt": 1700063265000,
"endAt": 1700063307000,
"status": "done",
"error": "",
"input": {
"code": "xxx"
},
"output": "ok"
}
]
}
]
}
各个属性介绍如下:
id
工作流的ID,可以使用数据库的自增长生成的唯一ID,也可以使用类似UUID算法或者twitter的雪花算法生成唯一的ID。
name
工作流名称。
description
可用于提供有关工作流的更多信息。
version
可以指定工作流的具体版本,版本格式采用通用的格式:主版本号.次版本号.修订号,版本号递增规则如下:。
主版本号:当出现不兼容的大版本变动
次版本号:当做了向下兼容的功能性新增
修订号:当做了向下兼容的问题修正
startTaskInstId
指定工作流执行时起始运行节点,默认情况下为空表示由默认的起始节点开始。
endTaskInstId
指定工作流执行的终止节点,即执行到该节点,则停止执行。
engine
工作流运行时选择使用的引擎类型,分别有快速模式和标准模式。两种模式执行有区别,快速模式适合执行时间短、运行速度快、任务量大的业务流程,例如API服务等。标准模式适合长时间运行的业务流程,例如审批等。两者的具体在下一章会详细介绍。
status
表示工作流的运行状态,详细见下一章流程实例生命周期介绍:
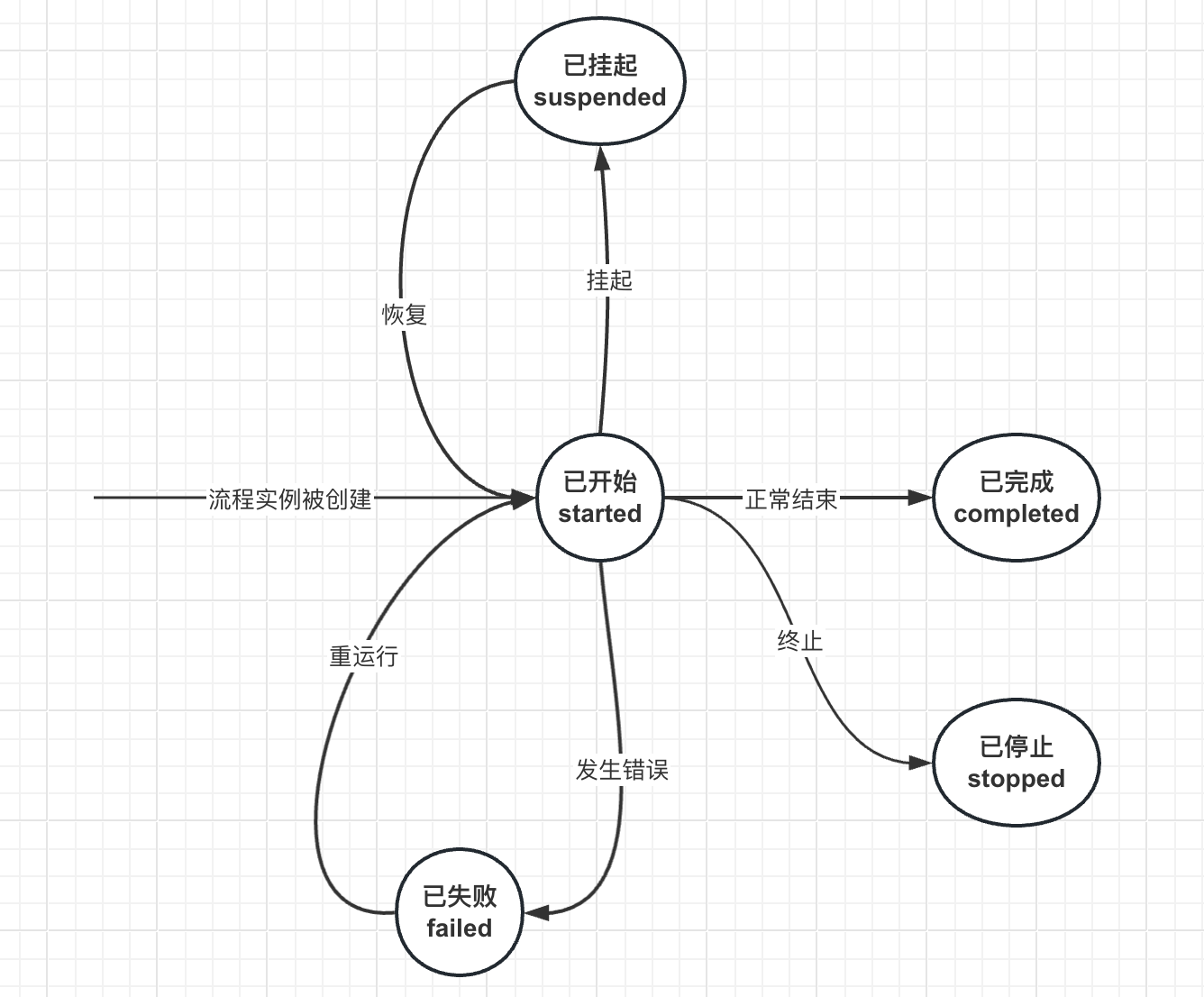
creator
表示工作流的创建人。
executor
表示触发工作流执行的人,例如在表单提交时可以通过登录态获取提交表单的用户,默认则是工作流创建人。
timeout
指定工作流运行的最长时间,超过该时间后,引擎会强制终止流程中所有运行中的任务实例,并将status字段设置为已停止状态。
inputDataSchema
用于声明和验证工作流接收的参数类型,如果不符合声明的要求,则无法触发工作流运行。其格式参考如下。
主要定义输入参数的类型,包括基本的字符串(string)、整数(integer)、浮点数(float)、布尔值(boolean),以及默认值、是否必填等校验信息。这样可以在触发工作流运行之前,检查输入参数是否符合要求。这个在设计API类型的工作流时用的最多。例如下面的例子:
{
"input_string_value": {
"type": "string",
"max": 100,
"min": 10,
"default": "",
"required": true
},
"input_integer_value": {
"type": "integer",
"max": 200,
"min": 0,
"default": 0,
"required": false
},
"input_float_value": {
"type": "float",
"max": 1.0,
"min": 0.0,
"default": 1.0,
"required": false
},
"input_boolean_value": {
"type": "boolean",
"default": false,
"required": false
}
}
outputDataSchema
功能跟inputDataSchema类型,主要用于声明校验工作流的输出结果。如果不符合声明的要求,则会导致报错信息(存储在error字段),并修改status状态为错误。
error
记录工作流在运行时发生异常的错误信息,可用于排查故障。
extension
该属性用于增强扩充工作流功能的定义,例如设置工作流的并发度,或者设置工作流的运行KPI指标等信息。
例如下面定义了每秒钟该工作流同时能触发运行的工作流实例个数,类似于API限频控制每秒并发数。
{"rateLimit":10}
metadata
该属性存储一些工作流的元数据,这些元数据不影响工作流的运行,例如工作流创建者的联系方式等信息。
例如:
{"email":"xxx@qq.com"}
# node节点定义
如下图所示,是BPMN建模语言中包含的各种基础元素,包括任务、事件以及网关元素。BPMN建模语言虽然描述的元素非常丰富全面,但我们在实际的使用过程中,发现绝大部分元素是几乎用不到的。本着二八原则和实用角度出发,我们对BPMN的任务、事件和网关元素进行了精简,剥离出使用最频繁的元素进行定义总结。
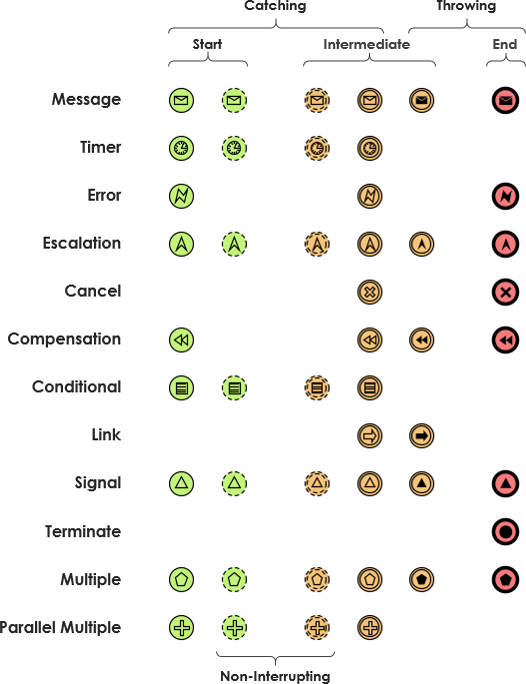
下面构成一个流程的四个基础元素:
| 元素 | 符号 | 描述 |
|---|---|---|
| 任务(Task) |  | 流程中执行具体任务的节点 |
| 事件(Event) |  | 在流程实例运行过程中发生的事件,例如开始、结束等 |
| 网关(Gateway) |  | 控制流程的数据流转和路由决策方向 |
| 箭头(Flow) |  | 箭头用于说明节点之间的流向以及依赖关系,这里直接用connections定义 |
下面是节点的各字段定义:
备注:在这里,我们把前面任务、事件和网关三个基础元素都统一用node节点来定义JSON结构,其区别通过type字段来标识,不同类型的节点,其区别在parameters里体现。
| 属性 | 说明 | 是否必须 |
|---|---|---|
| instId | 流程中每个节点都有唯一的id来标识 | 是 |
| name | 节点名称 | 是 |
| type | 节点类型,包括:任务(Task)、事件(Event)和网关(Gateway) | 是 |
| description | 节点描述 | 否 |
| template | 节点模板,不同模板类型的节点代表执行不同的功能 | 是 |
| positions | 节点在流程设计器平面上的x、y坐标位置 | 是 |
| connections | 当前节点指向的下一个节点(大于等于0),最后的叶子节点为空数组 | 否 |
| parameters | 不同节点模板,其输入参数不一样,是一个Json的结构的对象。 | 是 |
| errorHandler | 错误处理器 | 否 |
| loopHandler | 循环处理器 | 否 |
| timeout | 节点运行的最大时长 | |
| isIgnore | 当前节点是否忽略运行。如果设置为true,则运行时,引擎会检测到该标识并跳过该节点不执行,接着执行下一个节点 | 否 |
| runtimes | 运行时数据,它是一个runtime结构体数组。每个runtime包括运行时间、运行时的入参数据、输出结果等 | 是 |
其Json结构参考如下:
{
"instId": "xxx",
"name": "脚本任务执行",
"type": "Task",
"description": "执行脚本任务",
"template": "script",
"positions": [],
"connections": [],
"parameters": {
"code": {
"label": "代码",
"type": "string",
"value": "",
"default": "",
"required": true
}
},
"errorHandler": {},
"loopHandler": {},
"timeout": 0,
"isIgnore": false,
"runtimes": []
}
同样的,这里节点(node)定义是静态数据,其运行时会产生节点实例这种动态数据(nodeInst),每个节点实例都会包含节点定义的数据结构,也包含运行时的数据。两者也是一对多的关系。
instId
任务的实例ID,流程中每个节点的实例ID都是唯一的,可以采用UUID算法生成或者使用twitter的雪花算法生成,这里推荐后者。因为雪花算法生成的ID唯一且成增长趋势,可以避免ID随机导致的数据库主键插入顺序频繁排序引致的低效率问题,而且也方便后续分表时作为全局唯一的分布式主键ID。
name
描述节点名称
type
描述节点类型,包括:任务(Task)、事件(Event)和网关(Gateway)
description
描述节点的功能
template
节点的类型,包括:起始节点、节点、数据流控制节点三大类,更具体可以参考下一章内容。
positions
描述节点在流程设计器上坐标位置,主要用于在浏览器上图形化渲染展示。
connections
当前节点指向的下一个节点实例ID,如果数组有多个实例ID,则可能是并行节点。如果是流程的叶子节点,即最后一个节点,则该属性为空数组。
parameters
定义当前节点的入参属性,采用字典结构,每个入参key属性对应label、type、value、default、required五个字段,例如下面的json结构。
label
描述入参的名称
type
描述入参的类型,包括:字符串(string)、整数(integer)、浮点数(float)、布尔值(boolean)等
key
描述入参的唯一key值标识。注意节点中的parameters数组里的成员每个key值都是不重复的,这个主要用于定位表示字段的位置。在后面介绍的变量表达式中也会用到,用于引擎在运行时定位节点的参数位置。
value
描述入参的值。
default
描述入参的默认值。
required
描述入参是否必填
{
"name": {
"label": "名字",
"type": "string",
"value": "zhangsan",
"default": "无",
"required": true
},
"age": {
"label": "年龄",
"type": "integer",
"value": 30,
"default": 10,
"required": false
}
}
errorHandler 错误节点
其JSON结构如下:
{
"operation": "stop",
"retryCount": 0,
"retryInterval": 0,
"exception_branch":"xxx"
}
其中operation字段支持的动作包括:
- stop:发生错误,则直接停止往下执行
- ignore:发生错误,忽略,继续往下执行
- catch:发生错误,捕获并响应,执行异常分支的流程(exception_branch分支指向的节点)
- retry:发生错误,重试retryCount次,每次之间间隔是retryInterval秒
loopHandler循环处理器
其JSON结构如下:
{
"loopType": "for",
"maxIteration": 1000,
"stopCond": {
"type": "String",
"value1": "",
"operation": "equal",
"value2": ""
}
}
其中loopType支持for循环和do...while循环
两种循环模式都支持设置最大循环次数maxIteration。
其中do...while循环需要设置循环终止的条件,即stopCond字段。
终止条件的判断支持常见的字符串、数字对比方式。
timeout
设置当前节点运行的最长时间,超过该时间,引擎会强制终止,并设置当前任务实例为超时状态。
isIgnore
设置当前节点在运行时是否要忽略不执行,直接运行下一个节点。这个功能一般用在调试的时候用。
runtimes
节点的运行时数据,如果节点被多次运行,则会生成多个runtime结构体数据,详细见下面介绍。
# runtime定义
| 属性 | 说明 |
|---|---|
| index | 索引位置。由于流程中一个节点可能被执行多次(例如审批打回或循环),这里通过index递增来区分不同task实例,它是依次递增的。 |
| startAt | 任务实例运行开始时间 |
| endAt | 任务实例运行结束时间 |
| status | 任务实例的状态 |
| error | 任务实例运行时发生异常时的错误信息 |
| input | 运行时的入参数据,跟task结构体的parameters一一对应,是key、value的字典结构。前面node节点定义中的parameters是定义时的静态数据,可能是常量、也可能是变量表达式(运行时解析)。而这里的input则是节点运行时的动态数据,可能是常量、也可能是变量表达式运行时解析后的数据。两种是一个静态、一个动态数据的区别。 |
| output | 任务实例运行时的输出结果。其数据类型可以是字符串、数字、布尔值、数组、或复杂的对象结构。 |
其Json结构参考如下:
{
"index": 0,
"startAt": 1700063265000,
"endAt": 1700063307000,
"status": "done",
"error": "",
"input": {
"code": "xxx"
},
"output": "ok"
}
index
描述任务实例运行的顺序,如果节点只运行一次,则index为0,即第一个被运行的任务实例。如果节点被多次运行,例如在审批打回或者循环的场景,则index依次递增。也就是说,runtime这里存储的是任务的运行时数据,即任务实例,这里可以是多个。
startAt
任务实例开始运行的时间,格式采用UNIX毫秒时间戳。
endAt
任务实例运行结束的时间,格式采用UNIX毫秒时间戳。跟startAt相减可以精确计算出任务实例毫秒级的运行耗时。
status
任务实例的状态,详细见下一章任务实例生命周期的介绍。
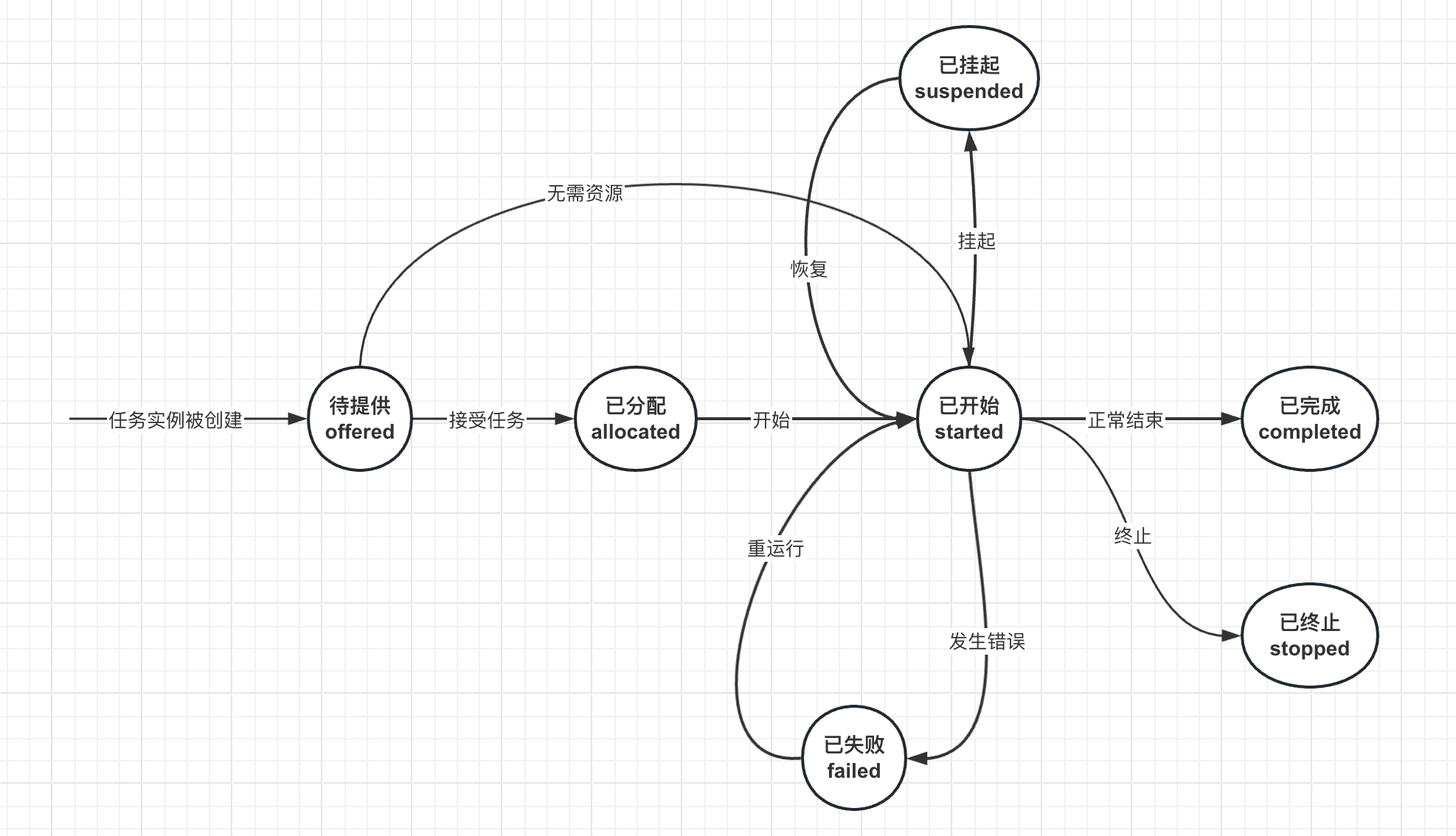
input
任务实例运行时的入参数据,这里跟task结构体的parameters一一对应。
例如task的parameters定义如下:
{
"name": {
"label": "名字",
"type": "string",
"value": "zhangsan",
"default": "无",
"required": true
},
"age": {
"label": "年龄",
"type": "integer",
"value": 30,
"default": 10,
"required": false
}
}
那么任务实例在运行时的input结构如下,采用key、value的字典结构。
{"name":"zhangsan", "age":30}
之所以还要记录任务实例运行时的入参数据,主要是因为在定义task任务的parameters时,它的参数value可以是变量表达式的形式,即在运行时根据上下文数据动态解析,并不是都是固定常量。
output
任务实例运行的输出,其数据类型可以是字符串、数字、布尔值、数组、或复杂的对象结构。
← 3.1 流程建模语言发展概述 事件节点定义 →