# 事件定义
按在流程中的处理阶段分类,如下表所示:
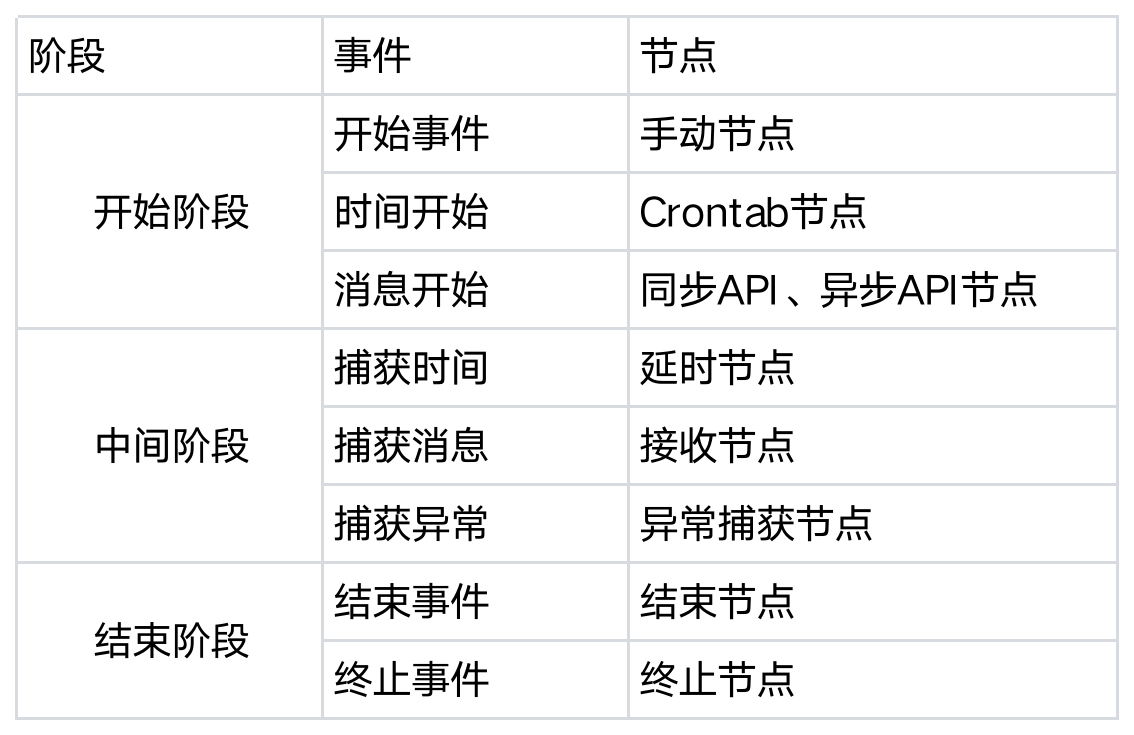
开始阶段:主要用于触发流程实例执行,主要用于系统与外部环境或者流程实例之间进行通信。包括开始事件、时间开始、消息开始三种(触发事件)。
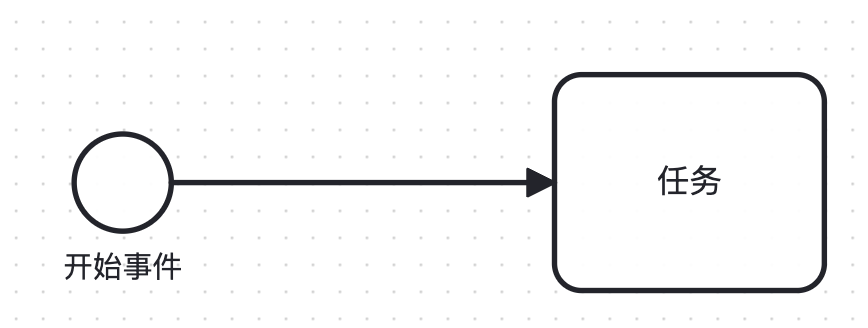
- 开始事件:开始事件是工作流的启动点。所有的流程都从这个点开始。在工作流图中,通常用一个没有入口的圆圈来表示开始事件。当开始事件被触发后,工作流就开始执行。
时间开始:时间开始事件是一种特殊的开始事件,它在预定的时间开始。例如,每天早上9点开始处理邮件,或者每月第一天开始生成报告。当达到预定的时间点,时间开始事件就会被触发,从而启动工作流。
消息开始:消息开始也是一种特殊类型的开始事件。这种事件在接收到特定的消息后开始。例如,当收到一个HTTP请求时,开始处理发起响应流程。
中间阶段:在开始和结束事件之间发生的事件,会影响流程的流转。包括:捕获时间、捕获消息、捕获异常。
捕获时间:捕获时间事件是一种基于时间的中间事件,它在达到特定的时间点时发生。这种事件通常用于对流程中的任务设置截止日期或超时提醒或者设置一个时间延迟。例如,如果一个任务在预定的时间内未完成,可以触发一个捕获时间事件来发送提醒给相关人员。
捕获消息:捕获消息事件是一种基于消息传递的中间事件,它在接收到特定的消息时发生。这种事件通常用于流程实例之间的同步或从外部系统接收数据。例如,前面任务节点中的【接收任务】类型,可以通过调用生成的回调接口触发流程实例继续运行。
捕获异常:捕获异常事件是一种基于异常处理的中间事件,它在发生特定的异常时发生。这种事件通常用于处理流程中的错误或异常情况。例如,当系统出现故障时,可以触发一个捕获异常事件来通知相关人员进行处理。
结束阶段:即结束事件,表明流程执行结束。包括:结束事件和终止事件。
结束事件:结束事件是流程结束的地方。在流程图中,结束事件被表示为一个带有一个粗圆环的圆圈。每个流程可以有一个或多个结束事件,意味着流程可以有一个或多个可能的结束点。结束事件表示流程的正常结束,所有的流程路径都在此结束。
终止事件:终止事件是一种特殊类型的结束事件,它表示流程的非正常结束。在流程图中,终止事件通常用一个带有一个粗圆环和一个"X"的圆圈来表示。当发生某些特殊情况(如错误或异常)需要立即停止整个流程时,可以使用终止事件。终止事件不仅结束当前流程实例,还会结束所有的子流程和调用活动。
# 开始阶段
每个流程都必须有一个开始节点。这个节点的模板类型定义了如何触发当前工作流执行。
常见的开始节点类型有如下几种:
# 手动节点
手动节点主要在测试或者人工操作的场景下使用,该节点没有任何实际的功能。
# Crontab节点
原理
Crontab节点完整JSON结构如下:
{
"instId": "xxx",
"name": "crontab节点",
"type": "Event",
"description": "crontab周期任务",
"template": "crontab",
"positions": [],
"connections": [],
"parameters": {
"expr": {
"label": "expr",
"type": "string",
"value": "*/1 * * * *",
"default": "",
"required": true
},
"allow_repeated": {
"label": "allow_repeated",
"type": "boolean",
"value": true,
"default": true,
"required": true
},
"start_at": {
"label": "start_at",
"type": "string",
"value": "2023-01-01 00:00:00",
"default": "",
"required": false
},
"end_at": {
"label": "end_at",
"type": "string",
"value": "2023-12-01 00:00:00",
"default": "",
"required": false
}
},
"errorHandler": {},
"loopHandler": {},
"timeout": 0,
"isIgnore": false,
"runtimes": []
}
- expr
也就是linux系统上常见的crontab任务。可以设定流程执行的周期,一般精确到分钟级别就够用了。其语法如下:
前五个字段分别表示如下:
[分钟:0-59] [小时:1-23] [日期:1-31] [月份:1-12] [星期:0-6(0 表示周日)]
并且支持一些特殊符号:
*:表示任何时刻,例如下面的表示每天的第0分钟
0 * * * *
,:表示分割,例如下面表示每天的第10、20分钟
10,20 * * * *
-:表示范围,例如下面表示每天的第10-20分钟
10-20 * * * *
/n:表示每个n个时间单位执行一次,例如下面表示每隔5分钟
5/* * * * *
常见的一些用法如下:
# 每分钟执行一次
* * * * *
# 每天的9点0分执行
0 9 * * *
# 每周一9点0分执行
0 9 * * 1
# 每月1号的10:00到11:00每隔1分钟执行一次
0 10-11 1 * *
# 每周的周一到周五9点钟执行
0 9 * * 1-5
- allow_repeated
allow_repeated是重复任务开关。crontab任务是周期性任务。可能存在一种情况,即上一周期的任务未跑完,但是下一周期任务又开始了。
所以这里,一个优化的做法是加一个开关,支持是否重复任务同时执行。
如果启用开关,表示即使上一周期任务未跑完,下一周期也可以继续创建运行;
如果不启用开关,表示上一周期任务未跑完,下一周期就不执行;
- start_at
默认情况下开始时间start_at默认为空。
start_at为空表示满足条件就立即触发运行,否则只有时间大于等于开始时间,且满足设置的条件才触发运行。
- end_at
默认情况下结束时间end_at默认为空。
end_at为空表示没有crontab周期任务运行永不停止,如果设置了结束时间,则到了结束时间以后,该crontab工作流就会被关闭不再运行。
实现
- 单机环境
单机环境下只有一台机器,不存在多个主节点的情况,直接在当前机器管理运行所有crontab任务即可
- 分布式环境
分布式环境下,由于有多台机器,这时候需要保证只有一个主节点机器来进行crontab任务的管理运行。所以这里涉及到分布式系统的主节点选举,常见成熟的算法有raft算法。相应的开源组件有etcd、zookeeper。当然也可以使用redis分布式锁或基于DB自己来实现主节点选举,但是在重要的生产环境,还是建议使用稳定成熟的etcd和zookeeper开源组件。
两种环境下,最终都是在一个节点上管理所有的crontab任务,我在实际的环境中测试,单机上8核16G的机器可以管理百万级别数量的crontab任务,保证运行时间误差在1s以内。所以对于大部分的场景,没必要去实现把crontab任务平均分配到各个节点上,这样不仅开发难度高、维护成本也高。
通过选举主节点来管理所有crontab任务的这种实现方式,足以满足绝大部分的系统需求。
同时主节点选举的机制,也避免了单节点故障问题,增强系统稳定性。
# 同步API节点
原理
同步API完整JSON结构如下:
{
"instId": "xxx",
"name": "同步API",
"type": "Event",
"description": "同步API",
"template": "sync-api",
"positions": [],
"connections": [],
"parameters": {
"login_verification": {
"label": "login_verification",
"type": "string",
"value": "none",
"default": "none",
"required": false
},
"header_token": {
"label": "header_token",
"type": "string",
"value": "",
"default": "",
"required": false
},
"header_user": {
"label": "header_user",
"type": "string",
"value": "",
"default": "",
"required": false
},
"header_password": {
"label": "header_password",
"type": "string",
"value": "",
"default": "",
"required": false
},
"allow_remote_ips": {
"label": "allow_remote_ips",
"type": "string",
"value": "",
"default": "",
"required": false
},
"module": {
"label": "module",
"type": "string",
"value": "",
"default": "",
"required": true
},
"function": {
"label": "function",
"type": "string",
"value": "",
"default": "",
"required": true
},
"method": {
"label": "method",
"type": "string",
"value": "",
"default": "get",
"required": true
}
},
"errorHandler": {},
"loopHandler": {},
"timeout": 0,
"isIgnore": false,
"runtimes": []
}
- login_verification
该字段表示API的认证方式,默认是none,各种认证方式如下:
(1)none:没有认证
(2)token:通过在header请求头带token密钥进行认证,关联的字段是header_token。
(3)password:通过在header请求头带user和password进行认证,关联的字段是header_user和header_password。
- allow_remote_ips
设置允许调用接口的来源IP,可以设置多个ip或ip段。
- method
该字段表示API支持的请求方法,常见的HTTP请求方法包括:POST、GET、PUT等
- module、function
该字段和function字段用来标识接口的路径。一般情况下,module可以用来标识具体的产品或者业务,function可以用来表示模块下的功能。
在调用同步API接口时,引擎就可以通过module+fun来唯一定位到具体的工作流,然后触发创建实例运行。
但是,要注意的是,module和function的组合一定是唯一的,不能跟历史的路径有重复。
实现
如下图所示,是同步API节点的执行原理
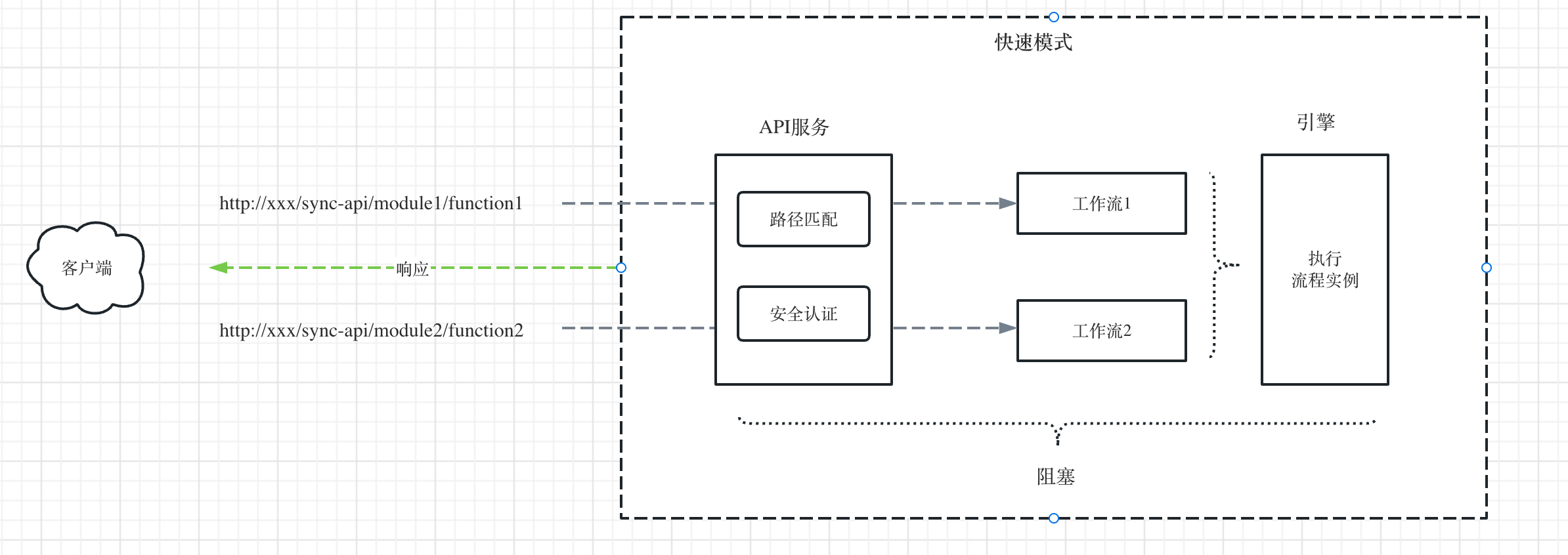
Step1:API服务的路径匹配可以使用开源成熟的API框架实现,通过URL路径匹配获取到module和function信息,这样就可以唯一定位到具体的工作流。
Step2:然后获取该同步API的安全认证信息,校验是否通过安全认证。
Step3:通过安全认证以后,创建流程实例,并调用引擎去执行,这个过程是阻塞的(默认会有个很短的超时时间),直到流程实例运行结束后,读取并返回结果。
可以看到,同步API可以当成API服务来用。
# 异步API节点
原理
异步API跟同步API的区别是,在通过url定位到具体流程,并进行安全认证后。
同步API是创建流程实例并运行,然后阻塞,直到流程实例运行结束,才返回结果。
异步API是创建流程实例,推送到消息队列后,立刻返回执行实例id。
由于异步API的执行机制是非阻塞的,所以他的接口效率非常高,并发量高且接口延时低。
异步API完整JSON结构如下:
{
"instId": "xxx",
"name": "异步API",
"type": "Event",
"description": "异步API",
"template": "async-api",
"positions": [],
"connections": [],
"parameters": {
"login_verification": {
"label": "login_verification",
"type": "string",
"value": "none",
"default": "none",
"required": false
},
"header_token": {
"label": "header_token",
"type": "string",
"value": "",
"default": "",
"required": false
},
"header_user": {
"label": "header_user",
"type": "string",
"value": "",
"default": "",
"required": false
},
"header_password": {
"label": "header_password",
"type": "string",
"value": "",
"default": "",
"required": false
},
"allow_remote_ips": {
"label": "allow_remote_ips",
"type": "string",
"value": "",
"default": "",
"required": false
},
"module": {
"label": "module",
"type": "string",
"value": "",
"default": "",
"required": true
},
"function": {
"label": "function",
"type": "string",
"value": "",
"default": "",
"required": true
},
"method": {
"label": "method",
"type": "string",
"value": "",
"default": "get",
"required": true
}
},
"errorHandler": {},
"loopHandler": {},
"timeout": 0,
"isIgnore": false,
"runtimes": []
}
- login_verification
该字段表示API的认证方式,默认是none,各种认证方式如下:
(1)none:没有认证
(2)token:通过在header请求头带token密钥进行认证,关联的字段是header_token。
(3)password:通过在header请求头带user和password进行认证,关联的字段是header_user和header_password。
- allow_remote_ips
设置允许调用接口的来源IP,可以设置多个ip或ip段。
- method
该字段表示API支持的请求方法,常见的HTTP请求方法包括:POST、GET、PUT等
- module、function
该字段和function字段用来标识接口的路径。一般情况下,module可以用来标识具体的产品或者业务,function可以用来表示模块下的功能。
在调用同步API接口时,引擎就可以通过module+fun来唯一定位到具体的工作流,然后触发创建实例运行。
但是,要注意的是,module和function的组合一定是唯一的,不能跟历史的路径有重复。
实现
如下图所示,是异步API节点的执行原理
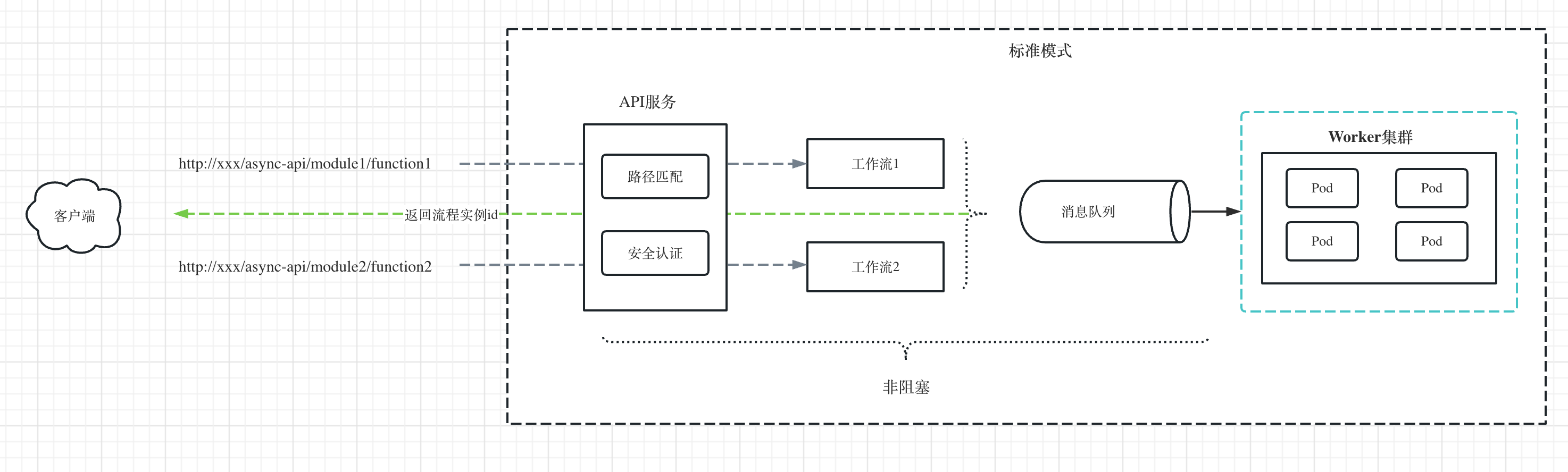
Step1:同上,API服务的路径匹配可以使用开源成熟的API框架实现,通过URL路径匹配获取到module和function信息,这样就可以唯一定位到具体的工作流。
Step2:然后获取该异步API的安全认证信息,校验是否通过安全认证。
Step3:通过安全认证以后,创建流程实例,并推送到消息队列,然后立即返回流程实例id,这个过程是非阻塞的,也是跟同步API的区别所在。
Step4:如果客户端需要获取执行结果,则可以通过上一步返回的流程实例id来查询。
注意:这里在创建流程实例后,并没有落到DB,而是直接推送到消息队列,然后直接返回流程实例id。这样的好处是减少DB的操作,极大提高异步API的性能和并发量。
# 表单节点
实现
表单节点完整JSON结构如下:
{
"instId": "xxx",
"name": "表单",
"type": "Event",
"description": "表单",
"template": "form",
"positions": [],
"connections": [],
"parameters": {
"members": {
"label": "members",
"type": "array",
"value": [],
"default": [],
"required": false
},
"require_login": {
"label": "require_login",
"type": "boolean",
"value": false,
"default": false,
"required": false
}
},
"errorHandler": {},
"loopHandler": {},
"timeout": 0,
"isIgnore": false,
"runtimes": []
}
- members
该字段限制了哪些平台成员可以提交表单,如果不填写,则认为所有人都可以填写表单
- require_login
该字段为true,表示需要用户登录平台获取登录态才能访问表单链接;
该字段为false,表示任意的游客(未注册用户)或平台用户都可以访问表单链接。
表单节点需要先设计一个前端的表单并生成一个唯一的URL地址,这个地址跟后端的工作流进行关联。
http://xxxx/form/[workflow_id]/[appinst_id]
只要表单提交后就会把提交的参数一同带上,触发创建工作流实例执行,然后由后端的worker集群来运行。
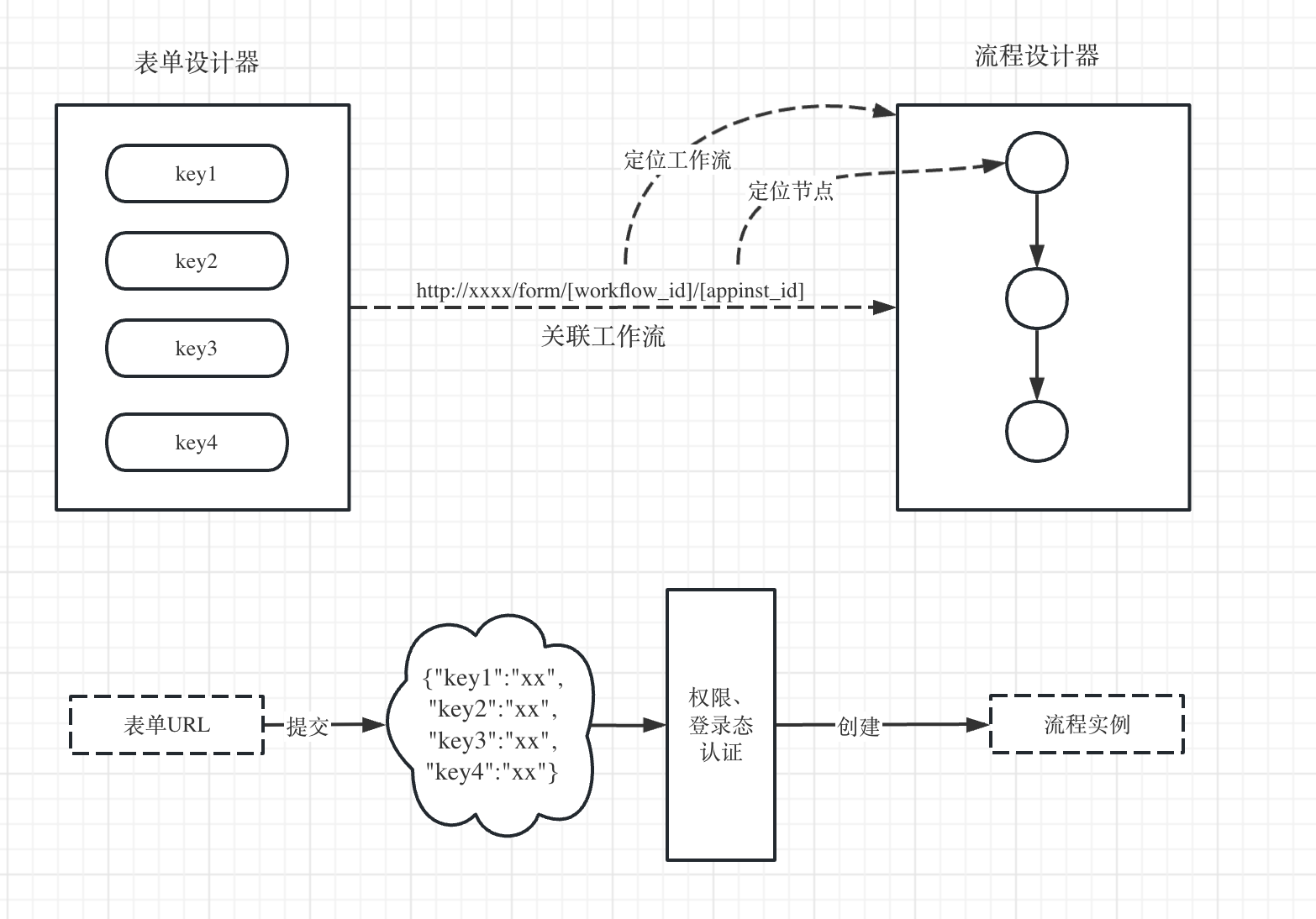
实现
表单的可视化设计又是另一个大的系统,这里不展开讲。主要的功能跟流程设计器类似,需要有一个表单设计语言,即设计DSL语言,业界常见的做法是用JSON来描述表单。在保存表单的时候生成一个唯一的URL地址,并关联后端具体的工作流。
用户提交表单时,就得到表单的key value JSON数据,这个JSON数据会以POST方法的形式作为参数传递给后端的工作流实例。
# 中间阶段
# 延时节点(捕获时间)
原理
延时节点完整JSON结构如下:
{
"instId": "xxx",
"name": "延时任务",
"type": "Event",
"description": "延时任务",
"template": "interval",
"positions": [],
"connections": [],
"parameters": {
"interval": {
"label": "interval",
"type": "integer",
"value": 60,
"default": 60,
"required": true
},
},
"errorHandler": {},
"loopHandler": {},
"timeout": 0,
"isIgnore": false,
"runtimes": []
}
延时任务即指定在未来某个时刻触发执行,跟前面crontab的周期性任务不同的是,它是一次性的任务。系统在到达指定时间后就会触发创建工作流实例运行。
- interval
等待interval秒以后唤醒延时节点继续运行。
实现
延时任务的特点是时间戳由小到大排序,只要有任务的时间戳小于等于当前时间戳,就立即创建工作流实例运行。
所以这里需要非常频繁地访问这个延时任务队列,并且这个延时任务队列要一直保持有序。这里可以基于Redis的zset有序集合这个数据结构来实现。
- ZSET有序集合命令
zset有序集合不允许重复的成员出现,且每个成员都会关联一个double类型的分数,这个分数可以重复。redis通过这个分数为集合中的成员从小到大进行排序。
zset集合是通过哈希表实现,所以添加、删除、查找的复杂度都是O(1)。
zset集合支持最大的成员数是2^32-1(即每个集合可存储40多亿的成员数据),所以对于大部分业务是够用的。
下表是在实现延时任务涉及到的zset命令:
| 命令 | 描述 |
|---|---|
| ZADD key score member | 向有序集合添加成员 |
| ZREM key member | 移除有序集合中的成员 |
| ZCOUNT key min max | 计算在有序集合中指定区间分数的成员数 |
| ZREVRANGEBYSCORE key max min [WITHSCORES] | 返回有序集中指定分数区间内的成员,分数从高到低排序 |
key命名为:delay_execution_queue
member命名格式为:节点实例uid
score表示目标时间戳(单位:秒)
第一步:创建并初始化节点实例,获得uid,存储到数据库
uid
第二步:通过ZADD命令添加到zset有序集合:
ZADD delay_execution_queue 时间戳 uid
第三步:通过ZCOUNT命令每秒轮询获取已达到当前时间戳的任务数量,直到返回个数大于0,执行下一步
ZCOUNT delay_execution_queue 当前时间戳 -inf
第四步:获取成员列表并删除zset中的成员
这里获取成员和删除成员是两个动作,不是原子性的,需要使用lua脚本在redis操作来保证两个动作的原子性。即要么都成功,要么都失败,避免出现一个动作成功,另一个动作失败的情况。
lua脚本如下,其中key是delay_execution_queue,max是当前时间戳。
local key = tostring(KEYS[1])
local max = ARGV[1]
-- 先获取当前时间戳以前的uid成员
local arr = redis.call('ZREVRANGEBYSCORE', key, max, '-inf', 'LIMIT', 0, 1)
local member = -1
for i, v in pairs(arr) do
redis.call('ZREM', key, v)
member = v
end
return member
# 接收节点(捕获消息)
原理
接收节点完整JSON结构如下:
{
"instId": "xxx",
"name": "接收任务",
"type": "Event",
"description": "接收任务",
"template": "callback",
"positions": [],
"connections": [],
"parameters": {
"timeout_branch": {
"label": "timeout_branch",
"type": "string",
"value": "",
"default": "",
"required": false
},
"timeout":{
"label": "timeout",
"type": "integer",
"value": 0,
"default": 0,
"required": false
}
},
"errorHandler": {},
"loopHandler": {},
"timeout": 0,
"isIgnore": false,
"runtimes": []
}
- timeout
等待接收信号的超时时间,默认为0表示没有限制,如果设置了超时时间,事件信号在指定的时间内没有到达,则会立刻停止响应或者执行指定的timeout_branch分支的节点任务。
注意,超时以后,后续的事件信号即使到达了也不会再响应。
- timeout_branch
如果前面设置了timeout属性,则在超过指定时间后,会执行该分支的节点任务。如果没有设置,则不做任何响应。
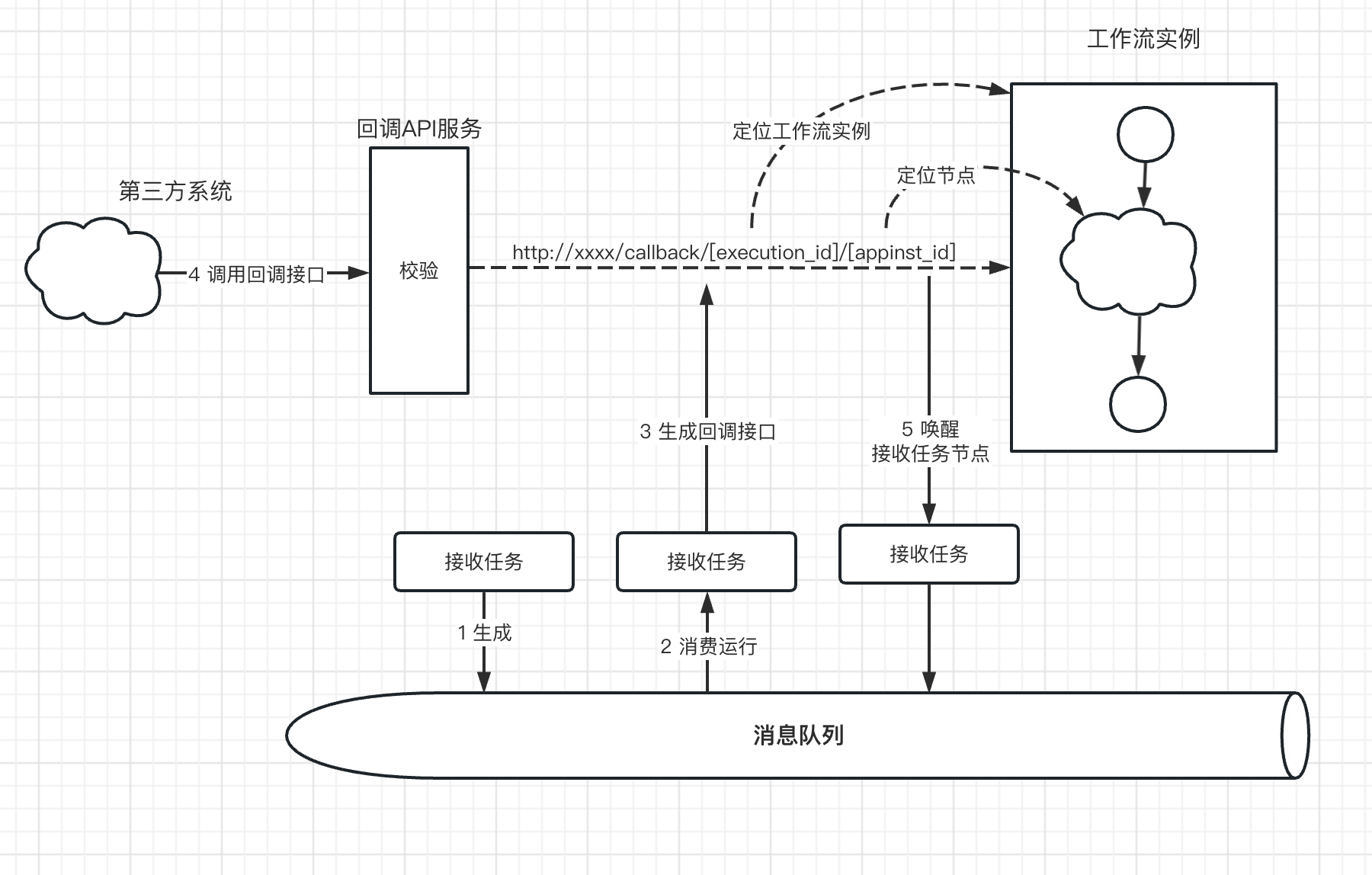
接收节点会生成一个唯一的回调地址,用于给外部第三方系统进行调用和数据推送。
通过工作流实例ID和节点ID就可以定位到流程中具体的节点位置。
实现
工作流实例在运行到接收节点时,会生成如下格式的回调地址:
http://xxxx/callback/[execution_id]/[appinst_id]
其中execution_id表示当前的工作流实例ID,appinst_id表示当前节点的实例ID。
调用回调接口传递的参数,会作为接收节点的输出结果。
其完整执行过程如下图所示:
Step1:接受任务被上一个节点推送到消息队列,等待执行
Step2:接收节点被worker节点消费执行,此时是接收任务第一次执行
Step3:这时候生成一个回调地址工第三方系统调用。
Step4:第三方系统拿到这个回调接口后,通过POST请求带上参数推送数据给引擎。
通过回到URL,引擎获得execution_id和appinst_id,可以定位判断是否存在接收任务
Step5:当上一步判定回调接口有效后,就会唤醒接收节点,即把接收节点再次推送到消息队列执行
Step6:此时,接受节点被消费执行,这次是第二次执行,直接返回第三方系统POST的数据作为输出结果。
# 全局异常节点(捕获异常)
一个流程里面拖入一个全局异常节点,只要流程中有任意一个节点抛出异常并且自己没有处理,则最终就会被这个全局异常节点捕获。
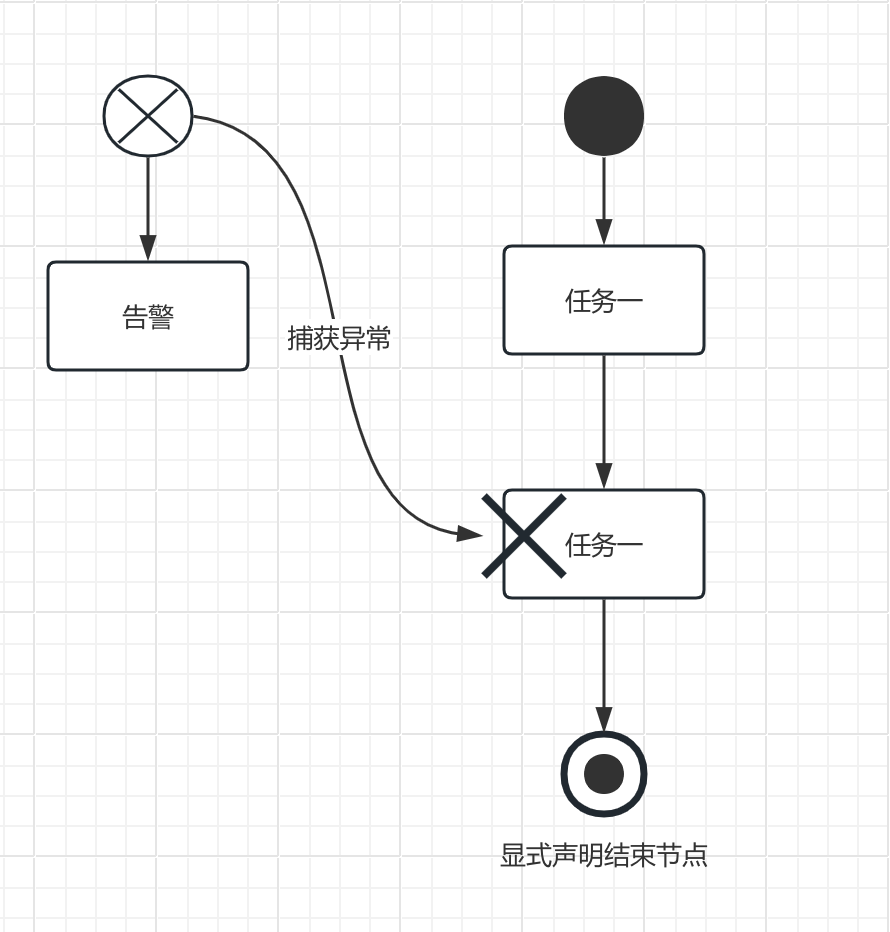
这里,我们介绍的是全局异常的捕获。如果想节点自己捕获和处理异常,则可以给每个节点增加多一个错误处理配置(errorHandler),这个配置可以配置具体处理的方法。
{
"operation": "retry/ignore/catch/throw",
"retry": {
"count": 0,
"period": 1
},
"catch": {
"branch": "xxxx"
}
}
retry表示错误重试,可以设置重试的次数和间隔周期。
ignore表示发生错误直接忽略不管,继续往下执行。
catch表示捕获并处理这个异常,这是可以设置响应处理异常的分支节点。
throw表示抛出这个异常,给全局异常节点捕获处理。
这个的原理类似python里面的try...catch异常捕获的思路一样。
例如下面的run_node方法对应流程中的一个个节点任务,其中try是每个节点的具体业务功能,而except则是这个节点自己实现部分异常的捕获处理。如果except出现了一些节点自己没有捕获到的异常,则会向上一层抛出这个异常,最终被这个流程的全局except捕获到。
def run_node():
try:
# Some code that may raise an exception
x = 10 / 0
except ZeroDivisionError as e:
# Handling specific exception
print("Division by zero error!")
def __main__():
try:
run_node()
except Exception as e:
print("Global exception catch")
# 结束阶段
# 终止节点
执行结束节点会强制终止工作流实例停止,运行中的其他节点实例也会被强制终止。
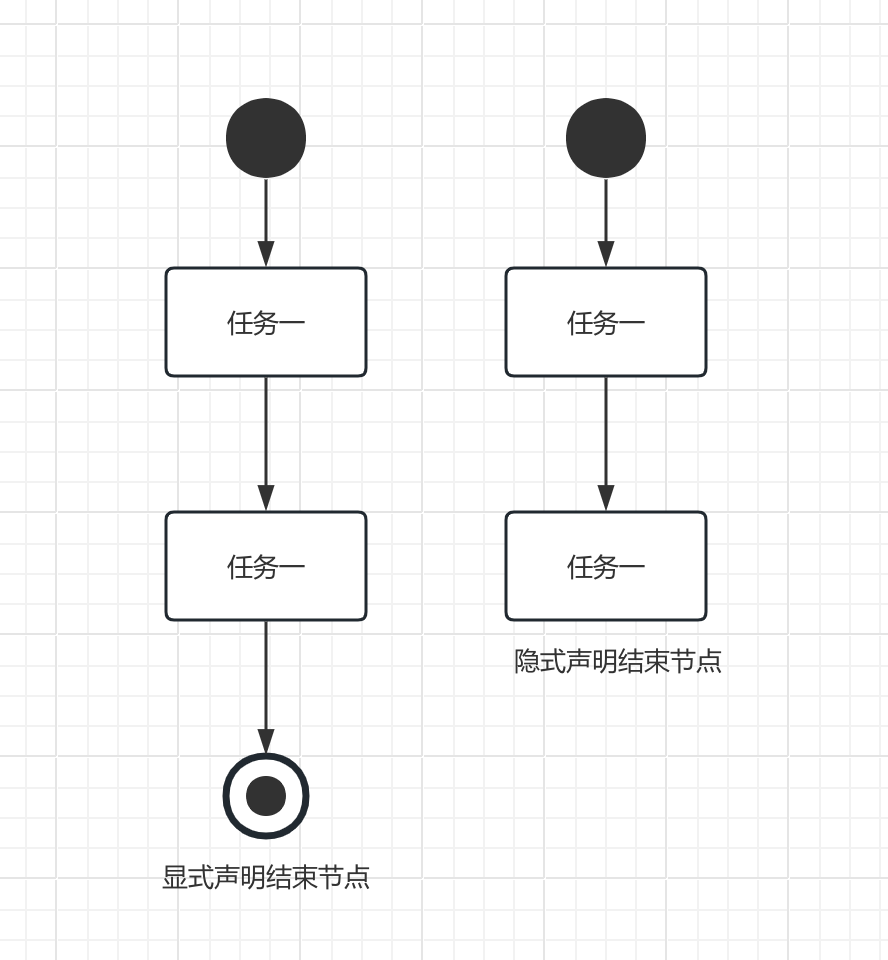
# 结束节点
在一个流程中,结束节点分为两类。如下图所示,一种是显式声明结束节点,一种是隐式声明结束节点。
这里我们说的是显示声明结束节点,主要是明显地在流程图上表示出来,并没有特别多的意义。