分布式系统中,为了保障高可用性,通常需要采取限流措施,以防止系统因过载而崩溃或性能下降。
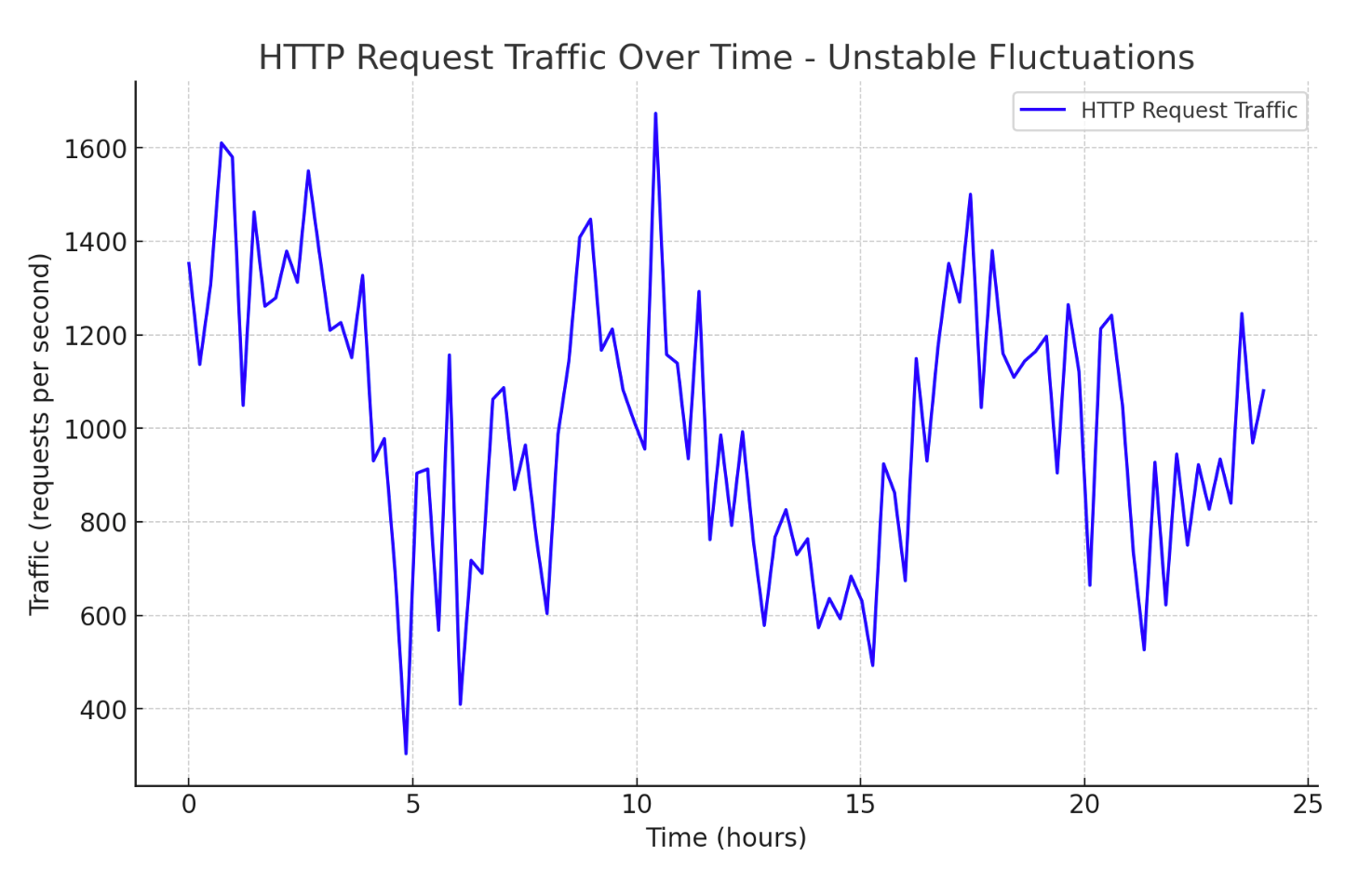
在实际业务中,如果我们的服务器不上限流功能,会发现http的流量请求体波动很大,例如下面的某个系统。图中的尖峰点很容易超出系统的最大负载,直接导致系统出现崩溃不可用的问题出现。
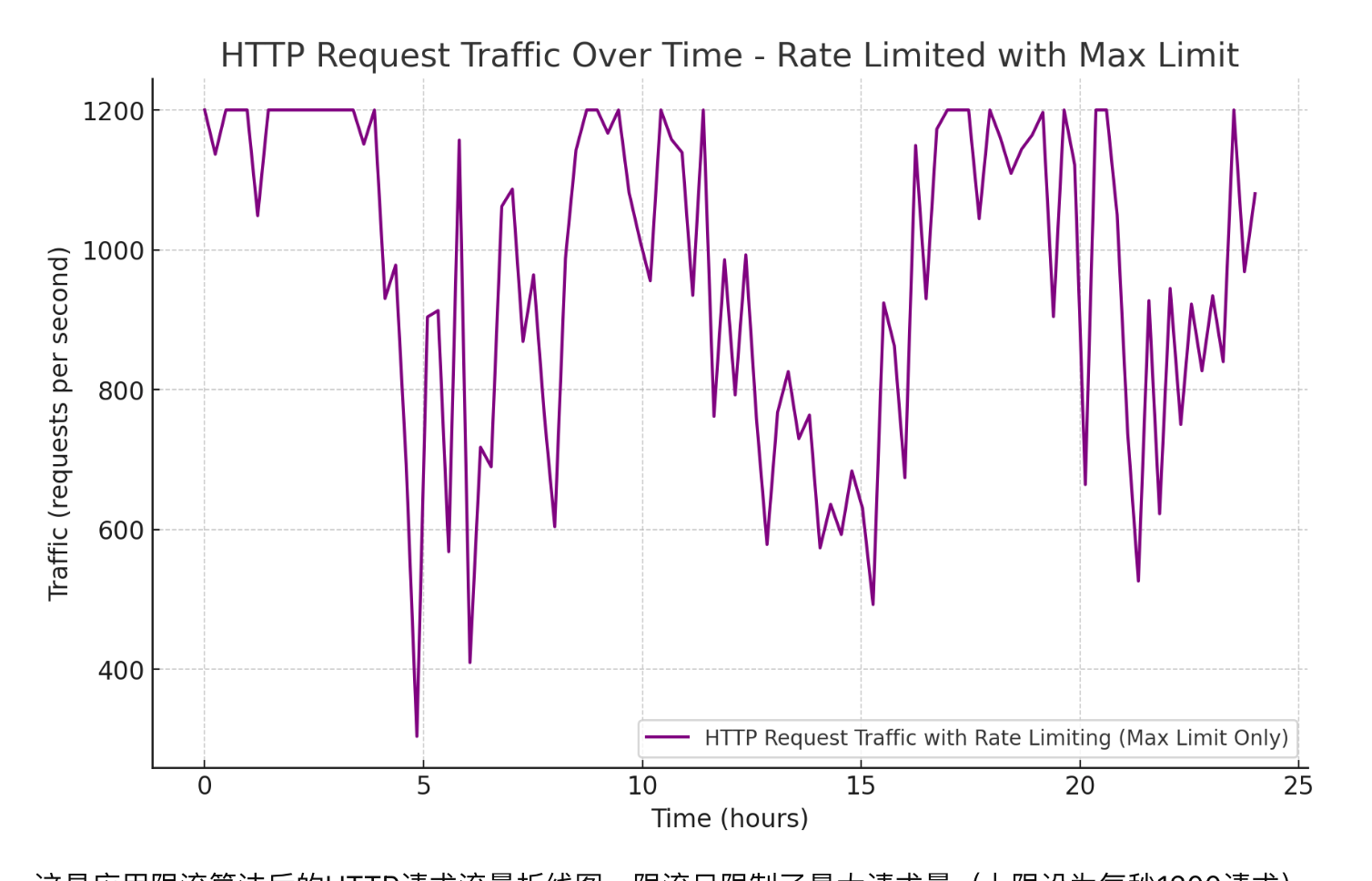
而如果我们采用限流算法之后,可以讲请求流量控制在一定范围内,不超过系统的最大负载,例如每秒1200以下:
根据限流的范围,可以分为:
单机限流
主要应用于单个服务器或应用实例。限流是在一个独立的机器上完成的,适用于较小规模的应用,不能全局限流。
分布式限流
需要在多个服务器或节点上协同工作,用于处理大规模的流量,可以进行全局限流。
在流程引擎中,由于我们生成了同步和异步API,所以这里需要对API的调用进行控制和限流,避免一些恶意的或高并发的调用导致整个系统的异常不可用。
以下是一些常见的限流方法及其实现方式:
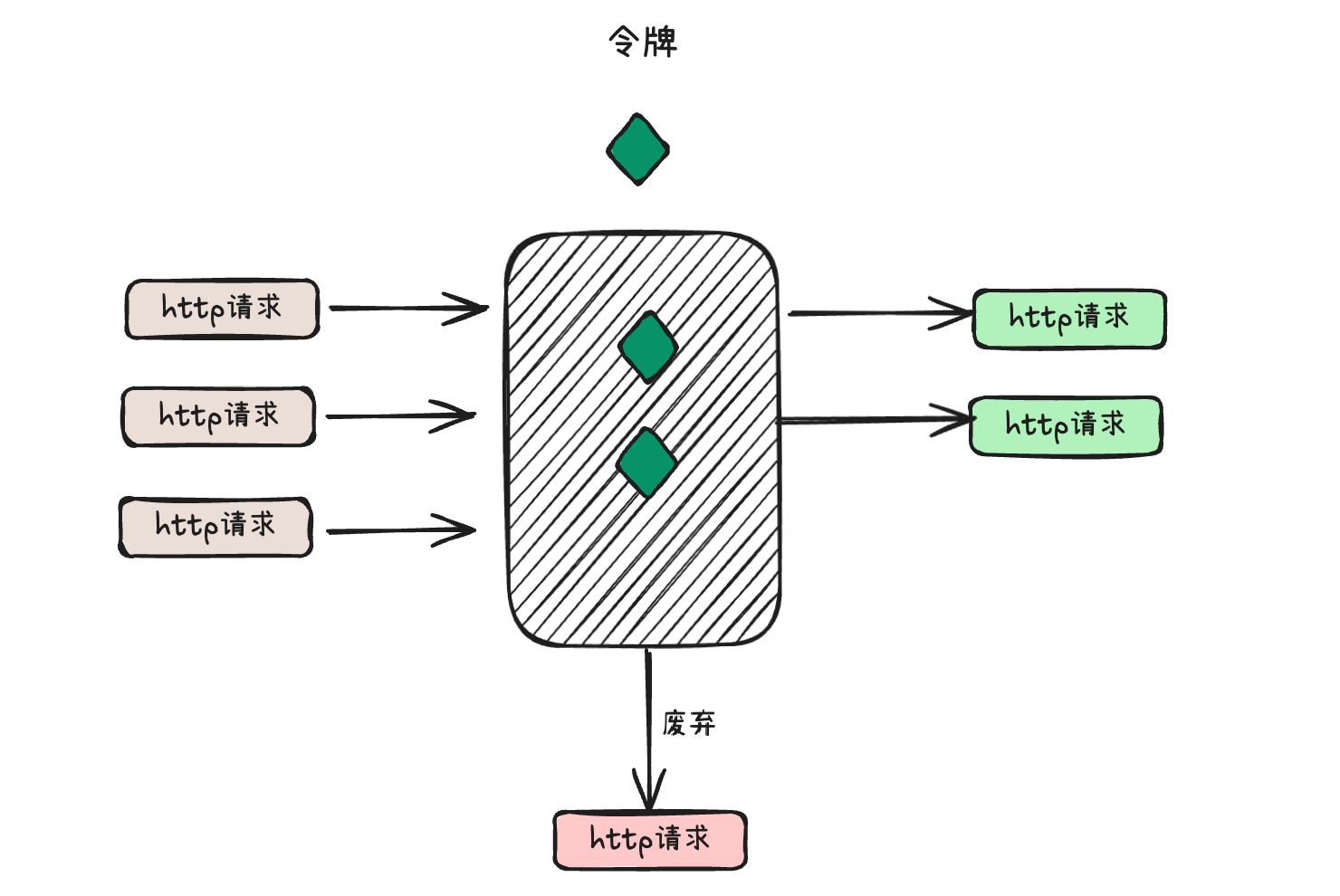
# 令牌桶算法
令牌桶算法是一种用于控制访问速率的算法,常用于限制请求的频率。它通过维护一个令牌桶来实现,其中令牌以固定的速率被添加到桶中。系统中的请求需要获取令牌才能被处理,而获取令牌的速率由算法定义。
以下是令牌桶算法的基本工作原理:
- 令牌生成: 系统以固定的速率生成令牌,将其放入令牌桶中。生成的速率决定了系统允许的最大处理请求速率。
- 令牌消耗: 当一个请求到达时,需要从令牌桶中获取一个令牌。如果令牌桶中没有足够的令牌,请求将被暂时阻塞或拒绝。否则,请求将被处理,并且相应数量的令牌将从桶中消耗。
- 限速控制: 通过调整令牌生成的速率,可以灵活地控制系统的处理速率。如果系统需要处理更多请求,可以增加令牌生成的速率;如果需要限制处理速率,可以降低令牌生成的速率。
- 平滑处理: 令牌桶算法具有平滑处理的特性,即请求的处理速率可以在一定程度上平滑变化,而不是出现突然的流量峰值。
# 单机限流实现
我们模拟在单机机器上进行限流,如下是具体的代码实现:
package main
import (
"fmt"
"time"
)
type TokenBucket struct {
tokens chan struct{}
fillInterval time.Duration
maxTokens int
tokensPerFill int
}
func NewTokenBucket(fillInterval time.Duration, maxTokens int) *TokenBucket {
tb := &TokenBucket{
tokens: make(chan struct{}, maxTokens),
fillInterval: fillInterval,
maxTokens: maxTokens,
tokensPerFill: 1,
}
go tb.fillToken()
return tb
}
func (tb *TokenBucket) fillToken() {
for {
time.Sleep(tb.fillInterval)
select {
case tb.tokens <- struct{}{}:
default:
}
}
}
func (tb *TokenBucket) getToken() bool {
select {
case <-tb.tokens:
return true
default:
return false
}
}
func main() {
fillInterval := time.Millisecond * 500
maxTokens := 3
tb := NewTokenBucket(fillInterval, maxTokens)
for i := 0; i < 5; i++ {
if tb.getToken() {
fmt.Println("Processing request ", i+1)
} else {
fmt.Println("Dropping request ", i+1)
}
time.Sleep(time.Millisecond * 200)
}
}
在这个示例中,TokenBucket 结构体包含一个用于存放令牌的 channel(tokens),填充间隔时间(fillInterval),最大令牌数(maxTokens),以及每次填充的令牌数(tokensPerFill)。NewTokenBucket 函数用于初始化令牌桶,并启动一个 goroutine 来定期填充令牌。
getToken 函数用于尝试获取一个令牌,如果成功获取则返回 true,否则返回 false。在 main 函数中,通过循环模拟了多个请求,每次请求前都会尝试获取一个令牌,如果获取成功则处理请求,否则丢弃请求。
执行后输出结果如下:
go run token_bucket.go
Dropping request 1
Dropping request 2
Dropping request 3
Processing request 4
Dropping request 5
# 分布式限流实现
在分布式环境下,要实现全局性的限流,需要要保证数据操作的原子性,否则会造成数据竞争的问题。所以这里需要基于Lua脚本在Redis中执行原子操作。
下面是实现令牌桶算法的逻辑:
package main
import (
"context"
"fmt"
"log"
"time"
"github.com/go-redis/redis/v8"
)
var ctx = context.Background()
const luaScript = `
local key = KEYS[1] -- 令牌桶在Redis中的键
local capacity = tonumber(ARGV[1]) -- 令牌桶容量
local rate = tonumber(ARGV[2]) -- 令牌生成速率
local currentTokens = tonumber(redis.call('get', key) or 0) -- 当前令牌数量
local currentTimestamp = tonumber(ARGV[3]) -- 当前时间戳
local lastTimestamp = tonumber(redis.call('get', key .. ':lastTimestamp') or 0) -- 上次更新时间戳
local elapsedTime = currentTimestamp - lastTimestamp -- 两次更新之间的时间差
local newTokens = elapsedTime * rate -- 计算在时间差内生成的新令牌数量
-- 如果新令牌数量大于1,更新令牌桶状态
if newTokens > 1 then
currentTokens = math.min(capacity, currentTokens + newTokens)
redis.call('set', key, currentTokens)
redis.call('set', key .. ':lastTimestamp', currentTimestamp)
end
-- 如果当前令牌数量大于等于1,消耗一个令牌并返回允许
if currentTokens >= 1 then
redis.call('decrby', key, 1)
return 1
else
return 0 -- 令牌不足,返回拒绝
end
`
func main() {
// 初始化Redis客户端
client := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "", // 如果有密码,填写密码
DB: 0,
})
// 设置初始令牌桶容量和速率
key := "myTokenBucket"
capacity := 10
rate := 0.5 // 每秒生成0.5个令牌
// 初始化令牌桶
client.Set(ctx, key, capacity, 0)
client.Set(ctx, key+":lastTimestamp", time.Now().Unix(), 0)
// 模拟请求
for i := 0; i < 15; i++ {
allowed, err := acquireToken(client, key, capacity, rate)
if err != nil {
log.Fatal(err)
}
if allowed {
fmt.Println("Request", i+1, "allowed")
} else {
fmt.Println("Request", i+1, "rejected")
}
time.Sleep(200 * time.Millisecond)
}
}
func acquireToken(client *redis.Client, key string, capacity int, rate float64) (bool, error) {
currentTimestamp := time.Now().Unix()
result, err := client.Eval(ctx, luaScript, []string{key}, capacity, rate, currentTimestamp).Result()
if err != nil {
return false, err
}
return result == int64(1), nil
}
这个例子中,令牌桶的容量是10,速率是每秒生成0.5个令牌。在模拟的15次请求中,根据令牌桶算法,前10次请求应该被允许,而后面的5次请求应该被拒绝。你可以根据实际需求调整令牌桶的容量和速率。
通过执行,得到如下的输出结果:
go run token_bucket_v2.go
Request 1 allowed
Request 2 allowed
Request 3 allowed
Request 4 allowed
Request 5 allowed
Request 6 allowed
Request 7 allowed
Request 8 allowed
Request 9 allowed
Request 10 allowed
Request 11 rejected
Request 12 rejected
# 漏桶算法
漏桶算法(Leaky Bucket Algorithm)是一种用于流量控制和限流的算法。它通过以固定的速率从漏桶中以恒定速率漏水的方式来控制输入流量。如果流量过大,超出漏桶容量,多余的流量将被丢弃或缓存。跟令牌桶算法相反的是,漏洞算法是控制“出令牌”的速率来实现限流。这个请求就像水龙头,我不管你水龙头的流量多少,但是我总是保证漏桶滴水的速度的恒定的。
可以看出漏桶算法能强行限制数据的传输速率。
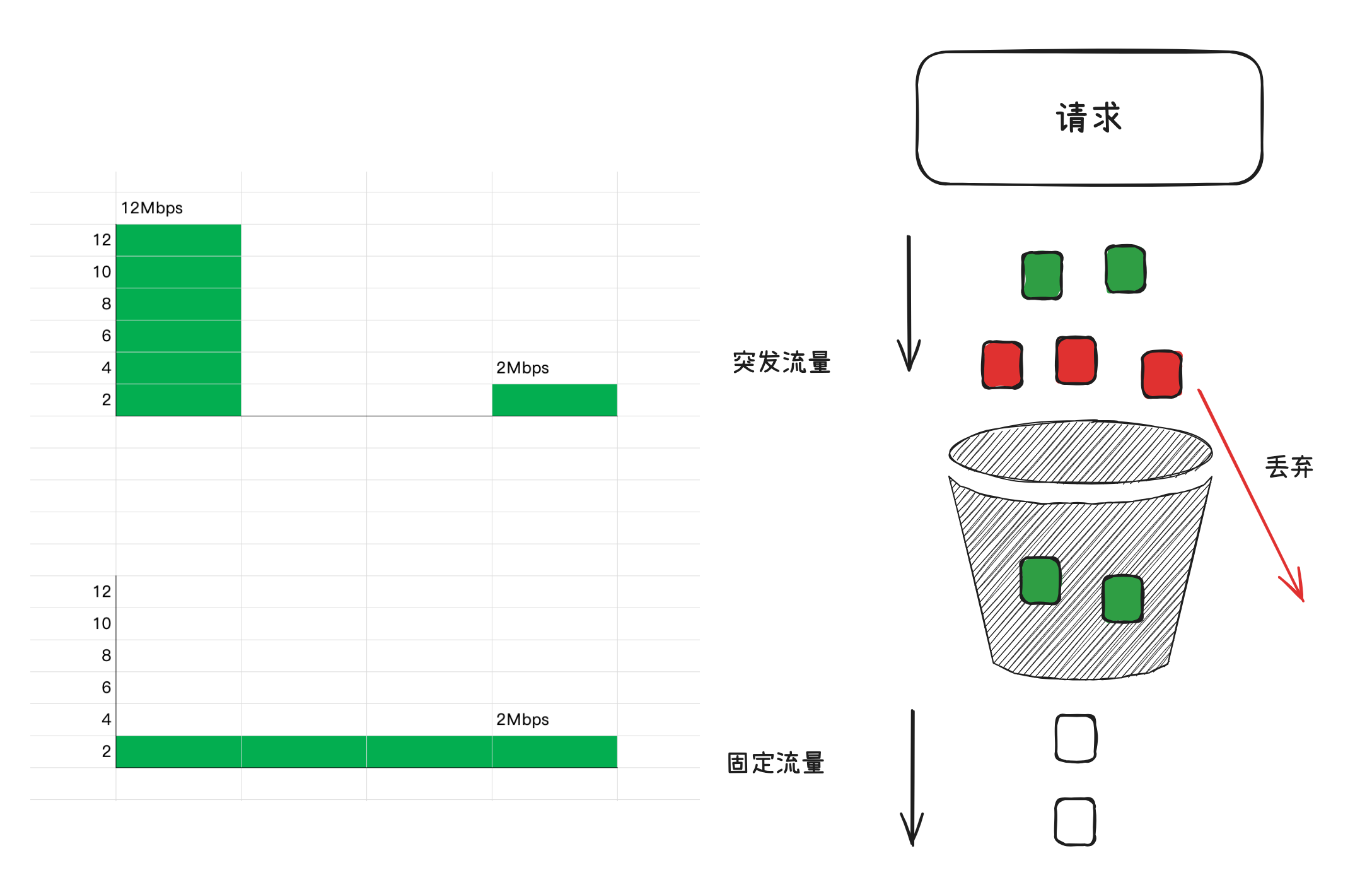
# 单机限流实现
这个Go程序实现了一个基于漏桶算法的流量控制,主要用于API接口的请求限流,防止服务器被过量的请求压垮。它限制了每个客户端IP每秒钟只能发送特定数量的请求。
在这个程序中,每个客户端IP都有一个对应的MutexLimiter对象,这个对象记录了上一次请求的时间,每个请求的间隔时间,以及下一次请求需要等待的时间。当一个新的请求到来时,程序会根据这个IP地址获取对应的MutexLimiter对象,然后通过MutexLimiter的Take()方法来计算这个请求是否可以立即处理,还是需要等待一段时间。
在Take()方法中,程序首先会获取当前的时间,然后计算距离上一次请求的时间间隔,并与每个请求的间隔时间进行比较,如果当前时间距离上一次请求的时间间隔小于每个请求的间隔时间,那么程序会让当前的请求等待一段时间,直到达到每个请求的间隔时间,然后再处理这个请求。如果当前时间距离上一次请求的时间间隔大于或等于每个请求的间隔时间,那么程序会立即处理这个请求。
在main函数中,程序初始化了一个全局的sync.Map对象,用来存储每个客户端IP对应的MutexLimiter对象。然后,程序创建了一个Gin引擎,并使用NewLimiter(10)中间件来限制每秒钟只能处理10个请求。最后,程序启动了Gin引擎,开始监听8888端口的HTTP请求。
package main
import (
"fmt"
"github.com/benbjohnson/clock"
"github.com/gin-gonic/gin"
"net/http"
"sync"
"time"
)
// 定义全局限流器对象
var limiters *sync.Map
func NewLimiter(rps int) gin.HandlerFunc {
return func(c *gin.Context) {
// key可以针对ip或者用户来进行限速,如下是对每个来源的IP限制最大的并发速率
key := c.ClientIP()
// 获取限速器
l, _ := limiters.LoadOrStore(key, NewMutexBased(rps))
now := l.(*MutexLimiter).Take()
fmt.Printf("now: %s, key:%s\n", now, key)
c.Next()
}
}
type MutexLimiter struct {
sync.Mutex
last time.Time
sleepFor time.Duration
perRequest time.Duration
per time.Duration // 每个请求的间隔
clock clock.Clock
}
func NewMutexBased(rate int) *MutexLimiter {
perRequest := time.Second / time.Duration(rate) // 每个请求的间隔
l := &MutexLimiter{
perRequest: perRequest,
clock: clock.New(),
}
return l
}
func (t *MutexLimiter) Take() time.Time {
t.Lock()
defer t.Unlock()
now := t.clock.Now()
// 第一次请求
if t.last.IsZero() {
t.last = now
return t.last
}
// 对比上一次的请求时间和请求间隔,计算下一次许可发放的等待时间
t.sleepFor += t.perRequest - now.Sub(t.last)
if t.sleepFor > 0 {
t.clock.Sleep(t.sleepFor)
t.last = now.Add(t.sleepFor)
t.sleepFor = 0
} else {
// 有可能上一次请求的时间比较早,大于请求间隔
t.last = now
}
return t.last
}
func main() {
limiters = &sync.Map{}
e := gin.Default()
e.Use(NewLimiter(10)) // 每秒处理10个并发请求
e.GET("ping", func(c *gin.Context) {
c.String(http.StatusOK, "pong")
})
e.Run(":8888")
}
我们通过ab工具压测,虽然设置的并发请求是100,总共100个请求,但是通过限速器后每秒就只处理10个并发请求,如下图QPS为10.10。
>> ab -n 100 -c 100 http://localhost:8888/ping
This is ApacheBench, Version 2.3 <$Revision: 1903618 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient).....done
Server Software:
Server Hostname: localhost
Server Port: 8888
Document Path: /ping
Document Length: 4 bytes
Concurrency Level: 100
Time taken for tests: 9.902 seconds
Complete requests: 100
Failed requests: 0
Total transferred: 12000 bytes
HTML transferred: 400 bytes
Requests per second: 10.10 [#/sec] (mean)
Time per request: 9902.379 [ms] (mean)
Time per request: 99.024 [ms] (mean, across all concurrent requests)
Transfer rate: 1.18 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 2 1.0 2 4
Processing: 5 4946 2900.7 4996 9896
Waiting: 1 4946 2900.8 4996 9896
Total: 6 4949 2899.9 4999 9897
Percentage of the requests served within a certain time (ms)
50% 4999
66% 6598
75% 7498
80% 7997
90% 8997
95% 9497
98% 9797
99% 9897
100% 9897 (longest request)
# 分布式限流实现
如下是基于Redis和Golang实现的分布式限流器。
package main
import (
"context"
"fmt"
"log"
"net/http"
"time"
"github.com/gin-gonic/gin"
"github.com/go-redis/redis/v8"
)
var rdb *redis.Client
var ctx = context.Background()
const (
QPS_LIMIT = 10 // 每秒请求限制
LEAK_INTERVAL = 1 // 漏桶的出水间隔,单位为秒
REQUEST_BUCKET = "leaky_bucket:" // 漏桶前缀
)
func initRedis() {
rdb = redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "test:test", // Redis密码
DB: 0, // Redis数据库
})
_, err := rdb.Ping(ctx).Result()
if err != nil {
log.Fatalf("无法连接到Redis: %v", err)
}
fmt.Println("Redis连接成功")
}
func main() {
initRedis()
r := gin.Default()
// 定义限流中间件
r.Use(rateLimiterMiddleware())
// 路由和处理函数
r.GET("/ping", func(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{
"message": "pong",
})
})
// 启动服务
r.Run(":8080")
}
// Lua脚本,实现漏桶算法的原子操作,确保了多个请求并发执行时数据不会出现竞态条件。
var leakyBucketScript = redis.NewScript(`
local bucket_key = KEYS[1]
local limit = tonumber(ARGV[1])
local interval = tonumber(ARGV[2])
-- 获取当前时间戳和请求计数
local count = tonumber(redis.call("HGET", bucket_key, "count") or "0")
local last_time = tonumber(redis.call("HGET", bucket_key, "last_time") or "0")
-- 当前时间
local now = tonumber(ARGV[3])
-- 计算衰减量
local elapsed = now - last_time
-- 这行代码计算了“漏水”的总数 leaked
local leaked = math.floor(elapsed * limit / interval)
count = math.max(0, count - leaked)
-- 更新计数器和时间戳
if count < limit then
count = count + 1
redis.call("HMSET", bucket_key, "count", count, "last_time", now)
return 1 -- 允许请求
else
return 0 -- 拒绝请求
end
`)
func rateLimiterMiddleware() gin.HandlerFunc {
return func(c *gin.Context) {
ip := c.ClientIP()
bucketKey := REQUEST_BUCKET + ip
now := time.Now().Unix()
// 执行 Lua 脚本
allowed, err := leakyBucketScript.Run(ctx, rdb, []string{bucketKey}, QPS_LIMIT, LEAK_INTERVAL, now).Int()
if err != nil {
log.Printf("Redis错误: %v", err)
c.JSON(http.StatusInternalServerError, gin.H{"error": "服务器错误"})
c.Abort()
return
}
if allowed == 1 {
// 允许请求
c.Next()
} else {
// 拒绝请求并返回 429 状态码
c.JSON(http.StatusTooManyRequests, gin.H{"error": "请求过多"})
c.Abort()
}
}
}
代码解释
- 计数衰减:当有新的请求到达时,先计算自上次请求以来的时间差,然后按比例减少计数,模拟漏桶的出水。
- 计数更新:如果新的计数值小于设定的限额
QPS_LIMIT,则允许请求并增加计数值,同时更新 Redis 中的时间戳;否则,拒绝请求。 - 使用 HMSET 存储计数和时间戳:
HMSET用于存储和更新 IP 的计数和时间戳。
这样实现后,可以更准确地控制每秒的请求速率。
关键变量解释
-- elapsed * QPS_LIMIT:表示在 elapsed 秒内,按 QPS 限制,理论上可以“漏掉”的总量。
-- 除以 LEAK_INTERVAL.Seconds() 的值(1 秒),保持单位一致,得到实际应漏掉的“水滴”量
local leaked = math.floor(elapsed * limit / interval)
elapsed:当前时间和上次请求时间之间的时间差,单位是秒。这表示自上次请求到当前请求之间经过了多少秒。QPS_LIMIT:每秒的请求限制,即我们允许的最大 QPS。在这里我们设定了QPS_LIMIT = 10。LEAK_INTERVAL.Seconds():漏桶的“漏水”间隔时间(LEAK_INTERVAL)转为秒单位,假设是 1 秒。
计算过程
假设 QPS_LIMIT = 10,LEAK_INTERVAL = 1 秒:
elapsed * QPS_LIMIT:表示在elapsed秒内,按 QPS 限制,理论上可以“漏掉”的总量。- 除以
LEAK_INTERVAL.Seconds()的值(1 秒),保持单位一致,得到实际应漏掉的“水滴”量。
因此,这行代码计算了“漏水”的总数 leaked。随着时间推移,如果没有新的请求,计数值 count 将逐步减少,直到归零。
测试效果
如下我们通过ab命令模拟压测限流的情况,一共100个请求100个并发。可以看到所有请求在1秒内完成,而只有10个请求是成功的,生效的90个是492请求过多的错误状态码。
>> ab -n 100 -c 100 http://localhost:8080/ping
This is ApacheBench, Version 2.3 <$Revision: 1903618 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient).....done
Server Software:
Server Hostname: localhost
Server Port: 8080
Document Path: /ping
Document Length: 18 bytes
Concurrency Level: 100
Time taken for tests: 0.030 seconds
Complete requests: 100
Failed requests: 90
(Connect: 0, Receive: 0, Length: 90, Exceptions: 0)
Non-2xx responses: 90
Total transferred: 15990 bytes
HTML transferred: 2340 bytes
Requests per second: 3342.47 [#/sec] (mean)
Time per request: 29.918 [ms] (mean)
Time per request: 0.299 [ms] (mean, across all concurrent requests)
Transfer rate: 521.93 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 1 3 0.4 3 4
Processing: 2 13 2.9 13 16
Waiting: 2 12 2.9 13 16
Total: 5 16 2.8 16 19
Percentage of the requests served within a certain time (ms)
50% 16
66% 17
75% 17
80% 17
90% 18
95% 18
98% 19
99% 19
100% 19 (longest request)