# 缓存的分类
按层次划分,缓存分为:操作系统上的缓存、应用程序上的缓存以及分布式环境上的缓存,前两者是单机机器上的,第三个是在分布式集群的环境。规模由小到大,由简单到复杂。
# 操作系统上的缓存
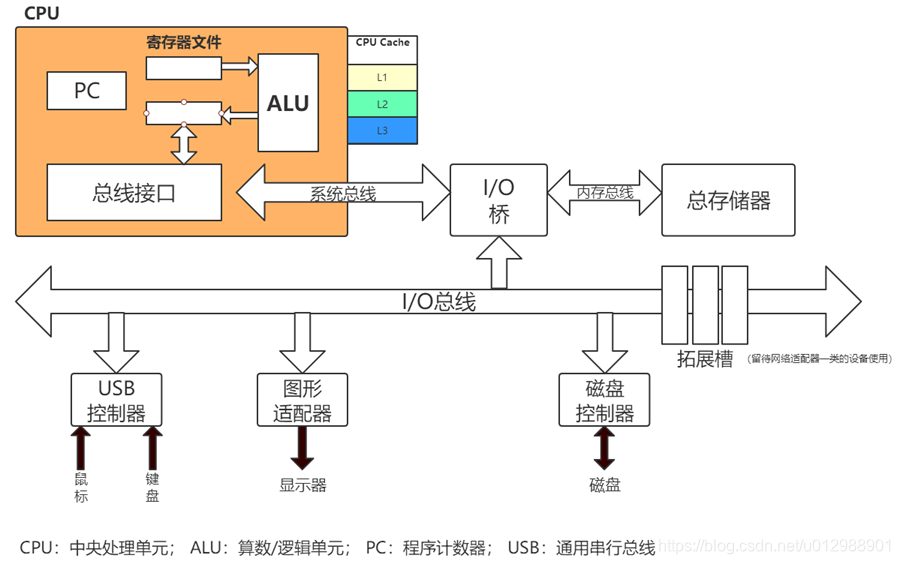
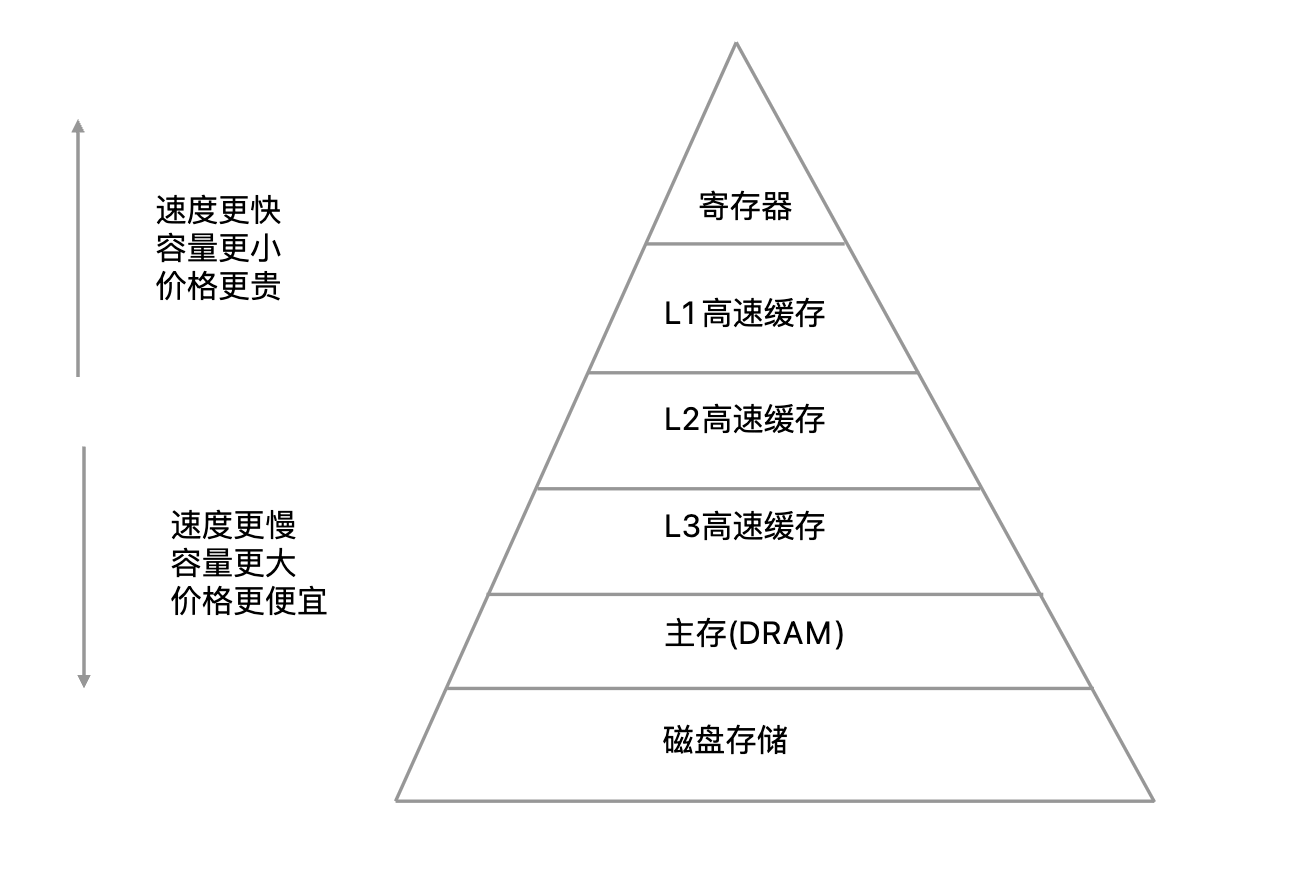
从单机机器来看,操作系统上的多级缓存层次通常包括四级缓存:寄存器、CPU高速缓存、主存(DRAM)、磁盘存储。每一层于下一层相比都拥有较高的速度和较低延迟性,以及较小的容量
寄存器:寄存器是位于CPU内部的缓存,它的容量非常小,但访问速度非常快。寄存器的主要作用是存储CPU频繁使用的数据和指令,以提高CPU的运行速度。例如x86处理器共有16个寄存器。
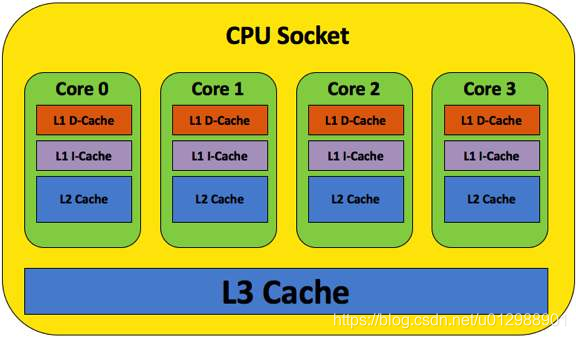
CPU高速缓存:CPU高速缓存(CPU Cache)是位于CPU和主存(RAM)之间的一种缓存,其主要作用是存储CPU频繁访问的数据和指令,以提高CPU的性能和运行速度。CPU高速缓存通常由L1、L2、L3三级缓存组成,其中L1缓存最小、速度最快,L3缓存最大、速度最慢。
CPU高速缓存的工作原理是通过在CPU和主存之间建立一层缓存,将CPU经常访问的数据和指令存储在缓存中,当CPU需要访问这些数据和指令时,可以直接从缓存中获取,而不需要每次都访问主存,从而提高了CPU的运行速度。CPU高速缓存采用了一种称为“局部性原理”的优化策略,即CPU往往会频繁访问同一块数据或指令,因此将这些数据或指令存储在高速缓存中,可以减少CPU对主存的访问次数,提高系统的性能。
第一级高速缓存(L1)–通常访问只需要几个周期,通常是几十个KB。
第二级高速缓存(L2)–比L1约有2到10倍较高延迟性,通常是几百个KB或更多。
第三级高速缓存(L3)–比L2更高的延迟性,通常有数MB之大。
L1-L3级别越小,越接近CPU,速度越快,但同时容量也越小。
如下图是CPU高速缓存的结构图:
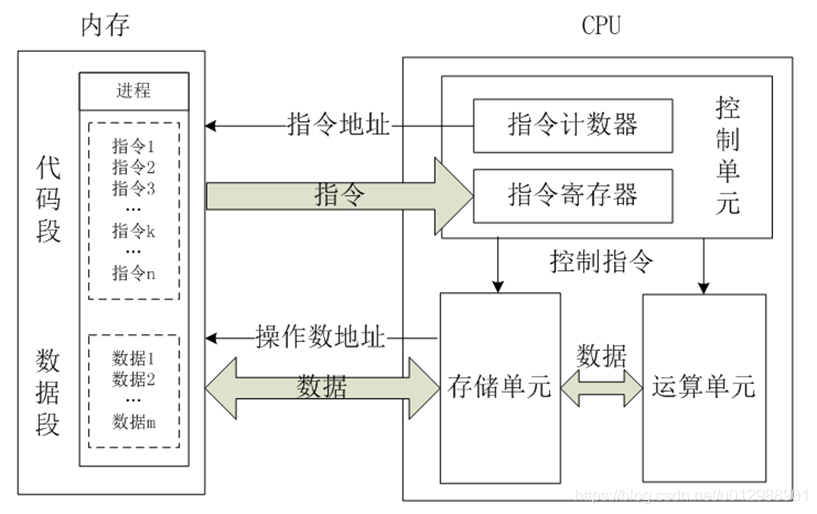
主存(DRAM):主存是位于计算机主板上的内存,容量比CPU高速缓存大,但访问速度比CPU高速缓存慢。主存的主要作用是存储程序和数据,以供CPU访问和处理。
如下图是内存和CPU之间的关系:
- 磁盘存储:是计算机中存储大量数据的设备,容量比主存大,但访问速度比磁盘缓存慢。硬盘的主要作用是存储程序、数据和操作系统等文件,以供计算机长期存储和访问。
缓存层次依次是:寄存器 -> CPU高速缓存 -> 主存(DRAM) -> 磁盘存储。
# 应用程序上的缓存
这里主要是在应用程序代码里面实现的缓存,即池化技术,主要包括:
- 线程池
- 对象池
- 连接池
详细内容不展开,具体可以看后面《池化技术》章节内容介绍。
同样的,在分布式集群环境中,也有类似的多级缓存层次。
# 分布式环境上的缓存
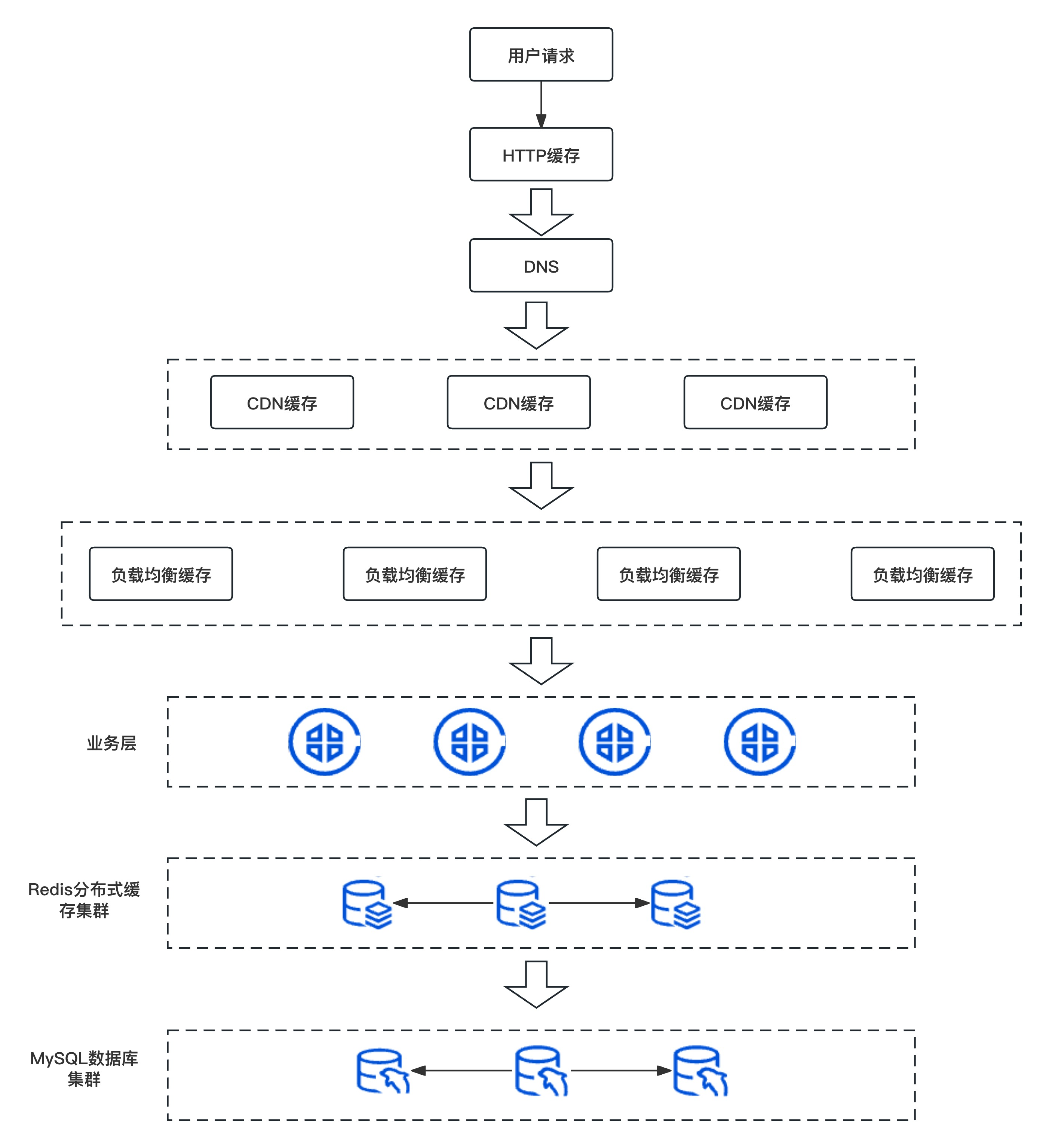
在分布式环境下,多级缓存的常见执行顺序时:HTTP缓存->CDN缓存->负载均衡缓存->Redis分布式缓存->数据库。
如果每一层的缓存查询未找到,则会向下发起请求,直到命中为止。
- HTTP缓存主要是放在浏览器上的,是最接近用户请求的缓存位置。它主要是利用HTTP头部中的各种字段(如Expires、Cache-Control、Last-Modified、ETag等)来控制缓存的行为。当浏览器第一次请求一个资源(如图片、CSS、JavaScript等)时,服务器会在响应的HTTP头部中包含一些缓存相关的信息。浏览器根据这些信息来判断资源是否可以被缓存以及缓存的有效期。当浏览器再次请求相同的资源时,如果资源已经被缓存并且缓存尚未过期,浏览器会直接从缓存中获取资源,而不会向服务器发送请求。这样可以加快页面的加载速度,减少服务器的负载。
- CDN缓存:CDN(Content Delivery Network,内容分发网络)是一种分布式网络架构。CDN通过在各地部署节点服务器,将网站的内容缓存到这些节点服务器上,用户访问时,CDN会将用户的请求转发到离用户最近的节点服务器,从而提高访问速度,减少网络延迟。
- 负载均衡缓存:负载均衡是一种将网络流量分散到多个服务器的技术,以提高网站的可用性和响应速度。负载均衡缓存是在负载均衡设备上实现的一种缓存技术,它可以缓存后端服务器的响应结果,当收到相同的请求时,直接返回缓存的结果,从而减少后端服务器的负载。
- Redis分布式缓存集群:Redis是一种基于内存的键值存储系统,它支持多种数据结构,如字符串、列表、集合、哈希表等。Redis可以用作分布式缓存,将数据保存在内存中,提供高速的读写访问。业务如果通过分布式缓存能查询命中,则直接返回结果,如果未查询到就需要从数据库访问。这样可以极大减轻数据库的压力,提高系统整体性能
- MySQL数据库集群:一般采用主从的架构实现。主从架构是一种将数据复制到多个数据库服务器的技术。在这种架构中,有一个主数据库服务器,负责处理写操作。主数据库的数据会被复制到一个或多个从数据库服务器。从数据库可以用来处理读操作,也可以作为备份,用于在主数据库出现故障时恢复数据。主从架构可以提高数据库的性能,也可以提高数据的可用性和安全性。
# 分布式缓存介绍
分布式缓存是一种缓存数据的策略,它将数据分布在多个节点上,而不是在单个节点上。这样可以提高数据的访问速度和系统的可用性。
分布式缓存的主要目标是为了提高数据读取速度,减少数据库的访问压力,提高系统的性能和可扩展性。分布式缓存通常存储频繁访问的数据,如用户会话、热点数据等。
分布式缓存的基本原理是,通过一致性哈希等算法,将数据分散存储在多个缓存节点上。当需要访问一个数据时,系统会通过哈希算法计算出该数据应该在哪个节点上,然后直接从该节点读取数据,避免了在所有节点上查找数据的开销。
常见的分布式缓存产品有Memcached、Redis、Hazelcast等。这些产品都提供了高效的数据访问机制,支持分布式部署,可以很好地满足大规模数据处理的需求。
# 读写缓存的三种模式
# Cache Aside(旁路缓存)
在这种模式下,应用程序代码负责维护缓存和数据库之间的一致性。
读操作
在读取数据时,应用程序首先会检查缓存,如果缓存中有数据,则直接返回;如果缓存中没有数据,则从数据库中读取,然后将数据放入缓存。
写操作
在写入数据时,应用程序会更新数据库并使缓存失效。
优点
- 简单易实现:应用程序直接控制缓存和数据库的读写,逻辑简单明了。
- 高命中率:在读取数据时,如果缓存失效,数据会被重新加载到缓存,从而提高缓存命中率。
缺点
- 维护成本高:应用程序需要负责维护缓存和数据库之间的一致性,增加了应用程序的复杂性。
- 数据不一致风险:在高并发环境下,如果多个线程同时更新数据库和缓存,可能导致数据不一致的问题。
# Read/Write Through(读写穿透)
在这种模式下,缓存作为数据库的前端,所有的读写操作都通过缓存进行。
读操作
在读取数据时,如果缓存中有数据,则直接返回;如果缓存中没有数据,则从数据库中读取,然后将数据放入缓存。
写操作
在写入数据时,数据同时写入缓存和数据库,以保持一致性。
优点
- 数据一致性:由于所有的读写操作都通过缓存进行,缓存和数据库之间的数据一致性得到了保证。
- 透明性:应用程序不需要关心缓存和数据库之间的一致性问题,降低了应用程序的复杂性。
缺点
- 实现复杂:需要实现缓存和数据库之间的数据同步逻辑,增加了系统的复杂性。
- 写操作性能受限:由于写操作需要同时写入缓存和数据库,写操作的性能受到数据库性能的限制。
# Write Behind Caching(异步缓存写入)
在这种模式下,写入操作首先写入缓存,然后由缓存异步地更新数据库。这种方式可以提高写入操作的速度,因为写入缓存通常比写入数据库快。但是,这种方式可能会导致数据的一致性问题,因为缓存和数据库之间的数据可能会不一致。为了解决这个问题,通常会设置一个延迟时间,如果在这个时间内,数据没有被再次修改,则将数据写入数据库。所以,这种模式比较适合写操作较多,对写操作性能要求较高的场景。
读操作
与前面两种模式类似。在读取数据时,如果缓存有数据,则直接返回;如果缓存中没有数据,则从数据库中读取,然后将数据放入缓存。
写操作
只更新缓存,然后由缓存服务异步更新数据库。
优点
- 写操作性能高:由于写操作首先写入缓存,然后异步更新数据库,写操作的性能得到了提高,因为写入缓存通常比写入数据库快。
- 减轻数据库负载:通过异步批量更新数据库,可以减轻数据库的负载。
缺点:
- 数据一致性风险:由于缓存和数据库之间的数据更新是异步的,可能导致数据不一致的问题。
- 数据丢失风险:如果缓存在数据写入数据库之前发生故障,可能导致数据丢失。为了解决这个问题,可以使用持久化策略,如Redis的AOF(Append Only File)或RDB(Redis DataBase)持久化。
# 分布式缓存常见的经典问题
# 缓存穿透
缓存穿透是指一个请求查询一个在缓存中不存在但是在数据库中存在的数据,导致每次针对这个请求都会直接访问数据库,而绕过缓存。这种情况可能会导致数据库压力增大,影响系统性能。
缓存穿透的主要原因是恶意请求或者查询不存在的数据,这样的请求无法通过缓存的存在与否来快速判断,因而直接访问数据库。
以下是一些缓解缓存穿透问题的方法:
- 布隆过滤器(Bloom Filter): 使用布隆过滤器来判断请求的数据是否存在。布隆过滤器是一种数据结构,可以快速判断一个元素是否可能在一个集合中,若可能不存在则可以直接拒绝请求,从而避免访问数据库。
- 空对象缓存: 在缓存中存储一个空对象,表示数据库中不存在对应的数据。当查询结果为空时,将这个空对象存储到缓存中,下次查询相同的数据时可以直接返回缓存中的空对象,避免再次访问数据库。
- 定期刷新缓存: 设置缓存数据的过期时间,定期刷新缓存,防止缓存中的数据过期失效。
- 异常流量监控: 监控系统中的异常流量,识别可能的恶意请求,进行限流或者封禁操作,防止缓存穿透攻击。
# 缓存雪崩
缓存雪崩是指在缓存中大量的数据同时失效或者过期,导致大量的请求直接落到数据库上,从而引起数据库负载急剧增大,影响系统性能。缓存雪崩通常发生在缓存中的多个数据同时过期或者清除,导致大量请求集中在同一时刻访问数据库。
以下是一些缓解缓存雪崩问题的方法:
- 缓存数据的过期时间随机化: 将缓存数据的过期时间设置为一个随机值,而不是统一的过期时间。这样可以避免多个缓存数据同时过期的情况,减缓缓存雪崩的发生。
- 使用分布式锁: 在缓存数据失效时,使用分布式锁来保证只有一个请求去更新缓存,其他请求等待缓存更新完成。这样可以避免多个请求同时访问数据库。
- 备份缓存: 在高峰期之前,将缓存中的数据备份到其他缓存系统或者持久化存储中。当发生缓存雪崩时,可以从备份中恢复数据,减少对数据库的直接访问。
- 多级缓存: 使用多级缓存架构,将缓存数据分布在不同的缓存层级中,降低整体缓存失效的概率。例如,可以使用本地缓存、分布式缓存和全局缓存作为多级缓存。
- 熔断机制: 实施熔断机制,当缓存失效导致数据库压力过大时,暂时拒绝一部分请求或者返回默认数据,以保护数据库免受过大的压力。
# 数据不一致
缓存一致性是指在分布式系统中,由于多个节点上存在缓存,可能导致缓存中的数据与底层数据源(通常是数据库)不一致的问题。当一个节点上的数据发生变化时,需要保证其他节点上的缓存也能及时更新,以确保整个系统的数据一致性。
通常的解决方法正如前面提到的读取缓存的三种模式:旁路缓存、读写穿透、异步缓存写入,可以根据实际的业务场景进行取舍选择。