在软件开发中,池化技术主要用于管理和优化系统资源的使用,提高软件性能和响应速度。常见的池化技术包括线程池、连接池、对象池等。这些技术通过预先创建和复用资源,避免了频繁地创建和销毁资源,从而降低了系统开销。
- 线程池:线程池用于管理和调度多线程任务,通过预先创建一定数量的线程,将这些线程放入线程池中。当有新任务到来时,从线程池中分配一个线程来执行任务,任务完成后线程返回线程池,而不是被销毁。线程池可以避免频繁地创建和销毁线程,减少系统开销,提高性能。
- 连接池:连接池用于管理和复用数据库连接。在软件中,频繁地建立和断开数据库连接会消耗大量的系统资源和时间。通过使用连接池,可以预先创建一定数量的数据库连接,并在需要时从连接池中获取连接。连接使用完毕后,将其归还到连接池而不是直接关闭。这样可以避免频繁地创建和销毁数据库连接,提高数据库访问效率。
- 对象池:对象池用于管理对象的创建和销毁。对象的创建和销毁通常需要大量的系统资源,通过对象池可以复用已有的对象,避免频繁的创建和销毁操作,提高系统性能。对象池中的对象在创建后就会一直保存在内存中,直到程序结束才会被销毁。
池化技术在软件开发中有很多应用场景,如Web服务器、数据库系统、大型分布式系统等。通过使用池化技术,可以有效地提高软件性能,降低系统资源消耗,提高资源利用率。
# 流程引擎中的应用
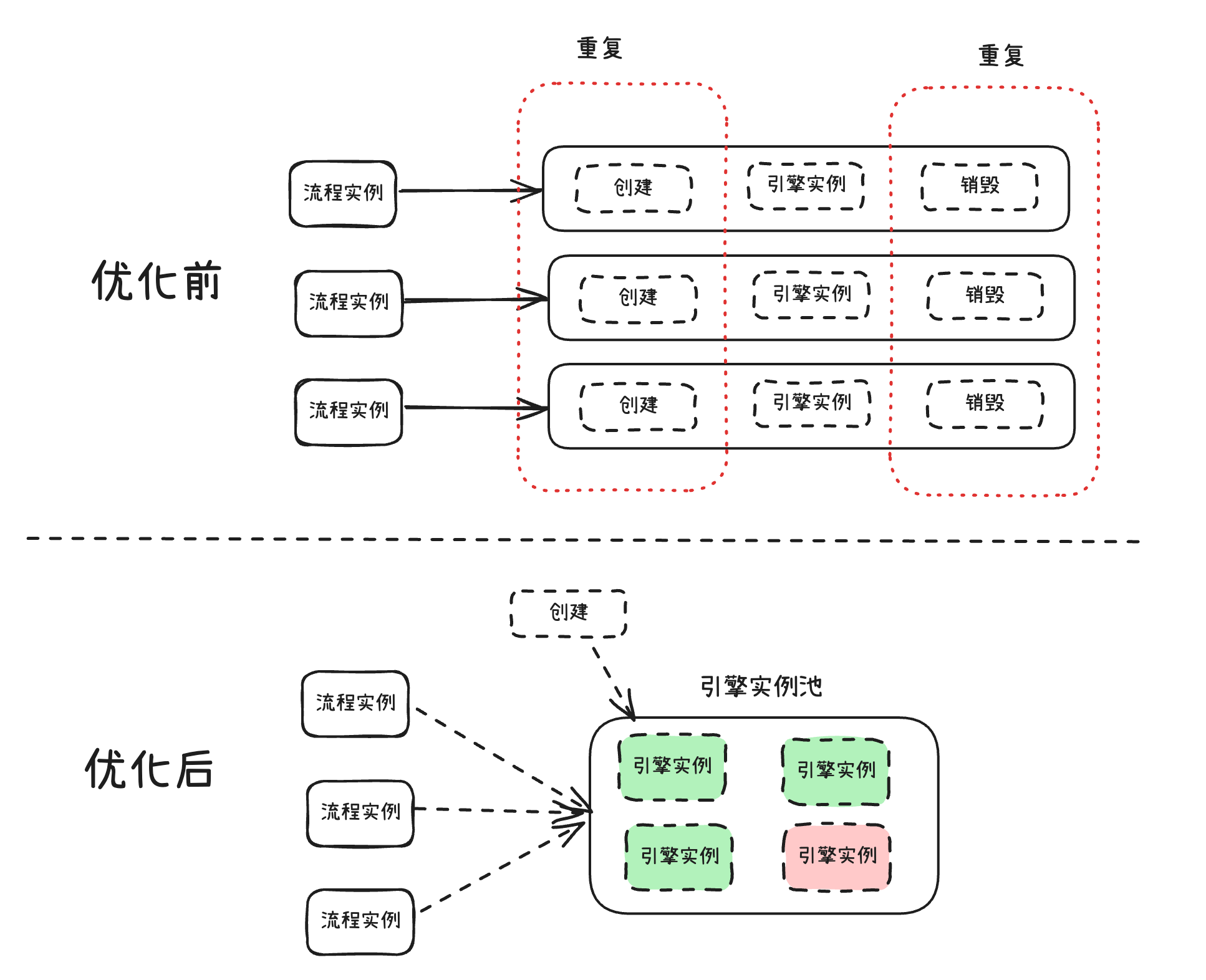
我们知道,一个流程实例(基于流程创建的实例)创建后,系统会实例化一个流程引擎实例来执行,然后执行完以后就销毁这个流程引擎实例。但是如果每次来一个流程实例,我们每次都去实例化一个流程引擎去执行,那么这里会产生很多重复性的操作(重复的实例化引擎和销毁引擎实例),导致执行效率降低。
所以这里就很有必要采用池化技术的思想,我们可以事先创建一批流程引擎实例,也就是引擎实例池,然后所有的流程实例都分发给池里空闲状态的引擎实例,这样可以避免前面重复性的创建和销毁引擎实例的动作,减少很多性能和时间上的开销。
# 线程池
# 线程池原理
线程池是一种多线程处理的设计模式,用于在程序中并发地执行多个任务。线程池的原理是通过预先创建一定数量的线程,将这些线程放入一个池(容器)中,并在需要执行任务时从池中取出线程执行。当任务执行完成后,线程会被归还到线程池中,供后续任务使用。线程池的主要优势在于减小了创建和销毁线程的开销,提高系统性能,避免了过多线程导致的资源竞争问题。
线程池的通用实现方案包括以下几个部分:
- 线程池管理器(ThreadPoolManager):负责创建、销毁和管理线程池,以及向线程池分配任务。
- 工作线程(WorkerThread):线程池中的线程,负责执行任务。工作线程在启动时会从任务队列中获取任务并执行,执行完成后再次获取任务,直到任务队列为空或线程被销毁。
- 任务队列(TaskQueue):用于存储待处理的任务。任务队列通常采用先进先出(FIFO)的数据结构,如队列(Queue)。
- 任务接口(Task):表示一个任务,包含任务的具体执行逻辑。用户需要实现任务接口,以便将任务提交给线程池执行。
线程池的工作流程如下:
- 初始化线程池:创建一个线程池管理器,预先创建一定数量的工作线程,并将这些线程放入线程池中。
- 提交任务:用户创建任务并提交给线程池管理器,线程池管理器将任务添加到任务队列中。
- 执行任务:工作线程从任务队列中获取任务并执行。如果任务队列为空,线程会进入等待状态,直到有新任务到来。
- 销毁线程池:当线程池不再需要时,线程池管理器会销毁线程池,释放资源。
线程池的实现方案有很多,例如Java中的Executor框架、Python中的concurrent.futures.ThreadPoolExecutor以及Golang中的ants第三方开源框架等。这些实现方案都遵循了线程池的基本原理,并提供了丰富的配置选项,以满足不同场景下的需求。
接下来,我们通过分析ants这个高性能的goroutine池,来深入了解线程池的实现原理。注意,由于Golang采用的是协程而不是线程的概念,所以下面的分析我们会用协程池(即goroutine池)来进行分析,其实现原理本质上跟线程池是一致的。
# ants介绍
Golang的ants框架是一个高性能且轻量级的goroutine池(Go协程池),用于管理和复用大量的goroutine,以减少系统资源的消耗和提高性能。ants框架的目标是在保持简单和易用的同时,实现对goroutine的高效调度和管理。
在Go语言中,goroutine是一种轻量级的线程,用于并发执行任务。然而,当需要处理大量并发任务时,创建大量的goroutine可能会导致内存消耗过大和调度开销增加。为了解决这个问题,ants框架提供了一个goroutine池,可以在一定程度上限制并发任务的数量,复用已经创建的goroutine,减少创建和销毁goroutine的开销。
ants框架的主要特性有:
简单易用:提供简洁的API,方便用户快速上手和使用。
高性能:通过复用goroutine,减少创建和销毁goroutine的开销,提高程序的运行效率。
动态调整:可以根据实际需求动态调整goroutine池的大小,以适应不同的工作负载。
定期清理:可以自动清理过期的goroutine,以减少资源占用。
支持多种工作模式:支持固定大小和动态大小两种goroutine池模式。
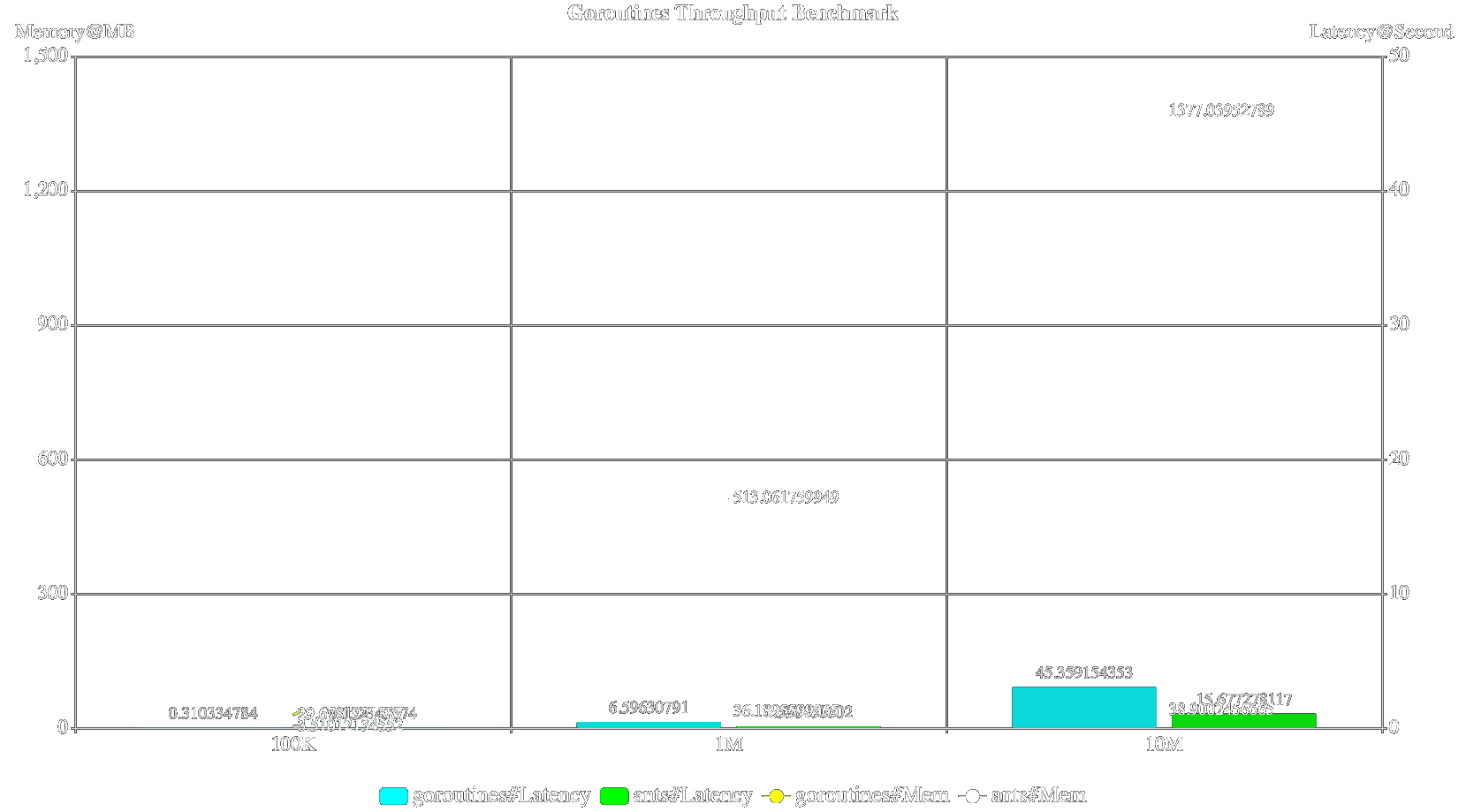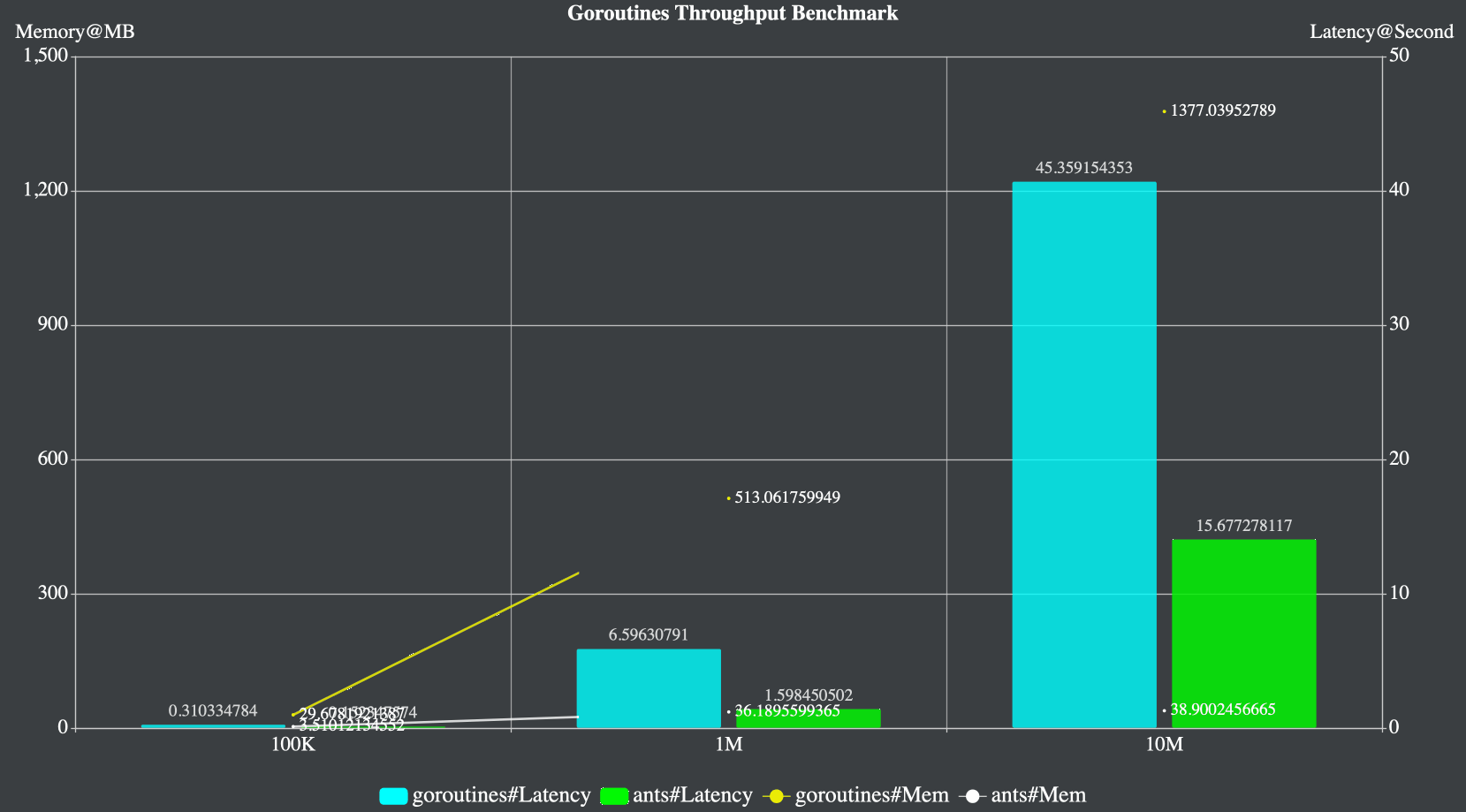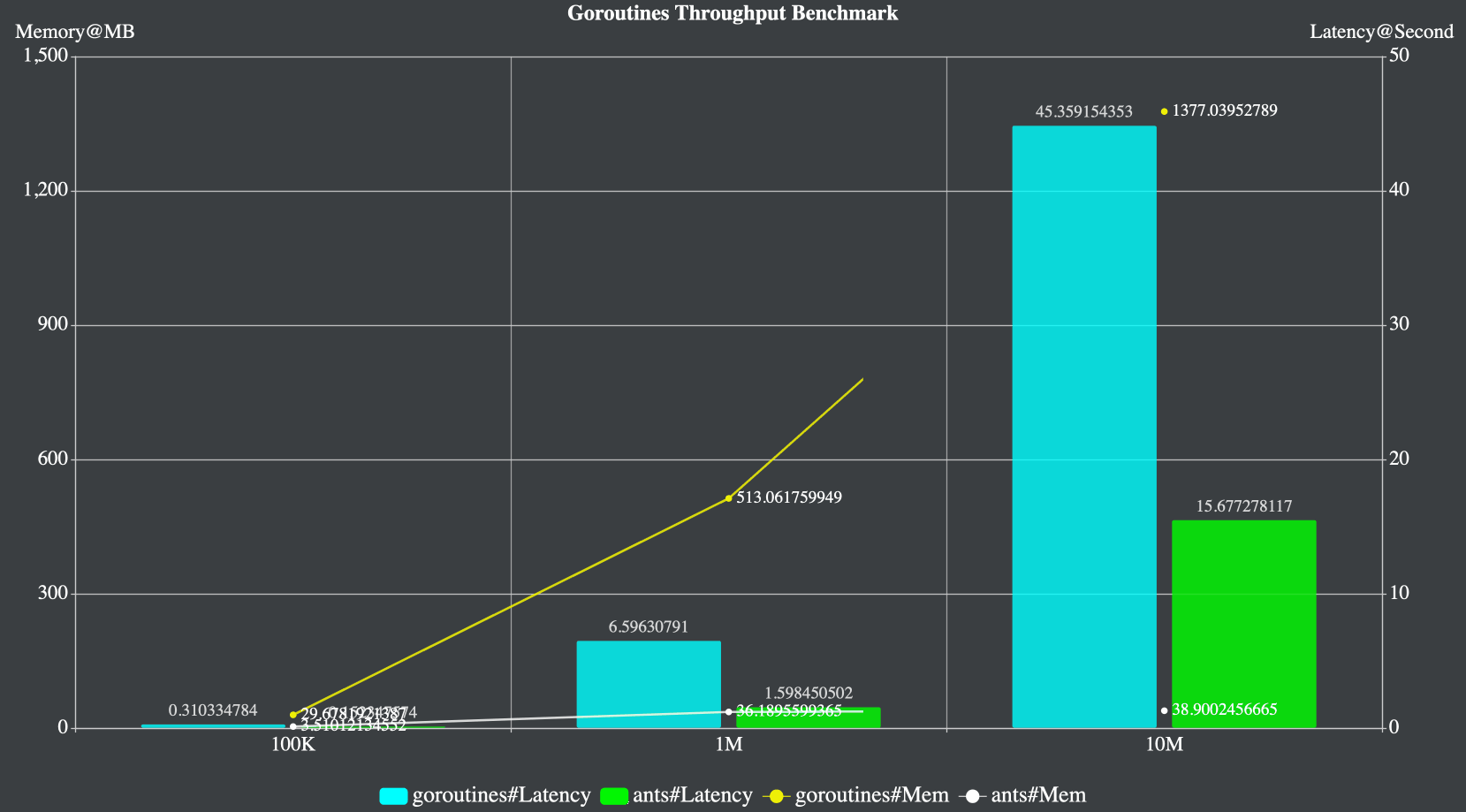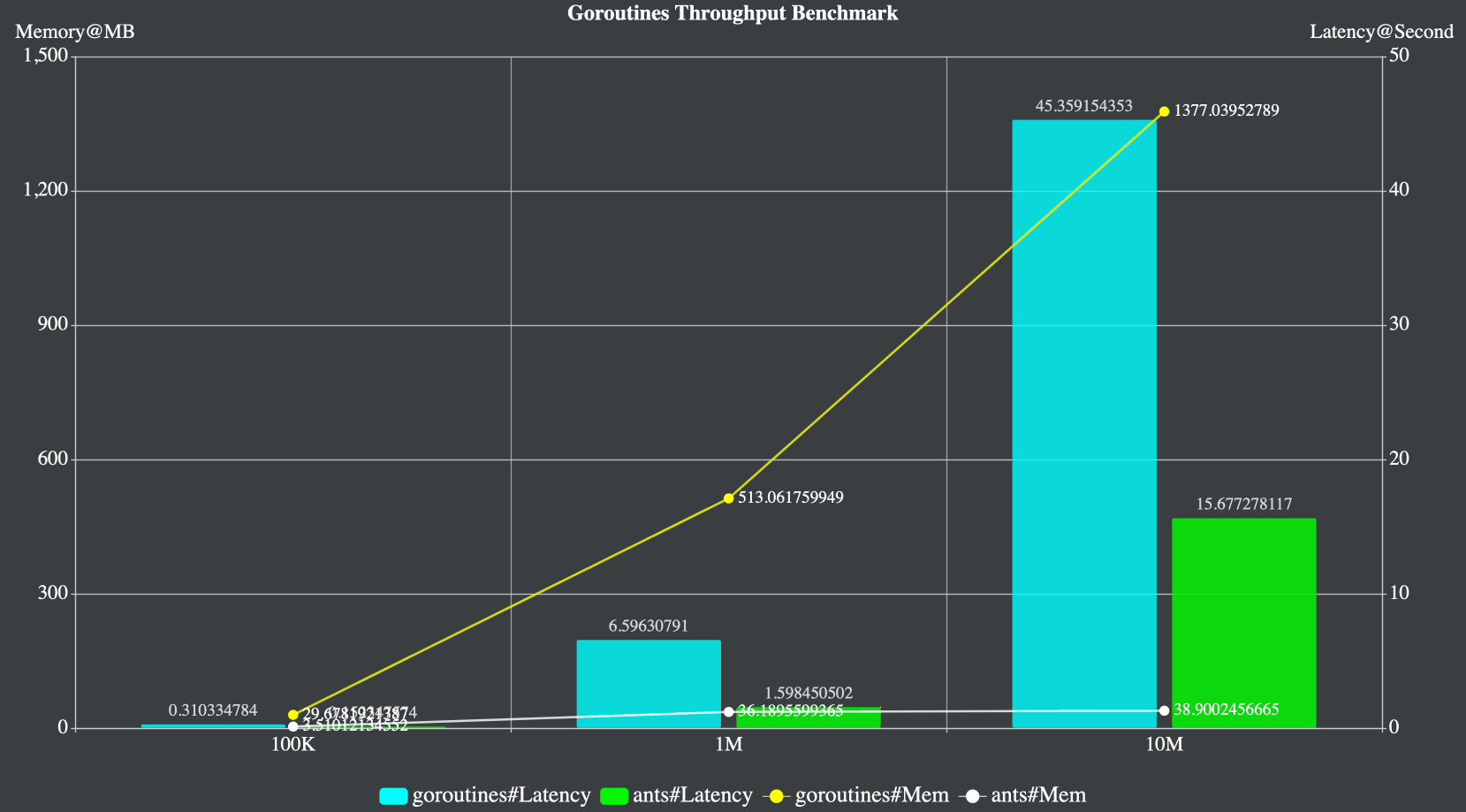
按照官方的测试数据,我们可以看到,使用ants的协程池,其性能比原生的Golang协程高2-6倍,而且对内存的消耗极低,只是原来的10到20分之一,性能非常显著。
# ants实现原理
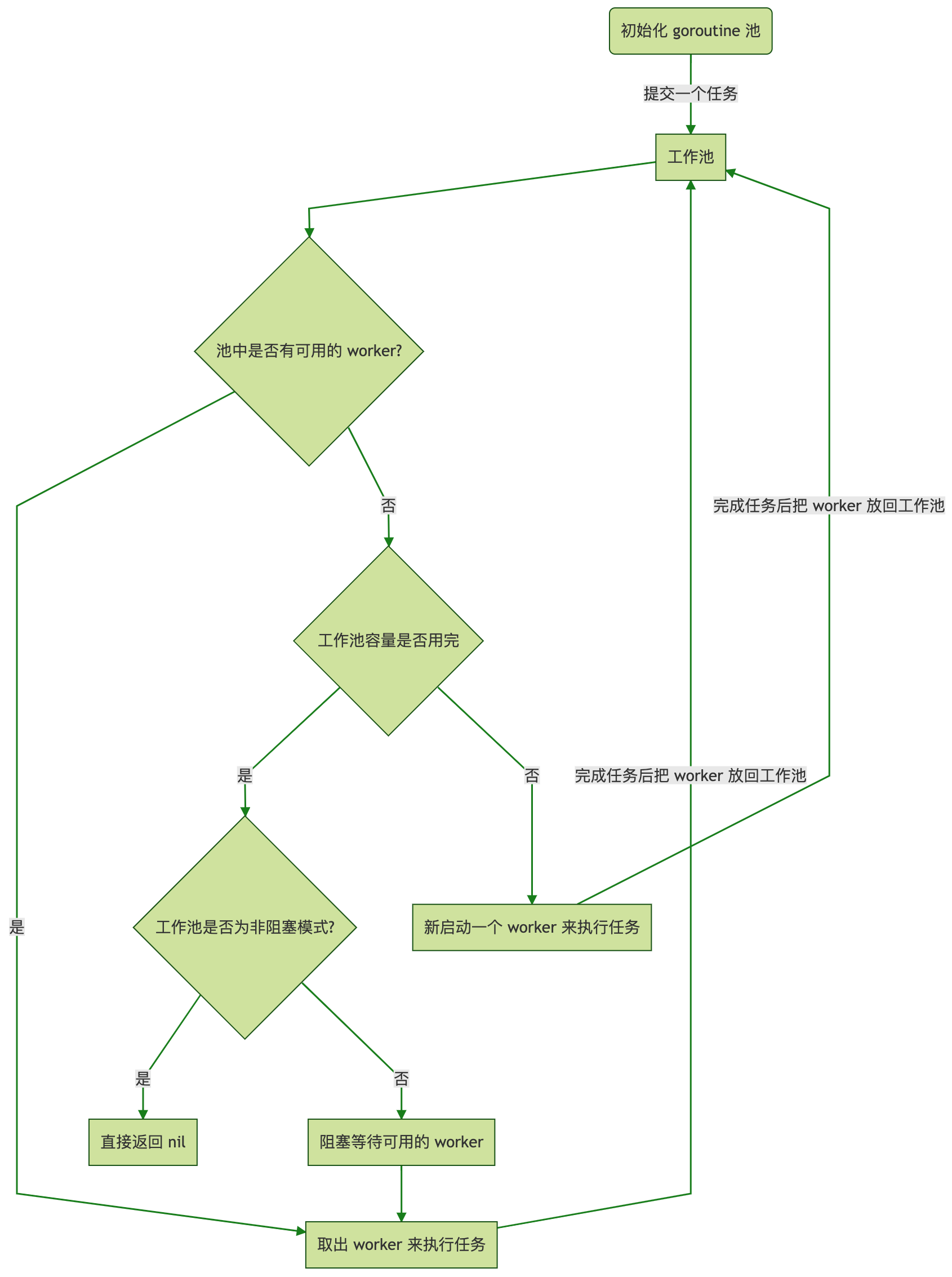
如下是ants框架官方提供的一个运行原理图:
# 使用示例
接下来我们通过一个简单的ants使用来开始深入了解它的源码实现方式。
使用ants框架时,用户只需要创建一个Pool对象,并通过Submit方法提交任务。Pool会负责调度和管理goroutine,确保任务得到高效执行。下面是一个简单的ants框架使用示例:
package main
import (
"fmt"
"sync"
"time"
"github.com/panjf2000/ants"
)
func main() {
var wg sync.WaitGroup
p, _ := ants.NewPool(10) // 创建一个大小为10的goroutine池
defer p.Release()
for i := 0; i < 100; i++ {
wg.Add(1)
_ = p.Submit(func() {
fmt.Println("Task is running...")
time.Sleep(time.Second)
wg.Done()
})
}
wg.Wait()
fmt.Println("All tasks have been completed.")
}
上面代码里,有几个ants的关键方法:
- ants.NewPool方法:初始化goroutine池
- p.Submit方法:提交任务
- p.Release方法:释放Pool
接下来,我们将分析上述几个代码的实现方式来进一步理解线程池的实现原理。
# Pool结构体
Pool的结构体用于接收任务并并发处理它们,通过复用协程来限制总协程数。结构体中的各个字段用于维护协程池的状态、可用工作协程、锁和条件变量等信息。在实际使用中,可以向该协程池提交任务,协程池会并发处理这些任务,同时保证正在运行的协程数量不超过设定的上限。
// Pool接受任务并并发处理它们,通过复用协程来限制总协程数。
type Pool struct {
// 池的容量,负值表示池的容量无限制。无限池用于避免由于池的嵌套使用导致的无限阻塞问题:
// 向池提交一个任务,该任务向同一个池提交一个新任务。
capacity int32
// 当前正在运行的协程数量。
running int32
// 保护工作队列的锁。
lock sync.Locker
// worker列表
workers workerQueue
// 用于通知池关闭自身。
state int32
// 等待空闲工作协程的条件变量。
cond *sync.Cond
// 用于加速在retrieveWorker函数中获取可用工作协程。
workerCache sync.Pool
// 已经在pool.Submit()上阻塞的协程数量,受pool.lock保护。
waiting int32
// 表示清除操作是否完成。
purgeDone int32
// 用于停止清除操作的取消函数。
stopPurge context.CancelFunc
// 表示定时操作是否完成。
ticktockDone int32
// 用于停止定时操作的取消函数。
stopTicktock context.CancelFunc
now atomic.Value
// 池的配置选项。
options *Options
}
Pool结构体的lock、cond和workerCache分别使用了Golang内置的sync.Locker、sync.Cond和sync.Pool结构体。
# sync.Locker
sync.Locker是一个接口,它定义了一个通用的锁机制,用于在多个goroutine之间同步访问共享资源。sync.Locker接口有两个方法:Lock()和Unlock()。任何实现了Lock()和Unlock()方法的类型都可以被认为是一个锁。Golang标准库sync包中的sync.Mutex和sync.RWMutex都实现了这个接口,分别表示互斥锁和读写锁。
这里ants框架自己实现了一种更轻量级的自旋锁spinLock,通过syncx.NewSpinLock()方法创建。
type Locker interface { Lock() Unlock() }
# sync.Cond
sync.Cond是Golang标准库sync包中的一个结构体,表示条件变量。它用于协调多个goroutine之间的同步操作,当一个goroutine需要等待某个条件满足时,可以使用sync.Cond等待该条件。当条件满足时,另一个goroutine可以通过sync.Cond唤醒等待的goroutine。sync.Cond有以下三个主要方法:
Wait(): 使当前goroutine等待在条件变量上,直到被唤醒。在调用Wait()之前,需要先锁定关联的互斥锁。Wait()会在进入等待前解锁互斥锁,并在被唤醒后重新锁定互斥锁。Signal(): 唤醒一个等待在条件变量上的goroutine。如果没有等待的goroutine,Signal()不会有任何效果。Broadcast(): 唤醒所有等待在条件变量上的goroutine。如果没有等待的goroutine,Broadcast()不会有任何效果。
# sync.Pool
sync.Pool是用来保存可以被重复使用的临时对象的缓存池,以便在以后的同类操作中可以重复使用,从而避免了反复创建和销毁临时对象带来的消耗以及对GC造成的压力。
sync.Pool有三个主要的方法:
New方法:对象构造函数。Get方法: 从对象池中返回一个对象,如果对象池为空,则会调用New方法创建一个新的对象。Put方法: 将一个对象放入对象池中,供后续Get方法服用。
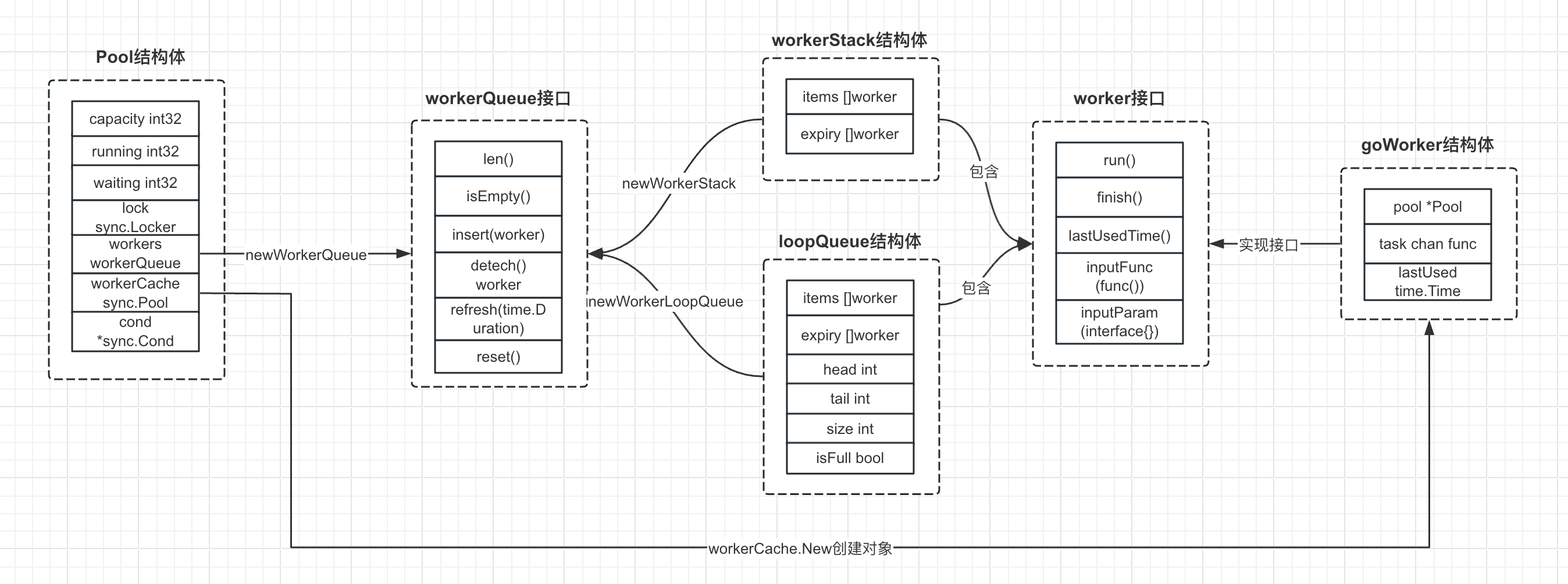
如下图所示,是ants框架中几个比较重要的结构体和接口关系图:
# NewPool方法
- 首先是创建一个Pool实例,设置goroutine池的容量,互斥锁(这里使用自旋锁实现,功能跟sync.Mutex类似,不过是轻量级的,性能更好)以及其他初始化参数。
- 设置workerCache成员的New创建对象方法,这里是基于golang内置的sync.Pool对象池实现,能加速goWorker对象的创建并减少创建开销来提高性能。
- 这里goWorker结构体是任务执行的基础单元。
- 通过队列(Queue)或栈(Stack)的方式创建workers队列。
- 创建条件变量p.cond,这里使用ants框架自定义的自旋锁作为互斥锁。
- 后台启动自动清理机制
p.goPurge()和心跳机制p.goTicktock()。
其中workerChanCap方法返回0或1,用来决定goWorker的channel是阻塞式的还是非阻塞式的。
workerChanCap = func() int {
if runtime.GOMAXPROCS(0) == 1 {
return 0
}
return 1
}()
如下是NewPool方法的关键代码:
func NewPool(size int, options ...Option) (*Pool, error) {
if size <= 0 {
size = -1
}
opts := loadOptions(options...)
if !opts.DisablePurge {
if expiry := opts.ExpiryDuration; expiry < 0 {
return nil, ErrInvalidPoolExpiry
} else if expiry == 0 {
opts.ExpiryDuration = DefaultCleanIntervalTime
}
}
if opts.Logger == nil {
opts.Logger = defaultLogger
}
// 创建一个新的池实例。
p := &Pool{
capacity: int32(size),
lock: syncx.NewSpinLock(),
options: opts,
}
// 设置workerCache,用于缓存goroutine。
p.workerCache.New = func() interface{} {
return &goWorker{
pool: p,
task: make(chan func(), workerChanCap),
}
}
// 如果预分配选项为true
if p.options.PreAlloc {
if size == -1 {
return nil, ErrInvalidPreAllocSize
}
// 创建一个指定大小的Queue实现方式的worker队列。
p.workers = newWorkerQueue(queueTypeLoopQueue, size)
} else {
// 创建一个指定大小的Stack实现方式的worker队列。
p.workers = newWorkerQueue(queueTypeStack, 0)
}
// 创建一个条件变量,用于等待可用的goroutine。
p.cond = sync.NewCond(p.lock)
// 启动自动清理和心跳检测协程。
p.goPurge()
p.goTicktock()
return p, nil
}
# ants.goWorker结构体
goWorker的结构体代表一个执行任务的工作单元。
pool *Pool:这个字段表示goWorker所属的协程池,类型是*Pool,也就是指向Pool的指针。Pool是ants库中的一个协程池结构体,包含一组可以执行任务的工作单元。task chan func():这个字段是一个函数类型的通道,它用于接收并执行任务。这个通道中的每一个元素都是一个函数,这些函数就是需要执行的任务。lastUsed time.Time:这个字段表示goWorker最后一次被使用的时间,类型是time.Time。当一个工作单元完成任务并被放回协程池时,这个值会被更新。这个字段通常用于实现空闲工作单元的清理,比如当一个工作单元长时间没有执行任务时,协程池可能会选择将其回收以节省资源。
type goWorker struct {
pool *Pool
task chan func()
lastUsed time.Time
}
# pool.Submit方法
Submit方法用于向goroutine池提交一个任务。这个任务是一个没有参数也没有返回值的函数,通常表示一个可以并发执行的任务。
- 在
Submit方法中,首先检查goroutine池是否已经关闭,如果已经关闭,则返回一个错误ErrPoolClosed。 - 如果goroutine池没有关闭,那么就尝试通过retrieveWorker方法获取一个工作单元(worker),这个工作单元是一个可以执行任务的goroutine。
- 如果成功获取到工作单元,那么就将任务传递给工作单元执行。
需要注意的是,Submit方法可能会阻塞。当goroutine池的容量已满,也就是说,所有的工作单元都在忙碌,没有空闲的工作单元可以执行新的任务时,Submit方法会阻塞,直到有工作单元变得空闲。如果你希望Submit方法在这种情况下不阻塞,而是立即返回一个错误,那么可以在创建Pool时,使用ants.WithNonblocking(true)选项。
func (p *Pool) Submit(task func()) error {
if p.IsClosed() {
return ErrPoolClosed
}
w, err := p.retrieveWorker()
if w != nil {
w.inputFunc(task)
}
return err
}
# p.pretrieveWorker方法
retrieveWorker方法是获取一个可用的工作单元的方法。
- 首先通过
p.lock.Lock()互斥锁保证协程并发安全,保证每次只有一个goroutine操作,并在结束函数调用时解锁p.lock.Unlock()。 - 然后尝试从
p.workers工作队列中取出一个工作单元,如果取到了就直接返回。 - 如果工作队列为空,但是池的容量还没有达到上限,那么就通过对象池的
p.workerCache.Get()方法创建一个新的工作单元并返回,然后调用goWorker的w.run()方法启动一个新的协程。 - 如果工作队列为空,并且池的容量已经达到上限,那么就根据池的模式决定是返回错误还是阻塞等待。
- 如果池是非阻塞模式,或者等待的任务数量已经达到了上限,那么就返回一个错误
ErrPoolOverload。 - 否则,就阻塞等待(通过
p.cond.Wait()等待信号),直到有工作单元变得可用。
- 如果池是非阻塞模式,或者等待的任务数量已经达到了上限,那么就返回一个错误
func (p *Pool) retrieveWorker() (w worker, err error) {
p.lock.Lock()
retry:
if w = p.workers.detach(); w != nil {
p.lock.Unlock()
return
}
if capacity := p.Cap(); capacity == -1 || capacity > p.Running() {
p.lock.Unlock()
w = p.workerCache.Get().(*goWorker)
w.run()
return
}
if p.options.Nonblocking || (p.options.MaxBlockingTasks != 0 && p.Waiting() >= p.options.MaxBlockingTasks) {
p.lock.Unlock()
return nil, ErrPoolOverload
}
p.addWaiting(1)
p.cond.Wait()
p.addWaiting(-1)
if p.IsClosed() {
p.lock.Unlock()
return nil, ErrPoolClosed
}
goto retry
}
# w.run方法
run方法是ants框架中实现任务执行的核心方法,它是ants框架中goWorker类型的一个方法,它用于启动一个新的goroutine来执行任务。每个goWorker实例表示一个工作单元,即一个可以执行任务的goroutine。
在run方法中,首先将正在运行的goroutine数量加1,然后启动一个新的goroutine。在这个新的goroutine中,会执行以下操作:
使用
defer语句确保在goroutine退出时执行一些清理工作,例如将正在运行的goroutine数量减1、将工作单元放回缓存、处理可能发生的panic,以及通过条件变量发送信号通知有可用的工作单元。使用
for循环从w.task通道中获取任务。这个通道中的每一个元素都是一个函数,表示需要执行的任务。当从通道中取到一个任务时,就执行这个任务,见f()调用。当任务执行完成后,尝试将工作单元放回工作队列
w.pool.revertWorker(w)。如果放回成功,那么继续等待下一个任务;否则,退出循环,结束goroutine。
// run starts a goroutine to repeat the process
// that performs the function calls.
func (w *goWorker) run() {
w.pool.addRunning(1)
go func() {
defer func() {
w.pool.addRunning(-1)
w.pool.workerCache.Put(w)
if p := recover(); p != nil {
if ph := w.pool.options.PanicHandler; ph != nil {
ph(p)
} else {
w.pool.options.Logger.Printf("worker exits from panic: %v\n%s\n", p, debug.Stack())
}
}
w.pool.cond.Signal()
}()
for f := range w.task {
if f == nil {
return
}
f()
if ok := w.pool.revertWorker(w); !ok {
return
}
}
}()
}
# revertWorker方法
revertWorker方法用于将一个工作单元(worker)放回到goroutine池中,以实现goroutine的复用。
在
revertWorker方法中,首先检查goroutine池的容量和当前运行的goroutine数量,如果当前运行的goroutine数量已经超过了池的容量,或者池已经关闭,那么就直接返回false,表示工作单元没有被放回到池中。如果池的容量还没有满,那么就更新工作单元的
lastUsed字段,表示这个工作单元最后一次被使用的时间。然后尝试将工作单元插入到工作队列中
p.workers。如果插入成功,那么就使用
p.cond.Signal()通知可能正在等待可用工作单元的其他goroutine,然后返回true。如果插入失败,那么就返回false。
func (p *Pool) revertWorker(worker *goWorker) bool {
if capacity := p.Cap(); (capacity > 0 && p.Running() > capacity) || p.IsClosed() {
p.cond.Broadcast()
return false
}
worker.lastUsed = p.nowTime()
p.lock.Lock()
if p.IsClosed() {
p.lock.Unlock()
return false
}
if err := p.workers.insert(worker); err != nil {
p.lock.Unlock()
return false
}
p.cond.Signal()
p.lock.Unlock()
return true
}
# pool.Release方法
Release方法用于关闭goroutine池并释放工作队列。
首先使用
atomic.CompareAndSwapInt32函数尝试将池的状态从OPENED改为CLOSED。如果改变状态成功,那么就继续后续的操作;否则,直接返回。然后,如果池有设置清理函数(
stopPurge),那么就调用这个函数来停止清理操作,并将stopPurge设置为nil。同样,也会调用
stopTicktock函数来停止定时操作,并将stopTicktock设置为nil。接着,使用
p.workers.reset()函数来清空工作队列。这个操作需要在锁的保护下进行,以确保在清空工作队列的过程中,不会有其他goroutine修改工作队列。最后,使用
p.cond.Broadcast()函数来唤醒可能正在等待可用工作单元的goroutine。这是因为,在retrieveWorker方法中,如果工作队列为空,那么goroutine会阻塞等待可用的工作单元。当关闭池时,需要唤醒这些阻塞的goroutine,防止它们无限期地等待。
func (p *Pool) Release() {
if !atomic.CompareAndSwapInt32(&p.state, OPENED, CLOSED) {
return
}
if p.stopPurge != nil {
p.stopPurge()
p.stopPurge = nil
}
p.stopTicktock()
p.stopTicktock = nil
p.lock.Lock()
p.workers.reset()
p.lock.Unlock()
p.cond.Broadcast()
}
# 连接池
# 连接池原理
连接池(Connection Pool)是一种创建和管理数据库连接的技术,主要用于提高对数据库的访问性能。当一个应用程序需要访问数据库时,从连接池中获取一个已经创建好的连接,使用完毕后再将其归还给连接池,而不是直接关闭。这种方式可以避免频繁地创建和关闭连接,从而提高系统的性能和响应速度。
连接池的实现原理:
- 初始化连接池:在连接池启动时,会根据配置参数创建一定数量的初始连接,并将这些连接存放在连接池中。这些连接被称为“空闲连接”。
- 获取连接:当应用程序需要访问数据库时,会向连接池请求一个连接。连接池会检查是否有空闲连接,如果有,则分配一个空闲连接给应用程序;如果没有空闲连接,且当前连接数未达到最大连接数,连接池会创建一个新的连接并分配给应用程序;如果已达到最大连接数,则应用程序需要等待,直到有连接被归还。
- 使用连接:应用程序获得连接后,可以进行数据库操作,如查询、插入、更新等。在使用过程中,连接池会保持与数据库的连接,直到应用程序完成操作。
- 归还连接:应用程序完成数据库操作后,需要将连接归还给连接池。连接池会将该连接标记为空闲状态,以便其他应用程序使用。
- 连接维护:连接池会定期检查空闲连接的有效性,对于无效的连接将予以关闭并创建新的连接。此外,连接池还会根据空闲连接的数量和使用情况进行动态调整,如关闭一些不再需要的空闲连接,或在高峰时期增加连接数。
- 关闭连接池:当应用程序关闭或不再需要连接池时,连接池会释放所有连接资源,并关闭与数据库的连接。
Java、Python和Golang等编程语言中都有各自的数据库连接池实现,如Java的Apache DBCP、C3P0、HikariCP和Druid;Python的SQLAlchemy、DBUtils和PooledDB;以及Golang的database/sql、sqlx和GORM。这些连接池实现提供了丰富的配置选项,支持多种数据库,并可与各种框架集成使用,以提高应用程序对数据库的访问性能。
下面我们通过分析golang的database/sql源码来了解数据库连接池的原理。
# database/sql介绍
Golang的database/sql库是Go标准库中用于与SQL数据库进行交互的库。它提供了一组通用的接口和方法,用于执行SQL查询、操作数据以及管理数据库连接。database/sql库与各种数据库驱动程序兼容,例如MySQL、PostgreSQL、SQLite等,使得在Go中使用不同类型的数据库变得非常简单。
database/sql库的主要组件包括:
DB:DB类型表示一个数据库连接池,它是与数据库进行交互的主要入口。你可以使用sql.Open()函数创建一个新的DB实例,该函数接受数据库驱动名称和数据源名称(例如连接字符串)作为参数。Tx:Tx类型表示一个数据库事务。你可以使用DB.Begin()方法开始一个新的事务,然后使用Tx实例执行查询和操作数据。在完成事务后,可以使用Tx.Commit()方法提交事务,或者使用Tx.Rollback()方法回滚事务。Stmt:Stmt类型表示一个预处理的SQL语句。你可以使用DB.Prepare()或Tx.Prepare()方法创建一个新的Stmt实例。使用预处理语句可以提高查询性能,特别是当需要多次执行相同的查询时。预处理语句还可以防止SQL注入攻击。Rows:Rows类型表示查询结果集。你可以使用DB.Query()、Tx.Query()或Stmt.Query()方法执行查询并返回一个Rows实例。然后可以使用Rows.Next()方法遍历结果集,以及使用Rows.Scan()方法将结果集中的数据赋值给变量。Result:Result类型表示执行插入、更新或删除操作的结果。你可以使用DB.Exec()、Tx.Exec()或Stmt.Exec()方法执行操作并返回一个Result实例。然后可以使用Result.RowsAffected()方法获取受影响的行数,以及使用Result.LastInsertId()方法获取插入操作的自增ID。
# database/sql实现原理
# 使用示例
如下是一个调用database/sql库进行mysql查询的操作,这里通过SetMaxOpenConns设置了连接池最大为1,但是这里有两个查询,而且第一个查询结束后没有主动关闭连接,实际运行可以发现在第二个db.Query查询时会卡主。如果第一个查询接受后使用rows.Close()主动关闭释放连接,则第二个查询就可以正常进行。
下面我们通过这里的代码来分析database/sql的连接池原理。
package main
import (
db "database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
)
func main() {
db, _ := db.Open("mysql", "root:123@/test?charset=utf8&parseTime=True&loc=Local")
db.SetMaxOpenConns(1)
rows, err := db.Query("select * from users")
if err != nil {
fmt.Println("query error")
return
}
//rows.Close()
row, _ := db.Query("select * from test")
fmt.Println(row, rows)
}
下图是database/sql的原理图:
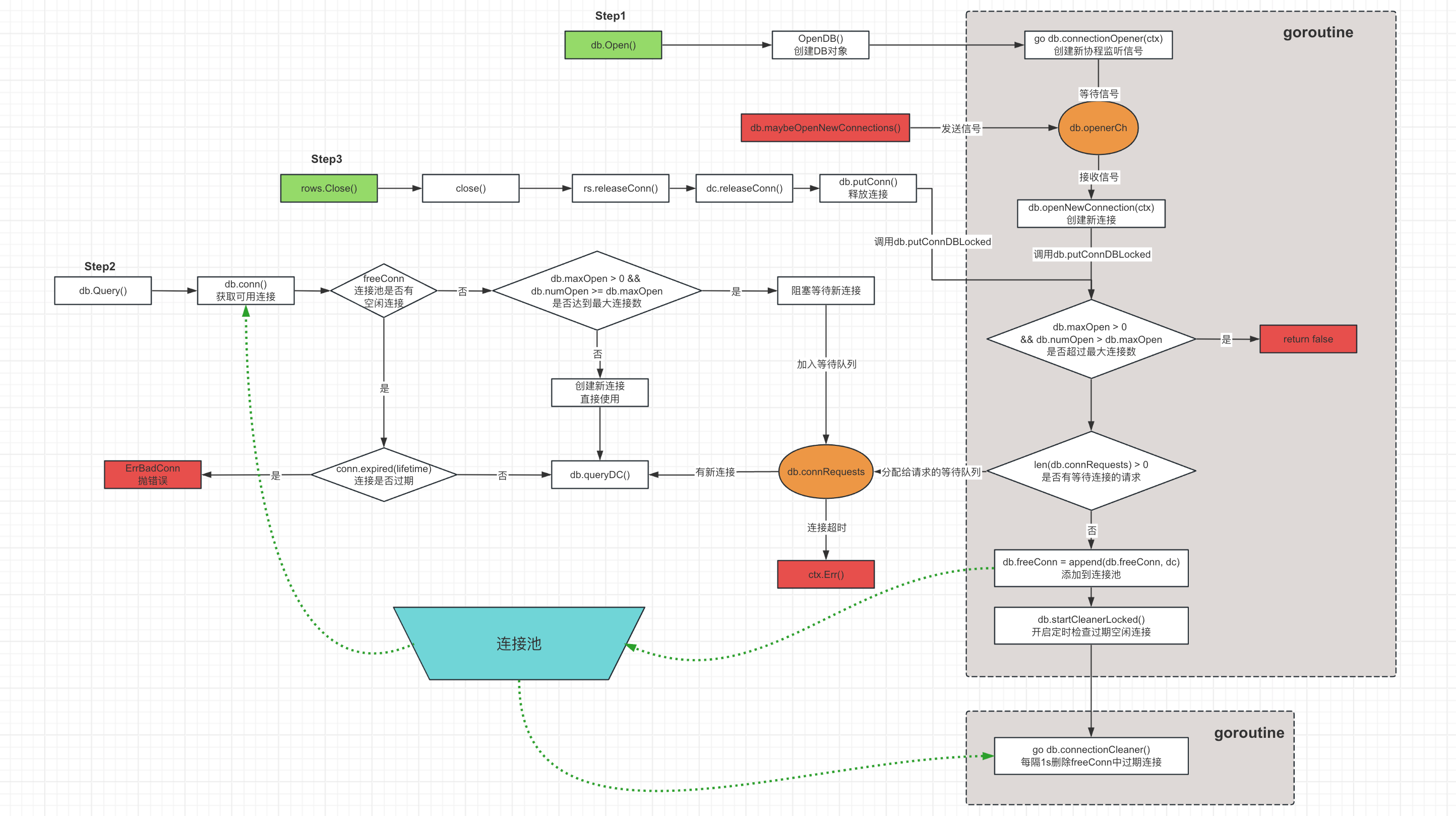
# db.Open调用链
这里,db.Open()函数主要是创建DB对象,DB类结构如下,其中有几个比较重要的成员:
- freeConn数组是一个连接池,每个连接都有一个创建时间,freeConn是按照旧到新依次排序。
- connRequests存储那些没有分配到连接的请求,这些请求会处于阻塞装填。connRequests是map结构,value是channel类型用来传递和接收信号,一旦有新的连接创建,就会通过该channel发送信号通知这些请求。
- numOpen表示已经创建了的连接数量
- maxOpen表示设置的最大连接数,一旦连接数超过maxOpen则会阻塞等待或抛异常报错,如果<=0表示没有限制。
- openerCh是一个channel类型成员,它的用来接收信号创建新的连接。这里DB对象会创建一个协程来运行
connectionOpener方法进行信号监听,一旦检测到信号则调用openNewConnection方法创建新链接。 - maxLifetime用于设置一个连接在连接池中最大的存活时间。当连接在池中存在的时间超过这个值时,连接将被关闭并从池中移除。这可以防止连接因长时间不活动而变得不稳定。设置一个合适的
maxLifetime值可以确保连接池中的连接始终是新的和稳定的 - maxIdleTime用于设置连接的最长空闲时间。当连接在池中空闲的时间超过这个值时,连接将被关闭并从池中移除。这有助于确保连接池不会因为闲置的连接而浪费资源。
type DB struct {
// Total time waited for new connections.
waitDuration atomic.Int64
connector driver.Connector
// numClosed is an atomic counter which represents a total number of
// closed connections. Stmt.openStmt checks it before cleaning closed
// connections in Stmt.css.
numClosed atomic.Uint64
mu sync.Mutex // protects following fields
freeConn []*driverConn // free connections ordered by returnedAt oldest to newest
connRequests map[uint64]chan connRequest
nextRequest uint64 // Next key to use in connRequests.
numOpen int // number of opened and pending open connections
// Used to signal the need for new connections
// a goroutine running connectionOpener() reads on this chan and
// maybeOpenNewConnections sends on the chan (one send per needed connection)
// It is closed during db.Close(). The close tells the connectionOpener
// goroutine to exit.
openerCh chan struct{}
closed bool
dep map[finalCloser]depSet
lastPut map[*driverConn]string // stacktrace of last conn's put; debug only
maxIdleCount int // zero means defaultMaxIdleConns; negative means 0
maxOpen int // <= 0 means unlimited
maxLifetime time.Duration // maximum amount of time a connection may be reused
maxIdleTime time.Duration // maximum amount of time a connection may be idle before being closed
cleanerCh chan struct{}
waitCount int64 // Total number of connections waited for.
maxIdleClosed int64 // Total number of connections closed due to idle count.
maxIdleTimeClosed int64 // Total number of connections closed due to idle time.
maxLifetimeClosed int64 // Total number of connections closed due to max connection lifetime limit.
stop func() // stop cancels the connection opener.
}
# db.Open方法
Open函数:用于打开一个数据库连接。
参数:
- driverName:数据库驱动名称,如"mysql"、"postgres"等。
- dataSourceName:数据源名称,包含了数据库连接所需的相关信息,如用户名、密码、数据库地址等。
返回值:
- *DB:一个指向DB结构体的指针,表示数据库连接。
- error:错误信息,如果成功打开连接,则为nil。
函数过程:
- 首先,获取已注册的数据库驱动(drivers)中的driverName对应的驱动(driveri)。
- 如果驱动实现了DriverContext接口,则调用OpenConnector方法创建一个连接器(connector),并使用OpenDB函数创建数据库连接。
- 如果驱动没有实现DriverContext接口,则创建一个dsnConnector结构体,并使用OpenDB函数创建数据库连接。
func Open(driverName, dataSourceName string) (*DB, error) {
driversMu.RLock()
driveri, ok := drivers[driverName]
driversMu.RUnlock()
if !ok {
return nil, fmt.Errorf("sql: unknown driver %q (forgotten import?)", driverName)
}
if driverCtx, ok := driveri.(driver.DriverContext); ok {
connector, err := driverCtx.OpenConnector(dataSourceName)
if err != nil {
return nil, err
}
return OpenDB(connector), nil
}
return OpenDB(dsnConnector{dsn: dataSourceName, driver: driveri}), nil
}
# OpenDB方法
OpenDB函数:用于根据给定的连接器(driver.Connector)创建一个数据库连接。
参数:
- c:一个实现了driver.Connector接口的连接器。
返回值:
- *DB:一个指向DB结构体的指针,表示数据库连接。
函数过程:
- 创建一个可取消的上下文(ctx)。
- 初始化一个DB结构体,包括连接器(connector)、连接请求通道(openerCh)、最后使用的连接(lastPut)、连接请求映射(connRequests)和停止函数(stop)。
- 启动一个协程,调用db.connectionOpener方法,用于处理连接请求。
- 返回DB结构体的指针。
func OpenDB(c driver.Connector) *DB {
ctx, cancel := context.WithCancel(context.Background())
db := &DB{
connector: c,
openerCh: make(chan struct{}, connectionRequestQueueSize),
lastPut: make(map[*driverConn]string),
connRequests: make(map[uint64]chan connRequest),
stop: cancel,
}
go db.connectionOpener(ctx)
return db
}
# db.connectionOpener方法
在OpenDB中创建新的goroutine协程来执行connectionOpener方法进行信号监听,db.openerCh接收到信号会调用db.openNewConnection方法创建新连接。
func (db *DB) connectionOpener(ctx context.Context) {
for {
select {
case <-ctx.Done():
return
case <-db.openerCh:
db.openNewConnection(ctx)
}
}
}
# db.openNewConnection方法
这个方法的主要功能是打开一个新的数据库连接。以下是这个方法的详细解释:
- 调用数据库连接器(db.connector)的Connect方法来创建一个新的连接(ci)。注意,在调用此方法之前,maybeOpenNewConnections方法已经将数据库的打开连接数(db.numOpen)加一。如果连接失败或在返回之前关闭,这个函数必须执行db.numOpen--。
- 获取数据库的锁(db.mu.Lock()),并在函数返回之前解锁(defer db.mu.Unlock())。
- 检查数据库是否已关闭(db.closed)。如果关闭,且连接创建成功(err == nil),则关闭新创建的连接(ci.Close()),并将打开的连接数减一(db.numOpen--)。
- 如果连接创建失败(err != nil),则将打开的连接数减一(db.numOpen--),并调用putConnDBLocked方法将错误信息传递给等待中的连接请求。然后尝试打开新的连接(db.maybeOpenNewConnections())。
- 如果连接创建成功(err == nil),则创建一个新的driverConn对象(dc),并将其与数据库关联。调用putConnDBLocked方法尝试将新创建的连接放回空闲连接池或满足一个等待中的连接请求。如果操作成功,则将新创建的连接添加到数据库的依赖关系中(db.addDepLocked(dc, dc))。否则,将打开的连接数减一(db.numOpen--),并关闭新创建的连接(ci.Close())。
func (db *DB) openNewConnection(ctx context.Context) {
ci, err := db.connector.Connect(ctx)
db.mu.Lock()
defer db.mu.Unlock()
if db.closed {
if err == nil {
ci.Close()
}
db.numOpen--
return
}
if err != nil {
db.numOpen--
db.putConnDBLocked(nil, err)
db.maybeOpenNewConnections()
return
}
dc := &driverConn{
db: db,
createdAt: nowFunc(),
returnedAt: nowFunc(),
ci: ci,
}
if db.putConnDBLocked(dc, err) {
db.addDepLocked(dc, dc)
} else {
db.numOpen--
ci.Close()
}
}
# db.putConnDBLocked方法
这个方法的主要功能是将一个数据库连接(*driverConn)放回到空闲连接池中,或者满足一个等待中的连接请求(connRequest)。以下是这个方法的详细解释:
- 检查数据库是否已关闭(db.closed)。如果是,则返回false。
- 检查当前打开的连接数(db.numOpen)是否超过了最大允许的连接数(db.maxOpen)。如果超过了,则返回false。
- 检查是否有等待中的连接请求(db.connRequests)。如果有,则从等待队列中取出一个请求,将当前的连接(dc)分配给它,并从等待队列中移除这个请求。如果分配的连接没有错误(err == nil),则将连接标记为正在使用(dc.inUse = true)。将连接和错误信息发送给请求者,然后返回true。
- 如果没有等待中的连接请求,且当前连接没有错误(err == nil)并且数据库没有关闭(!db.closed),则尝试将连接放回空闲连接池(db.freeConn)。如果空闲连接池的大小没有超过最大允许的空闲连接数(db.maxIdleConnsLocked()),则将连接添加到空闲连接池中,并启动清理程序(db.startCleanerLocked()),然后返回true。否则,将数据库的最大空闲关闭计数器(db.maxIdleClosed)加一。
- 如果以上条件都不满足,则返回false。
func (db *DB) putConnDBLocked(dc *driverConn, err error) bool f{
if db.closed {
return false
}
if db.maxOpen > 0 && db.numOpen > db.maxOpen {
return false
}
if c := len(db.connRequests); c > 0 {
var req chan connRequest
var reqKey uint64
for reqKey, req = range db.connRequests {
break
}
delete(db.connRequests, reqKey)
if err == nil {
dc.inUse = true
}
req <- connRequest{
conn: dc,
err: err,
}
return true
} else if err == nil && !db.closed {
if db.maxIdleConnsLocked() > len(db.freeConn) {
db.freeConn = append(db.freeConn, dc)
db.startCleanerLocked()
return true
}
db.maxIdleClosed++
}
return false
}
# db.Query调用链
接下来分析调用db.Query方法查询时的方法链路。
rows, err := db.Query("select * from users")
通过db.Query函数的调用,我们可以看到最终它是通过调用db.query方法实现。
# db.query()
如下可以看到query方法调用两个函数:
- db.conn:获取连接。这里的连接可能是新创建的、也可能是连接池缓存的
- db.queryDC:查询结果并返回。注意:这里使用
dc.releaseConn方法进行传参,在rows.Close()调用时会用到。
func (db *DB) query(ctx context.Context, query string, args []any, strategy connReuseStrategy) (*Rows, error) {
dc, err := db.conn(ctx, strategy)
if err != nil {
return nil, err
}
return db.queryDC(ctx, nil, dc, dc.releaseConn, query, args)
}
# db.conn方法
它的主要功能是获取一个新的或者缓存的数据库连接(*driverConn),这个方法会根据连接复用策略、当前打开的连接数和上下文等因素来决定是使用空闲连接池中的连接、等待新的连接还是创建新的连接。
以下是这个方法的详细解释:
- 获取数据库的锁(db.mu.Lock()),并检查数据库是否已关闭(db.closed)。如果关闭,则解锁并返回错误(errDBClosed)。
- 检查上下文(ctx)是否已过期。如果过期,则解锁并返回上下文错误(ctx.Err())。
- 获取数据库的最大寿命(db.maxLifetime),并尝试从空闲连接池(db.freeConn)中获取一个连接。如果连接复用策略(strategy)允许使用缓存连接且空闲连接池中有可用连接,则取出一个连接并将其标记为正在使用(conn.inUse = true)。
- 检查连接是否过期(conn.expired(lifetime))。如果过期,则更新数据库的最大寿命关闭计数器(db.maxLifetimeClosed++),解锁,并关闭连接,返回错误(driver.ErrBadConn)。
- 重置连接的会话(conn.resetSession(ctx))。如果重置失败且错误为BadConn,则关闭连接并返回错误。
- 如果当前打开的连接数(db.numOpen)超过了最大允许的连接数(db.maxOpen),则将当前的连接请求(connRequest)添加到等待队列(db.connRequests)中,并增加等待计数器(db.waitCount)。解锁数据库并等待新的连接或上下文过期。
- 如果上下文过期,则从等待队列中移除当前请求,并更新等待时长(db.waitDuration)。检查是否有新的连接返回,如果有,则将其放回连接池。
- 如果从等待队列中收到了新的连接(ret.conn),则检查连接是否过期。如果过期,则更新数据库的最大寿命关闭计数器(db.maxLifetimeClosed++),关闭连接并返回错误(driver.ErrBadConn)。
- 重置连接的会话(ret.conn.resetSession(ctx))。如果重置失败且错误为BadConn,则关闭连接并返回错误。
- 如果当前打开的连接数(db.numOpen)未超过最大允许的连接数(db.maxOpen),则创建一个新的连接(db.connector.Connect(ctx))。如果连接失败,则减少打开的连接数(db.numOpen--),尝试打开新的连接(db.maybeOpenNewConnections()),解锁数据库并返回错误。
- 创建一个新的driverConn对象(dc),将其与数据库关联,并将其标记为正在使用(dc.inUse = true)。解锁数据库并返回新的连接。
func (db *DB) conn(ctx context.Context, strategy connReuseStrategy) (*driverConn, error) {
db.mu.Lock()
if db.closed {
db.mu.Unlock()
return nil, errDBClosed
}
// 检测ctx是否过期
select {
default:
case <-ctx.Done():
db.mu.Unlock()
return nil, ctx.Err()
}
lifetime := db.maxLifetime
last := len(db.freeConn) - 1
if strategy == cachedOrNewConn && last >= 0 {
// 从连接池获取连接
conn := db.freeConn[last]
db.freeConn = db.freeConn[:last]
conn.inUse = true
// 连接过期,抛错误
if conn.expired(lifetime) {
db.maxLifetimeClosed++
db.mu.Unlock()
conn.Close()
return nil, driver.ErrBadConn
}
db.mu.Unlock()
// 重置session
if err := conn.resetSession(ctx); errors.Is(err, driver.ErrBadConn) {
conn.Close()
return nil, err
}
return conn, nil
}
// 当前连接超过设置的最大值
if db.maxOpen > 0 && db.numOpen >= db.maxOpen {
// 每个等待连接的请求通过创建nextRequestKeyLocked变量标识,
// 同时通过关联chan通道来时刻监听等待新连接创建的新号
req := make(chan connRequest, 1)
reqKey := db.nextRequestKeyLocked()
db.connRequests[reqKey] = req
db.waitCount++
db.mu.Unlock()
waitStart := nowFunc()
select {
case <-ctx.Done():
// ctx过期,移除该等待的请求
db.mu.Lock()
delete(db.connRequests, reqKey)
db.mu.Unlock()
db.waitDuration.Add(int64(time.Since(waitStart)))
// 检查是否有新的连接返回,如果有则放入连接池
select {
default:
case ret, ok := <-req:
if ok && ret.conn != nil {
db.putConn(ret.conn, ret.err, false)
}
}
return nil, ctx.Err()
case ret, ok := <-req:
// 阻塞等待,进入等待队列
db.waitDuration.Add(int64(time.Since(waitStart)))
if !ok {
return nil, errDBClosed
}
// 有新连接,但是连接已过期,抛错误
if strategy == cachedOrNewConn && ret.err == nil && ret.conn.expired(lifetime) {
db.mu.Lock()
db.maxLifetimeClosed++
db.mu.Unlock()
ret.conn.Close()
return nil, driver.ErrBadConn
}
if ret.conn == nil {
return nil, ret.err
}
// 重置session
if err := ret.conn.resetSession(ctx); errors.Is(err, driver.ErrBadConn) {
ret.conn.Close()
return nil, err
}
return ret.conn, ret.err
}
}
// 创建新的连接并立即返回
db.numOpen++
db.mu.Unlock()
ci, err := db.connector.Connect(ctx)
if err != nil {
db.mu.Lock()
db.numOpen--
db.maybeOpenNewConnections()
db.mu.Unlock()
return nil, err
}
db.mu.Lock()
dc := &driverConn{
db: db,
createdAt: nowFunc(),
returnedAt: nowFunc(),
ci: ci,
inUse: true,
}
db.addDepLocked(dc, dc)
db.mu.Unlock()
return dc, nil
}
# rows.Close调用链
前面在调用db.Query方法时,我们看到其调用的方法query通过调用如下方法并传递dc.releaseConn关闭连接方法给Rows对象。
return db.queryDC(ctx, nil, dc, dc.releaseConn, query, args)
func (db *DB) queryDC(ctx, txctx context.Context, dc *driverConn, releaseConn func(error), query string, args []any) (*Rows, error) {
...
rows := &Rows{
dc: dc,
releaseConn: releaseConn,
rowsi: rowsi,
}
...
}
所以,当我们在调用rows.Close()方法时,实际上是在调用dc.releaseConn方法,所以接下来我们研究该方法。
# dc.releaseConn方法
func (dc *driverConn) releaseConn(err error) {
dc.db.putConn(dc, err, true)
}
releaseConn方法通过调用db.putConn释放连接。
// 释放连接
func (db *DB) putConn(dc *driverConn, err error, resetSession bool) {
if !errors.Is(err, driver.ErrBadConn) {
if !dc.validateConnection(resetSession) {
err = driver.ErrBadConn
}
}
db.mu.Lock()
...
added := db.putConnDBLocked(dc, nil)
db.mu.Unlock()
...
}
putConn方法通过调用db.putConnDBLocked方法实现:
# db.putConnDBLocked方法
它的主要功能是将一个数据库连接(*driverConn)放回到空闲连接池中,或者满足一个等待中的连接请求(connRequest)。该方法返回一个布尔值,表示操作是否成功。
以下是这个方法的详细解释:
- 首先检查数据库是否已关闭(db.closed),如果是,则直接返回false。
- 然后检查当前打开的连接数(db.numOpen)是否超过了最大允许的连接数(db.maxOpen),如果超过了,则返回false。
- 接下来检查是否有等待中的连接请求(db.connRequests)。如果有,则从等待队列中取出一个请求,将当前的连接(dc)分配给它,并从等待队列中移除这个请求。如果分配的连接没有错误(err == nil),则将连接标记为正在使用(dc.inUse = true)。将连接和错误信息发送给请求者,然后返回true。
- 如果没有等待中的连接请求,且当前连接没有错误(err == nil)并且数据库没有关闭(!db.closed),则尝试将连接放回空闲连接池(db.freeConn)。如果空闲连接池的大小没有超过最大允许的空闲连接数(db.maxIdleConnsLocked()),则将连接添加到空闲连接池中,并启动清理程序(db.startCleanerLocked()),然后返回true。否则,将数据库的最大空闲关闭计数器(db.maxIdleClosed)加一。
- 如果以上条件都不满足,则返回false。
func (db *DB) putConnDBLocked(dc *driverConn, err error) bool {
// db已关闭,返回失败
if db.closed {
return false
}
// 当前连接数超过最大上限,返回失败
if db.maxOpen > 0 && db.numOpen > db.maxOpen {
return false
}
// 有等待连接的请求,把该连接返回给当前等待的请求
if c := len(db.connRequests); c > 0 {
var req chan connRequest
var reqKey uint64
for reqKey, req = range db.connRequests {
break
}
// 将当前请求从等待队列移除
delete(db.connRequests, reqKey)
if err == nil {
dc.inUse = true
}
req <- connRequest{
conn: dc,
err: err,
}
return true
} else if err == nil && !db.closed {
// 没有等待请求,则将连接放回连接池
if db.maxIdleConnsLocked() > len(db.freeConn) {
db.freeConn = append(db.freeConn, dc)
// 调用startCleanerLocked定时清理过期的连接
db.startCleanerLocked()
return true
}
db.maxIdleClosed++
}
return false
}
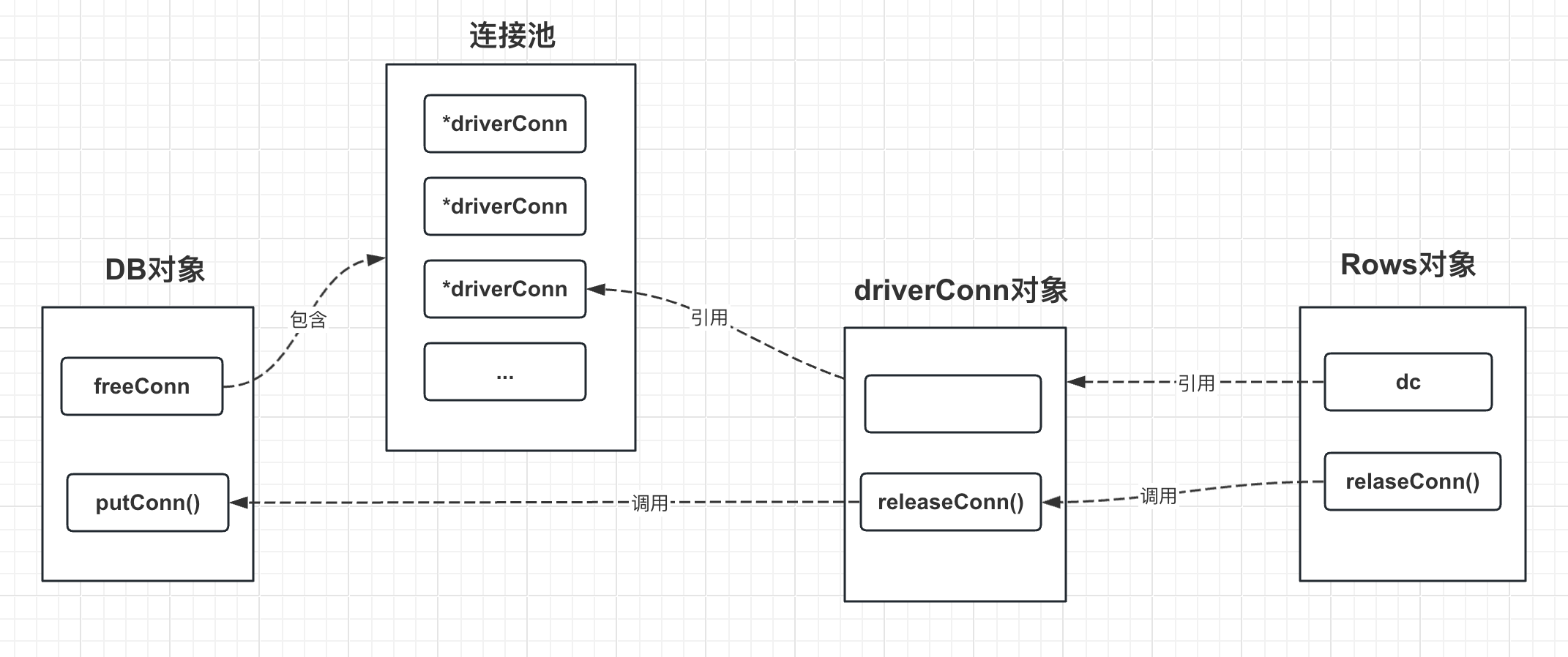
如下是DB对象、driverConn对象和Rows对象之间释放连接函数的引用关系:
# 对象池
# 对象池原理
对象池(Object Pool)是一种软件设计模式,用于预先创建并缓存一组对象,以供多个客户端共享和重复使用,而无需每次都创建和销毁对象。
对象池的实现原理通常包括以下步骤:
- 初始化:在对象池创建时,会预先创建一定数量的对象,并将它们保存在池中。
- 获取对象:当客户端需要使用对象时,会从对象池中请求一个对象。如果对象池中有空闲的对象,那么就直接返回一个;如果对象池为空,那么就创建一个新的对象并返回。在某些实现中,如果对象池已满且没有空闲对象,那么请求可能会被阻塞,直到有对象变为可用。
- 使用对象:客户端在获取对象后,可以使用它来执行各种操作。这些操作应该不会影响对象被其他客户端重复使用。
- 释放对象:当客户端完成对对象的使用后,应该将对象返回到对象池中,以便其他客户端使用。在返回对象时,可能需要进行一些清理操作,例如重置对象的状态。
- 销毁:在对象池不再需要时,应该销毁对象池,包括池中的所有对象。
对象池的主要优点是可以减少对象创建和销毁的开销,提高性能。特别是对于创建和销毁成本较高的对象,如数据库连接、线程和大型图形对象等,使用对象池可以带来显著的性能提升。
下面我们介绍Go语言中的sync.Pool对象池来进行分析。
# sync.Pool介绍
sync.Pool是Go语言中的一个对象池,用于存储和检索临时对象,以减轻垃圾收集器的压力并提高内存分配的效率。sync.Pool适用于在多个goroutine之间共享和重用的临时对象,例如缓冲区、临时变量等。sync.Pool是线程安全的,可以被多个goroutine同时使用。
sync.Pool的实现原理主要包括以下几个方面:
- 基于P (Processor)的本地缓存:sync.Pool为每个P(Go语言的调度实体)维护一个本地缓存(local pool),从而减少锁竞争。当goroutine从Pool获取或归还对象时,会优先操作与其关联的P的本地缓存。这样,即使有多个goroutine并发访问Pool,也可以保持较低的锁竞争。
- 每个P的本地缓存包含一个私有对象(private)和一个共享对象列表(shared):当goroutine需要从Pool获取对象时,首先尝试获取私有对象,如果私有对象不存在,则尝试从共享列表中获取。当归还对象时,如果私有对象为空,则将其设置为私有对象,否则将其添加到共享列表。
- 垃圾回收时的清理策略:在垃圾回收过程中,sync.Pool会自动清理其中的对象。为了尽量保留有用的对象,sync.Pool实现了一种双层缓存策略。在每次垃圾回收时,sync.Pool会将当前的本地缓存(local pool)置为“受害者”(victim),并创建新的本地缓存。在下一次垃圾回收之前,从Pool获取对象时,如果当前的本地缓存为空,会尝试从“受害者”缓存中获取。这样,在一定程度上减少了有用对象被清理的可能性。
- 可定制的构造函数:通过为Pool的New字段指定一个函数,可以在获取对象时自动创建新对象,以防Pool为空。这样,用户无需关心对象的创建过程,只需关注对象的使用和归还。需要注意的是,New函数应该是无状态的,以保证线程安全。
# sync.Pool实现原理
# 使用示例
下面是sync.Pool的简单使用方法,我们通过分析下面代码调用来了解sync.Pool的实现原理。
备注:当前源码的golang版本是v1.20.3
package main
import (
"fmt"
"sync"
)
type Obj struct {
Name string
}
// 创建一个Pool实例,指定New函数以在需要时创建新对象。
var pool = sync.Pool{
New: func() interface{} {
return new(Obj)
},
}
func main() {
// 从Pool中获取对象
obj := pool.Get().(*Obj)
obj.Name = "test123"
fmt.Println(obj)
// 使用对象完成任务后,将对象归还给Pool
pool.Put(obj)
obj2 := pool.Get().(*Obj)
fmt.Println(obj2)
}
上面的代码输出结果如下,可以看到obj2复用的是前面创建的obj的对象缓存。
&{test123}
&{test123}
# 主要结构体
下图是sync.Pool里几个比较重要的结构体关系图,下面我们将围绕sync.Pool的Get和Put操作来分析对象池的实现原理。
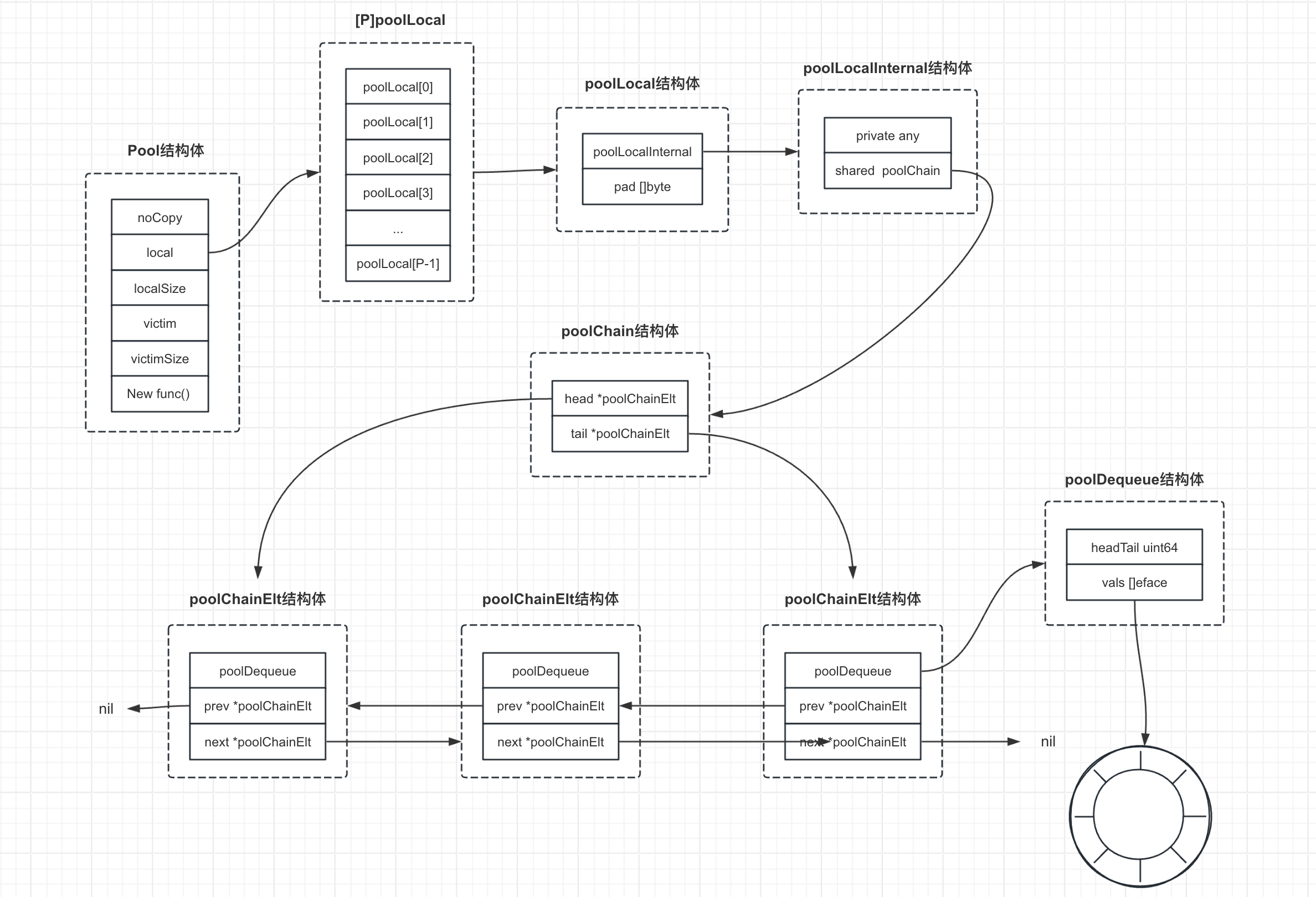
# Pool结构体
首先我们看下sync.Pool类结构
type Pool struct {
noCopy noCopy
local unsafe.Pointer
localSize uintptr
victim unsafe.Pointer
victimSize uintptr
New func() any
}
结构体的各个字段含义如下:
noCopy noCopy:这是一个空结构体,用于阻止Pool结构体被复制。在Go中,如果结构体包含一个noCopy类型的字段,则在编译时会触发一个检查,如果发现有复制操作,将产生一个编译警告。local unsafe.Pointer:这是一个指向本地缓存数组的指针,其大小为runtime.GOMAXPROCS(0)的poolLocal数组(见下面的pinSlow源码),每个P(处理器)都有一个固定大小的本地缓存,通过其ID关联一个槽位上的poolLocal。通过维护每个P的本地缓存,sync.Pool可以减少锁竞争,提高性能。localSize uintptr:这是一个无符号整数,表示本地缓存数组的大小。func (p *Pool) pinSlow() (*poolLocal, int) { ... size := runtime.GOMAXPROCS(0) local := make([]poolLocal, size) atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release runtime_StoreReluintptr(&p.localSize, uintptr(size)) // store-release return &local[pid], pid }victim unsafe.Pointer:这是一个指向上一轮垃圾回收周期中的本地缓存数组的指针。在每次垃圾回收时,当前的本地缓存会被置为“受害者”缓存,并创建新的本地缓存。这种双层缓存策略可以在一定程度上减少有用对象被清理的可能性。victimSize uintptr:这是一个无符号整数,表示“受害者”缓存数组的大小。New func() any:这是一个可选的函数,用于在Get方法返回nil时生成一个新的值。这样,用户无需关心对象的创建过程,只需关注对象的使用和归还。需要注意的是,New函数应该是无状态的,以保证线程安全。此函数在与Get方法并发调用时不可更改。
# poolLocal结构体
poolLocal结构体包含以下两个部分:
poolLocalInternal:这是一个内部结构体,用于存储与每个P(处理器)相关的本地缓存。它包含一个私有对象(private)和一个共享对象列表(shared)。见下面介绍。pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte:这是一个字节填充数组,用于防止“伪共享”(false sharing)。伪共享是指多个处理器同时访问同一个缓存行中的不同数据,导致性能下降的现象。通过在poolLocal结构体中添加填充字节,可以确保不同处理器的poolLocal结构体位于不同的缓存行中,从而避免伪共享问题。
伪共享
伪共享(False Sharing)是一种多线程程序中的性能降低现象,它发生在多个线程并发访问同一个CPU缓存行中的不同数据时。
现代计算机中,CPU不是直接从主内存中读取数据,而是先将数据加载到更接近CPU的缓存中,然后从缓存中读取数据。这是因为CPU的速度远高于主内存,直接从主内存读取数据会导致CPU大量时间等待数据,降低性能。为了提高性能,CPU会将数据按照一定大小(通常为64字节或128字节)的块,也就是“缓存行”(Cache Line),加载到缓存中。
当多个线程在同一缓存行的不同位置读写数据时,即使它们访问的是不同的数据,由于缓存系统是以缓存行为单位进行数据交换的,一个线程对缓存行的写操作会使整个缓存行失效,导致其他线程需要重新从主内存中加载数据,这就是伪共享。由于需要频繁地加载数据,伪共享会导致程序性能大幅度下降。
# poolLocalInternal结构体
poolLocalInternal结构体包含以下两个部分:
private any:这是一个私有对象,只能被对应的P(处理器)使用。当goroutine需要从Pool获取对象时,首先尝试获取这个私有对象,如果私有对象不存在,则尝试从共享列表中获取。当归还对象时,如果私有对象为空,则将其设置为私有对象。shared poolChain:这是一个共享对象列表。本地的P可以在列表头部添加或移除对象,任何P都可以从列表尾部移除对象。这是一个无锁设计的数据结构,可以有效地在多个P之间共享对象,减少锁竞争。
# poolChain结构体
poolChain结构体是poolDequeue的动态大小版本,它是一个双向链表队列,其中每个链表元素(poolDequeue)的大小是前一个元素的两倍。当一个poolDequeue填满时,poolChain会分配一个新的poolDequeue,并只将对象推送到最新的poolDequeue中。从链表的另一端弹出对象,当一个poolDequeue被耗尽时,它将从链表中移除。
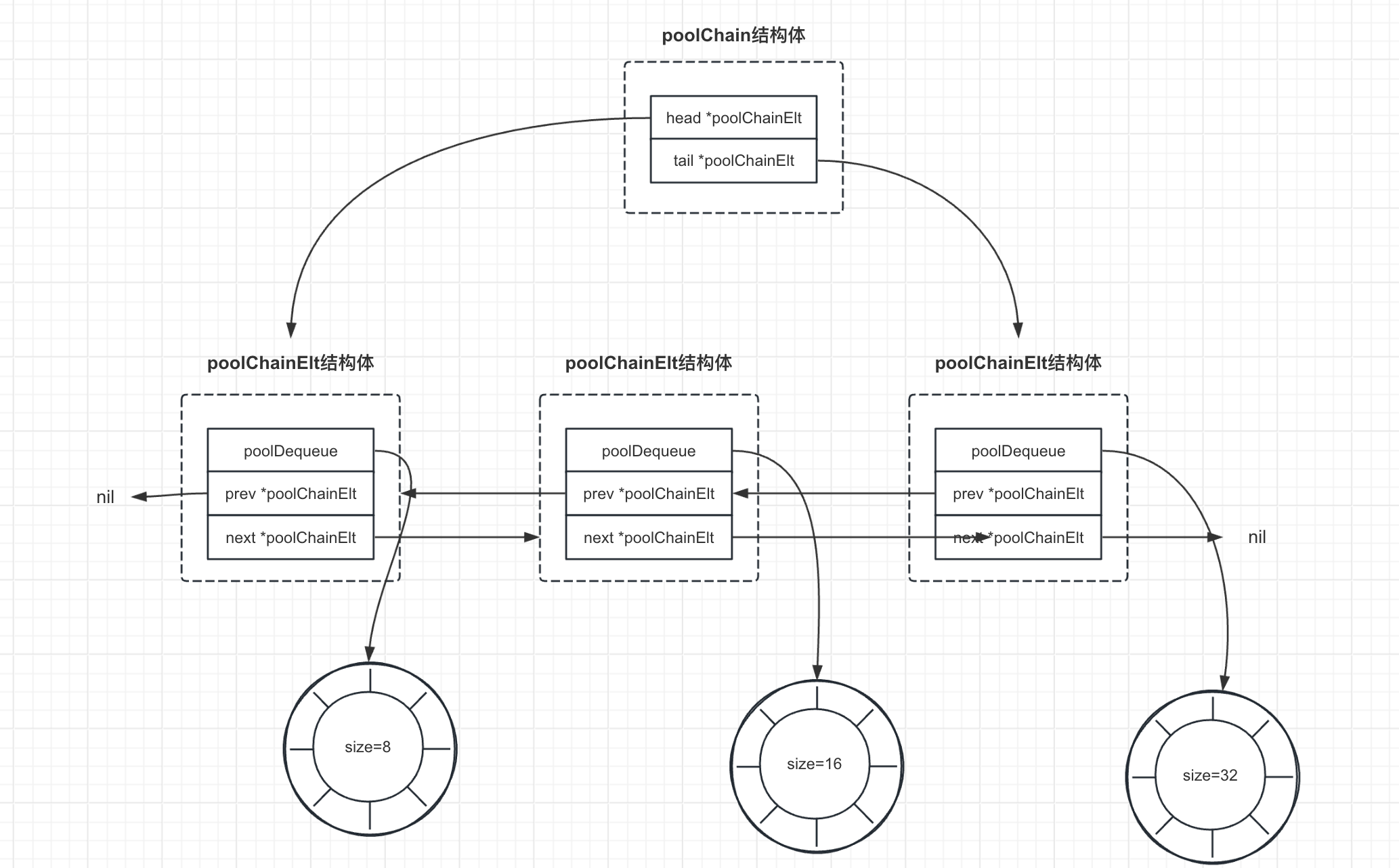
poolChain结构体包含以下两个部分:
head *poolChainElt:这是一个指向poolDequeue的指针,用于推送(push)对象。这个字段只被生产者访问,因此不需要同步。tail *poolChainElt:这是一个指向poolDequeue的指针,用于从尾部弹出(popTail)对象。这个字段会被消费者访问,因此读写操作必须是原子的。
# poolChainElt结构体
poolChainElt结构体是poolChain双向链表的元素,包含以下部分:
poolDequeue:这是一个固定大小的双端队列,用于存储对象。poolDequeue实现了无锁的push和pop操作,可以高效地在多个P之间共享对象。next, prev *poolChainElt:这是指向相邻poolChainElt的指针,用于实现poolChain的双向链表结构,如上图所示。next指针由生产者原子写入,由消费者原子读取,它只会从nil转变为非nil。prev指针由消费者原子写入,由生产者原子读取,它只会从非nil转变为nil。
# poolDequeue结构体
poolDequeue结构体是一个无锁的、固定大小的单生产者、多消费者队列。单个生产者可以从队列头部进行推送(push)和弹出(pop)操作,而消费者可以从队列尾部进行弹出操作。
poolDequeue结构体包含以下两个部分:
headTail uint64:这是一个64位整数,将32位头索引和32位尾索引打包在一起。头索引和尾索引都是模vals长度减1的索引。尾索引是队列中最旧数据的索引,头索引是下一个要填充的槽位的索引。在范围[tail, head)内的槽位由消费者拥有。消费者在将槽位设置为nil之前,仍然拥有该槽位,此时所有权才会传递给生产者。头索引存储在最高有效位中,这样我们可以原子地对其进行加法操作,溢出是无害的。vals []eface:这是一个interface{}值的环形缓冲区,存储在dequeue中。它的大小必须是2的幂。如果槽位为空,则vals[i].typ为nil,否则为非nil。一个槽位仍在使用中,直到尾索引移动到它之外,并且typ被设置为nil。消费者会原子地将其设置为nil,生产者会原子地读取它。
# sync.Get方法
在Go语言的sync.Pool中,Get()函数的主要功能是从池中选择并移除一个任意项,然后返回给调用者。如果池中没有可用的项,且Pool的New字段不为nil,则Get()会返回调用New函数的结果。
以下是Get()函数的源码分析:
func (p *Pool) Get() any {
// 如果启用了数据竞争检测,则禁用它,以防止在后续操作中产生误报。
if race.Enabled {
race.Disable()
}
// 调用pin函数获取当前P的本地缓存和ID。
l, pid := p.pin()
// 尝试获取本地缓存中的私有对象,并将私有对象设置为nil。
x := l.private
l.private = nil
// 如果私有对象为空,则尝试从本地缓存的共享列表中弹出对象。
// 如果共享列表也为空,则调用getSlow函数从其他P的本地缓存或victim缓存中获取对象。
if x == nil {
x, _ = l.shared.popHead()
if x == nil {
x = p.getSlow(pid)
}
}
// 释放当前P,允许其他goroutine使用。
runtime_procUnpin()
// 如果启用了数据竞争检测,则重新启用它,并对返回的对象进行数据竞争检测。
if race.Enabled {
race.Enable()
if x != nil {
race.Acquire(poolRaceAddr(x))
}
}
// 如果所有尝试都未能获取对象,且Pool的New字段不为nil,则调用New函数创建新对象。
if x == nil && p.New != nil {
x = p.New()
}
// 返回获取到的对象。
return x
}
# poolChain.popHead方法
func (c *poolChain) popHead() (any, bool) {
// 获取poolChain的头部元素(poolChainElt结构体)。
d := c.head
// 在一个循环中,对每个poolChainElt进行操作。
for d != nil {
// 尝试从poolChainElt的头部弹出一个元素。
if val, ok := d.popHead(); ok {
// 如果弹出成功,则返回弹出的元素和true。
return val, ok
}
// 如果poolChainElt为空,则尝试获取前一个poolChainElt。这是因为前一个poolChainElt可能仍有未被消费的元素。
d = loadPoolChainElt(&d.prev)
}
return nil, false
}
# loadPoolChainElt方法
loadPoolChainElt函数的功能是原子地加载**poolChainElt类型的指针,并返回一个*poolChainElt类型的指针。这个函数主要用于在多线程环境下安全地读取poolChainElt结构体的指针,避免数据竞争和不一致问题。
func loadPoolChainElt(pp **poolChainElt) *poolChainElt {
return (*poolChainElt)(atomic.LoadPointer((*unsafe.Pointer)(unsafe.Pointer(pp))))
}
# poolDequeue.popHead()方法
func (d *poolDequeue) popHead() (any, bool) {
// 定义一个*eface类型的变量,用于存储要弹出的元素。
var slot *eface
for {
// 原子地加载headTail的值。
ptrs := atomic.LoadUint64(&d.headTail)
// 获取head和tail索引。
head, tail := d.unpack(ptrs)
if tail == head {
// 如果队列为空,则返回nil和false。
return nil, false
}
head-- // 去除后需要将head元素移出,形成新的head索引
ptrs2 := d.pack(head, tail) // 打包新的head和tail值。
if atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2) {
// 即用新的ptrs2更新d.headTail值。
// 如果原子地更新headTail的值成功,则我们成功地重新获得了槽位。
slot = &d.vals[head&uint32(len(d.vals)-1)]
break
}
}
// 将slot转换为*any类型,并获取其值。
val := *(*any)(unsafe.Pointer(slot))
if val == dequeueNil(nil) {
// 如果val等于dequeueNil(nil),则将val设置为nil。
val = nil
}
*slot = eface{} // 将槽位清零。
return val, true // 返回弹出的值和true。
}
# Pool.getSlow方法
func (p *Pool) getSlow(pid int) any {
// 使用load-acquire模式加载p.localSize的值。
size := runtime_LoadAcquintptr(&p.localSize)
// 使用load-consume模式加载p.local的值。
locals := p.local
// 遍历所有的本地缓存。
for i := 0; i < int(size); i++ {
// 获取一个本地缓存。
l := indexLocal(locals, (pid+i+1)%int(size))
// 尝试从本地缓存的共享列表中弹出一个元素。
if x, _ := l.shared.popTail(); x != nil {
return x // 如果弹出成功,则返回弹出的元素。
}
}
// 原子地加载p.victimSize的值。
size = atomic.LoadUintptr(&p.victimSize)
// 如果当前P的ID大于或等于victimSize,则返回nil。
if uintptr(pid) >= size {
return nil
}
// 加载p.victim的值。
locals = p.victim
// 获取victim缓存中的一个本地缓存。
l := indexLocal(locals, pid)
// 尝试获取本地缓存的私有对象。
if x := l.private; x != nil {
l.private = nil
// 如果获取成功,则返回获取到的对象。
return x
}
// 遍历所有的victim本地缓存。
for i := 0; i < int(size); i++ {
// 获取一个victim本地缓存。
l := indexLocal(locals, (pid+i)%int(size))
// 尝试从victim本地缓存的共享列表中弹出一个元素。
if x, _ := l.shared.popTail(); x != nil {
// 如果弹出成功,则返回弹出的元素。
return x
}
}
// 将p.victimSize原子地设置为0,表示victim缓存为空。
atomic.StoreUintptr(&p.victimSize, 0)
// 如果所有尝试都失败,则返回nil。
return nil
}
# poolDequeue.popTail方法
代码功能如下:
popTail函数是 Golang 中sync.Pool中并发双端队列实现的一部分。- 用于移除并返回队列尾部的元素。
- 函数使用无限循环,直到成功获取插槽。
- 利用原子操作(
Load和CompareAndSwap)确保在并发环境中的线程安全性。 - 代码检查队列是否为空,如果是,则返回 false。
- 如果成功获取插槽,则从插槽中提取值,检查是否为特殊的 sentinel 值(
dequeueNil),然后通知pushHead插槽不再使用。 - 清零插槽对于避免留下可能使对象生命周期不必要延长的引用至关重要。
// popTail 移除并返回队列尾部的元素。
// 如果队列为空,则返回 false。可以被任意数量的消费者调用。
func (d *poolDequeue) popTail() (any, bool) {
// 声明一个变量来存储指向空接口的指针。
var slot *eface
// 使用无限循环重复尝试,直到操作成功。
for {
// 从原子变量加载当前头尾指针。
ptrs := d.headTail.Load()
head, tail := d.unpack(ptrs)
// 检查队列是否为空。
if tail == head {
// 队列为空。
return nil, false
}
// 确认头尾(用于上面的推测性检查)并递增尾部。如果成功,我们就拥有尾部的插槽。
ptrs2 := d.pack(head, tail+1)
if d.headTail.CompareAndSwap(ptrs, ptrs2) {
// 成功获取插槽。
slot = &d.vals[tail&uint32(len(d.vals)-1)]
break
}
}
// 我们现在拥有插槽。
val := *(*any)(unsafe.Pointer(slot))
// 检查值是否为特殊的 dequeueNil 标志。
if val == dequeueNil(nil) {
val = nil
}
// 通知 pushHead 我们已经完成对此插槽的使用。清零插槽也很重要,以防止留下可能使对象生命周期比必要更长的引用。
//
// 我们首先写入 val,然后通过原子方式写入 typ,发布我们已完成对此插槽的使用。
slot.val = nil
atomic.StorePointer(&slot.typ, nil)
// 此时,pushHead 拥有该插槽。
// 返回获取的值并指示成功。
return val, true
}
# sync.Put方法
如下是Put方法的源码:
// Put 将 x 添加到池中。
func (p *Pool) Put(x any) {
// 如果 x 为 nil,则直接返回。
if x == nil {
return
}
// 如果启用了竞态检测,以概率 1/4 随机丢弃 x,这是为了模拟竞态检测时的不确定性。。
if race.Enabled {
if runtime_randn(4) == 0 {
// 随机将 x 丢弃。
return
}
// 释放竞态检测的合并,禁用竞态检测。
race.ReleaseMerge(poolRaceAddr(x))
race.Disable()
}
// 获取锁定的 P(处理器)并返回它的本地池。
l, _ := p.pin()
// 如果本地池为空,则将 x 存储在本地池中。
if l.private == nil {
l.private = x
} else {
// 如果本地池非空,则将 x 推送到共享池的头部。
l.shared.pushHead(x)
}
// 解锁 P。
runtime_procUnpin()
// 如果启用了竞态检测,则重新启用竞态检测。
if race.Enabled {
race.Enable()
}
}
# poolChain.pushHead方法
代码功能如下:
pushHead方法用于将元素val推送到同步池链表的头部。- 如果链表为空,则初始化一个链表元素,初始大小为 8,并设置链表头部和尾部。
- 尝试将元素推送到当前链表元素的头部,如果成功则直接返回。
- 如果当前链表元素已满,则分配一个新元素,大小为当前的两倍(最大不超过
dequeueLimit)。 - 创建新的链表元素,连接到当前链表元素的前面,将新链表元素设置为链表头部。
- 将当前链表元素的下一个元素指向新创建的元素,然后将元素推送到新创建的链表元素的头部。
// pushHead 方法用于将元素 val 推送到链表头部。
func (c *poolChain) pushHead(val any) {
// 获取链表头部元素。
d := c.head
// 如果链表为空,则初始化链表。
if d == nil {
// 初始化大小为 8 的链表元素。
const initSize = 8 // 必须是2的幂
d = new(poolChainElt)
d.vals = make([]eface, initSize)
c.head = d
// 将尾部指向当前链表元素。
storePoolChainElt(&c.tail, d)
}
// 尝试将元素推送到当前链表元素的头部。
if d.pushHead(val) {
return
}
// 当前链表元素已满。分配一个大小为当前的两倍的新元素。
newSize := len(d.vals) * 2
if newSize >= dequeueLimit {
// 不能再扩大了。
newSize = dequeueLimit
}
// 创建新的链表元素,连接到当前链表元素的前面。
d2 := &poolChainElt{prev: d}
d2.vals = make([]eface, newSize)
c.head = d2
// 将当前链表元素的下一个元素指向新创建的元素。
storePoolChainElt(&d.next, d2)
// 将元素推送到新创建的链表元素的头部。
d2.pushHead(val)
}
# poolDequeue.pushHead方法
代码功能如下:
pushHead方法用于在同步池的双端队列的头部添加元素val。- 如果队列已满,则返回 false。该方法只能由单个生产者调用。
- 首先加载头尾指针。
- 检查队列是否已满,如果满则直接返回 false。
- 获取头部槽位,即队列中的第一个位置。
- 检查头部槽位是否已经被
popTail释放。如果是,则说明另一个 goroutine 仍在清理尾部,因此队列实际上仍然是满的,返回 false。 - 如果头部槽位是空闲的,将元素
val存储到槽位中,如果val为 nil,则使用特殊的dequeueNil标志。 - 增加头部指针,这样就完成了对头部的操作,并且充当了写入槽位的存储屏障。
- 操作成功,返回 true。
// pushHead 在队列头部添加元素 val。如果队列已满,则返回 false。此方法只能由单个生产者调用。
func (d *poolDequeue) pushHead(val any) bool {
// 加载头尾指针。
ptrs := d.headTail.Load()
head, tail := d.unpack(ptrs)
// 检查队列是否已满。
if (tail+uint32(len(d.vals)))&(1<<dequeueBits-1) == head {
// 队列已满。
return false
}
// 获取头部槽位。
slot := &d.vals[head&uint32(len(d.vals)-1)]
// 检查头部槽位是否已被 popTail 释放。
typ := atomic.LoadPointer(&slot.typ)
if typ != nil {
// 另一个 goroutine 仍在清理尾部,因此
// 队列实际上仍然是满的。
return false
}
// 头部槽位空闲,因此我们拥有它。
if val == nil {
val = dequeueNil(nil)
}
*(*any)(unsafe.Pointer(slot)) = val
// 增加头部。这将所有权传递给 popTail,
// 并充当写入槽位的存储屏障。
d.headTail.Add(1 << dequeueBits)
// 操作成功,返回 true。
return true
}
← 11.6 异步化技术 11.8 分布式锁 →