# 应用场景
在实际的业务场景中有很多生成唯一ID的需求,例如:订单ID、记录ID等。
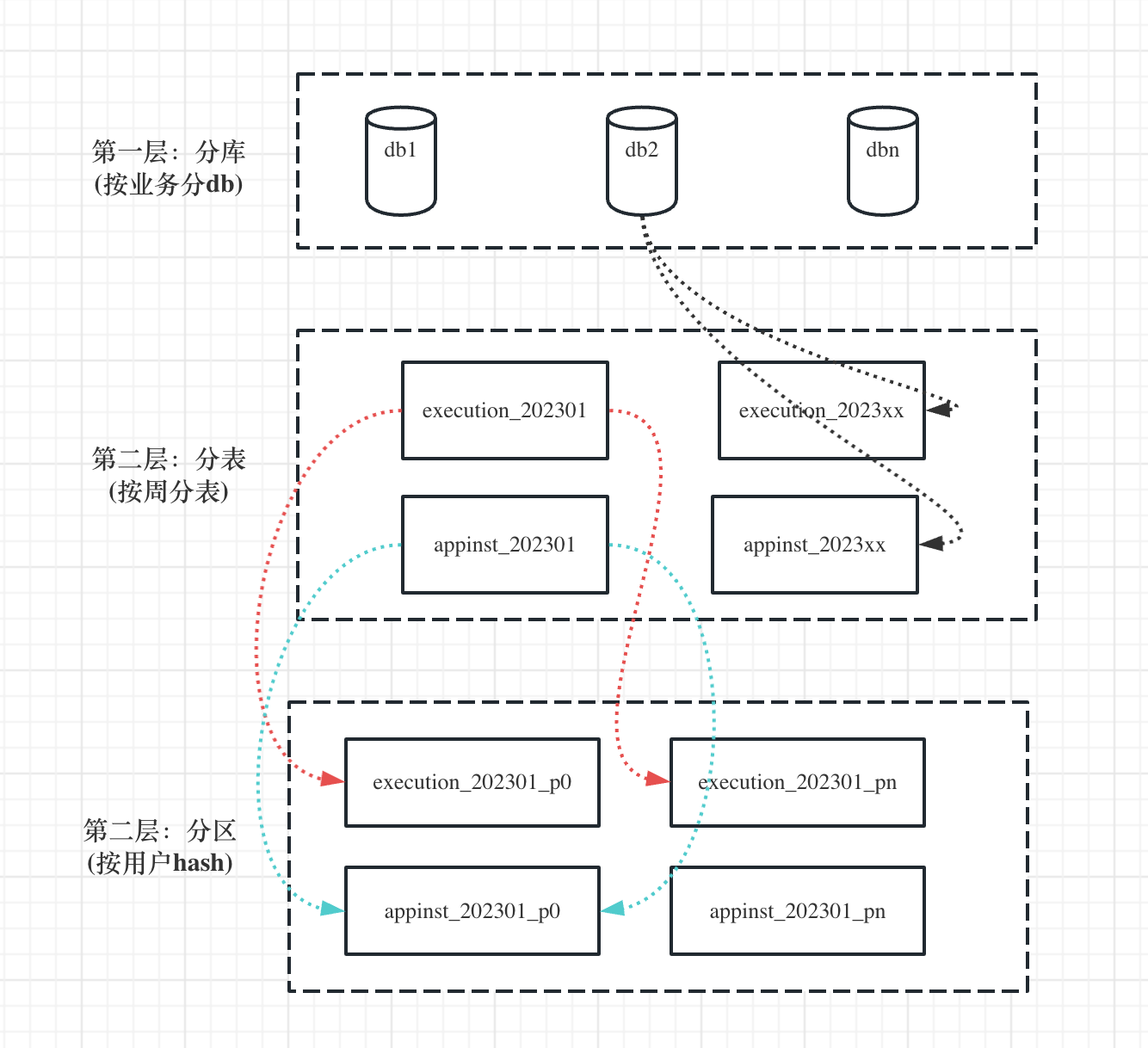
这些场景都有一个共同特点,就是业务数据量特别大,单库单表无法支持现有业务,需要进行分库分表操作。而分库分表以后就需要有一个全局唯一的ID来作为主键表示业务数据。这种情况下数据库的自增长ID就无法满足需求,需要有一个分布式唯一ID生成器。
例如工作流中的execution和appinst分表之后就不能使用自增长ID做主键,因为每个表的自增长ID是从1开始的,不同表的execution实例或appinst实例可能会出现重复的情况,这时候就需要使用分布式唯一ID来作为这些表的主键。实现即使在不同表,也可以保证execution和appinst的实例ID(分布式唯一ID)是增长趋势且唯一的。
# 特性要求
分布式唯一ID主要作为数据库的主键,所以会有以下几个要求:
全局唯一
生成速度快
ID保持时间趋势递增
这里,在使用分布式唯一ID设计MySQL主键时,通常要保证主键具有逐渐增长的趋势,这是因为:
- 逐渐增长的主键可以避免数据的碎片化,提高数据存储和查询的效率。因为数据库系统会根据主键的值将数据存储在连续的物理空间上,逐渐增长的主键有利于保持数据的连续性。
- 逐渐增长的主键可以减少索引的维护成本。当插入新数据时,逐渐增长的主键不会导致大量的索引重建,从而提高插入数据的速度。
- 逐渐增长的主键有助于避免主键冲突。因为每次插入新数据时,主键的值都会递增,这样可以确保主键的唯一性。
ID尽可能短,节省内存
# 经典的雪花算法(SnowFlake)
分布式ID生成器算法很多,其中最经典的要数Twitter开源的雪花算法。
SnowFlake算法是以划分命名空间的方式将64bit分割成4个部分,每个部分起不同的功能(实际只有63bit使用,其中1bit是符号位)。

- 第一部分:第1位占用1bit,其值始终是0,可看做是符号位不使用。
- 第二部分:第2位开始的41位是时间戳,41-bit位可表示2^41个数,每个数代表毫秒,那么雪花算法可用的时间年限是
(1L << 41)/(1000L * 60 * 60 * 24 * 365)=69 年(相对事件)的时间。这里默认计算时间是从1970年1月1日 00:00:00开始,我们可以设置时间戳计算基准点为当前时间。例如:2020年1月1日 00:00:00,则可以用到2020+69=2089年 - 第三部份:中间的10-bit位表示机器数,即2^10 = 1024台机器,但是一般情况下我们不会部署这么台机器,具体的划分可以根据自身需求定义。
- 第四部份:最后12-bit位是自增序列,可表示2^12 = 4096个数。
这样的划分之后相当于在一毫秒内一个集群的一台机器上可产生4096个有序增长的不重复的ID。但是我们机器数肯定不止一个,所以毫秒内能生成的有序增长ID数是翻倍的。
举例:snowflake ID:1541815603606036480,转换成二进制如下:
0001 0101 0110 0101 1010 0001 0001 1111 0110 0010 00 01 0111 1010 0000 0000 0000
第一部分:0
第二部分:001 0101 0110 0101 1010 0001 0001 1111 0110 0010 00 转换成十进制是:367597485448,这里假如我们采用twitter的时间戳计算基准点:1288834974657,即:2010-11-04 09:42:54。那么1288834974657+367597485448=1656432460105(1656432460.105),这个是毫秒时间戳,即2022-06-29 00:07:40这个具体时间
第三部分:01 0111 1010表示机器ID
第四部分:0000 0000 0000表示这个ID是该机器在给定毫秒时间戳里第一条处理的数据
SnowFlake算法的优点:
- 生成ID不依赖数据库,完全在内存中生成,延时低性能高
- 容量大,每秒可生成百万级别的ID
- 生成的ID是按照时间顺序趋势递增,在插入数据库索引时,速度快,性能高
SnowFlake算法的缺点:
- 依赖于各个系统时钟保持一致性。如果出现集群中某台机器系统时钟异常,可能导致生成的ID冲突后者乱序